 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Judging LLMs on a Simplex
May 28, 2025Automated evaluation of free-form outputs from large language models (LLMs) is challenging because many distinct answers can be equally valid. A common practice is to use LLMs themselves as judges, but the theoretical properties of this approach are not yet well understood. We show that a geometric framework that represents both judges and candidates as points on a probability simplex can provide helpful insight on what is or is not identifiable using LLM judges. Our theoretical analysis uncovers a "phase transition" in ranking identifiability: for binary scoring systems, true rankings are identifiable even with weak judges under mild assumptions, while rankings become non-identifiable for three or more scoring levels even with infinite data, absent additional prior knowledge. This non-identifiability highlights how uncertainty in rankings stems from not only aleatoric uncertainty (i.e., inherent stochasticity in the data) but also epistemic uncertainty regarding which assumptions hold, an aspect that has received limited attention until now. To integrate both types of uncertainty, we use Bayesian inference to encode assumptions as priors and conduct sensitivity analysis of ranking estimates and credible intervals. Empirical evaluations across multiple benchmarks demonstrate that Bayesian inference yields more accurate rankings and substantially improves coverage rates. These results underscore the importance of taking a more holistic approach to uncertainty quantification when using LLMs as judges.
Instruction-augmented Multimodal Alignment for Image-Text and Element Matching
Apr 16, 2025With the rapid advancement of text-to-image (T2I) generation models, assessing the semantic alignment between generated images and text descriptions has become a significant research challenge. Current methods, including those based on Visual Question Answering (VQA), still struggle with fine-grained assessments and precise quantification of image-text alignment. This paper presents an improved evaluation method named Instruction-augmented Multimodal Alignment for Image-Text and Element Matching (iMatch), which evaluates image-text semantic alignment by fine-tuning multimodal large language models. We introduce four innovative augmentation strategies: First, the QAlign strategy creates a precise probabilistic mapping to convert discrete scores from multimodal large language models into continuous matching scores. Second, a validation set augmentation strategy uses pseudo-labels from model predictions to expand training data, boosting the model's generalization performance. Third, an element augmentation strategy integrates element category labels to refine the model's understanding of image-text matching. Fourth, an image augmentation strategy employs techniques like random lighting to increase the model's robustness. Additionally, we propose prompt type augmentation and score perturbation strategies to further enhance the accuracy of element assessments. Our experimental results show that the iMatch method significantly surpasses existing methods, confirming its effectiveness and practical value. Furthermore, our iMatch won first place in the CVPR NTIRE 2025 Text to Image Generation Model Quality Assessment - Track 1 Image-Text Alignment.
Survey and Improvement Strategies for Gene Prioritization with Large Language Models
Jan 30, 2025


Rare diseases are challenging to diagnose due to limited patient data and genetic diversity. Despite advances in variant prioritization, many cases remain undiagnosed. While large language models (LLMs) have performed well in medical exams, their effectiveness in diagnosing rare genetic diseases has not been assessed. To identify causal genes, we benchmarked various LLMs for gene prioritization. Using multi-agent and Human Phenotype Ontology (HPO) classification, we categorized patients based on phenotypes and solvability levels. As gene set size increased, LLM performance deteriorated, so we used a divide-and-conquer strategy to break the task into smaller subsets. At baseline, GPT-4 outperformed other LLMs, achieving near 30% accuracy in ranking causal genes correctly. The multi-agent and HPO approaches helped distinguish confidently solved cases from challenging ones, highlighting the importance of known gene-phenotype associations and phenotype specificity. We found that cases with specific phenotypes or clear associations were more accurately solved. However, we observed biases toward well-studied genes and input order sensitivity, which hindered gene prioritization. Our divide-and-conquer strategy improved accuracy by overcoming these biases. By utilizing HPO classification, novel multi-agent techniques, and our LLM strategy, we improved causal gene identification accuracy compared to our baseline evaluation. This approach streamlines rare disease diagnosis, facilitates reanalysis of unsolved cases, and accelerates gene discovery, supporting the development of targeted diagnostics and therapies.
A hierarchical decomposition for explaining ML performance discrepancies
Feb 22, 2024Machine learning (ML) algorithms can often differ in performance across domains. Understanding $\textit{why}$ their performance differs is crucial for determining what types of interventions (e.g., algorithmic or operational) are most effective at closing the performance gaps. Existing methods focus on $\textit{aggregate decompositions}$ of the total performance gap into the impact of a shift in the distribution of features $p(X)$ versus the impact of a shift in the conditional distribution of the outcome $p(Y|X)$; however, such coarse explanations offer only a few options for how one can close the performance gap. $\textit{Detailed variable-level decompositions}$ that quantify the importance of each variable to each term in the aggregate decomposition can provide a much deeper understanding and suggest much more targeted interventions. However, existing methods assume knowledge of the full causal graph or make strong parametric assumptions. We introduce a nonparametric hierarchical framework that provides both aggregate and detailed decompositions for explaining why the performance of an ML algorithm differs across domains, without requiring causal knowledge. We derive debiased, computationally-efficient estimators, and statistical inference procedures for asymptotically valid confidence intervals.
A Brief Tutorial on Sample Size Calculations for Fairness Audits
Dec 07, 2023

In fairness audits, a standard objective is to detect whether a given algorithm performs substantially differently between subgroups. Properly powering the statistical analysis of such audits is crucial for obtaining informative fairness assessments, as it ensures a high probability of detecting unfairness when it exists. However, limited guidance is available on the amount of data necessary for a fairness audit, lacking directly applicable results concerning commonly used fairness metrics. Additionally, the consideration of unequal subgroup sample sizes is also missing. In this tutorial, we address these issues by providing guidance on how to determine the required subgroup sample sizes to maximize the statistical power of hypothesis tests for detecting unfairness. Our findings are applicable to audits of binary classification models and multiple fairness metrics derived as summaries of the confusion matrix. Furthermore, we discuss other aspects of audit study designs that can increase the reliability of audit results.
Towards a Post-Market Monitoring Framework for Machine Learning-based Medical Devices: A case study
Nov 20, 2023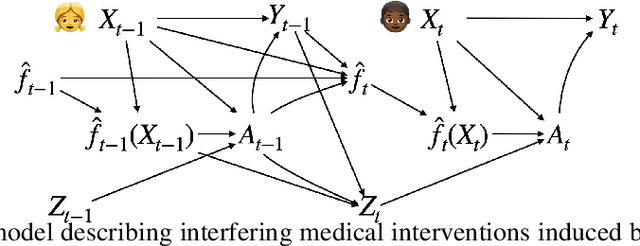
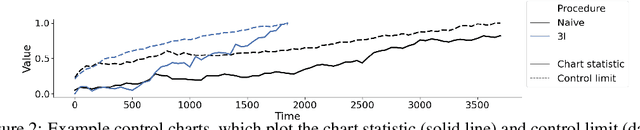
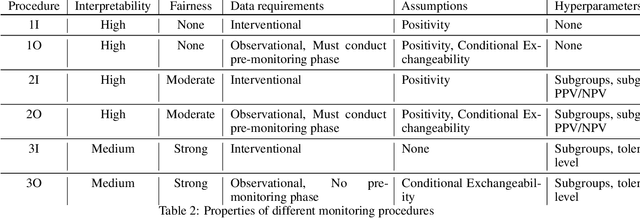
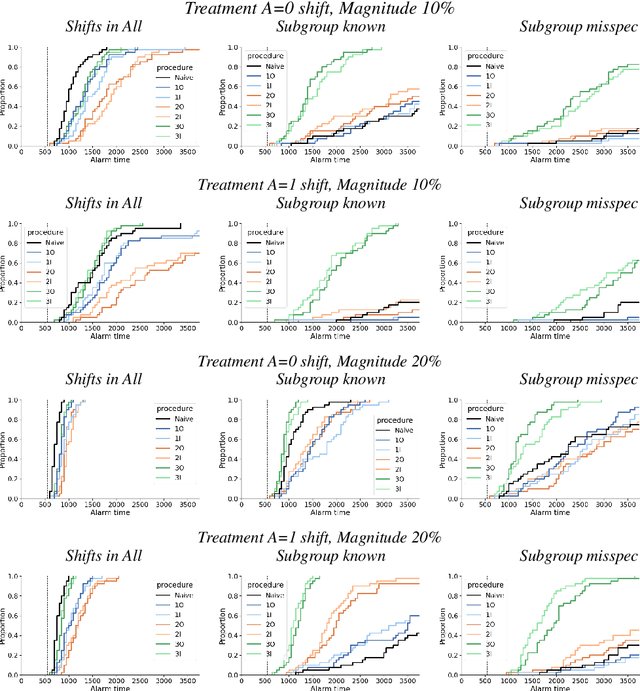
After a machine learning (ML)-based system is deployed in clinical practice, performance monitoring is important to ensure the safety and effectiveness of the algorithm over time. The goal of this work is to highlight the complexity of designing a monitoring strategy and the need for a systematic framework that compares the multitude of monitoring options. One of the main decisions is choosing between using real-world (observational) versus interventional data. Although the former is the most convenient source of monitoring data, it exhibits well-known biases, such as confounding, selection, and missingness. In fact, when the ML algorithm interacts with its environment, the algorithm itself may be a primary source of bias. On the other hand, a carefully designed interventional study that randomizes individuals can explicitly eliminate such biases, but the ethics, feasibility, and cost of such an approach must be carefully considered. Beyond the decision of the data source, monitoring strategies vary in the performance criteria they track, the interpretability of the test statistics, the strength of their assumptions, and their speed at detecting performance decay. As a first step towards developing a framework that compares the various monitoring options, we consider a case study of an ML-based risk prediction algorithm for postoperative nausea and vomiting (PONV). Bringing together tools from causal inference and statistical process control, we walk through the basic steps of defining candidate monitoring criteria, describing potential sources of bias and the causal model, and specifying and comparing candidate monitoring procedures. We hypothesize that these steps can be applied more generally, as causal inference can address other sources of biases as well.
MERTech: Instrument Playing Technique Detection Using Self-Supervised Pretrained Model With Multi-Task Finetuning
Oct 15, 2023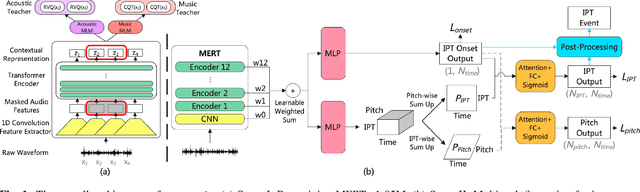
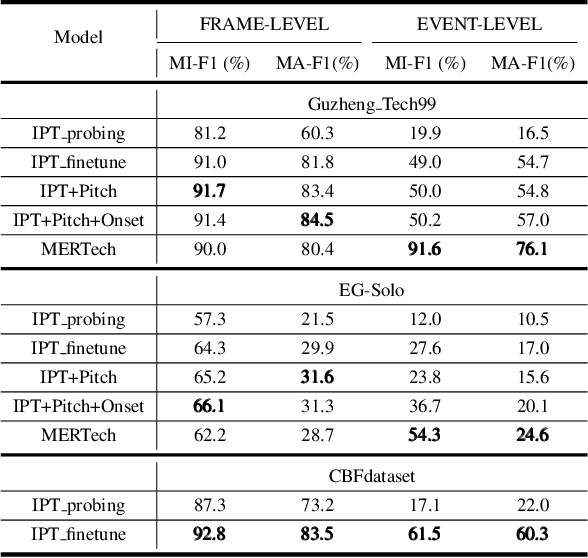
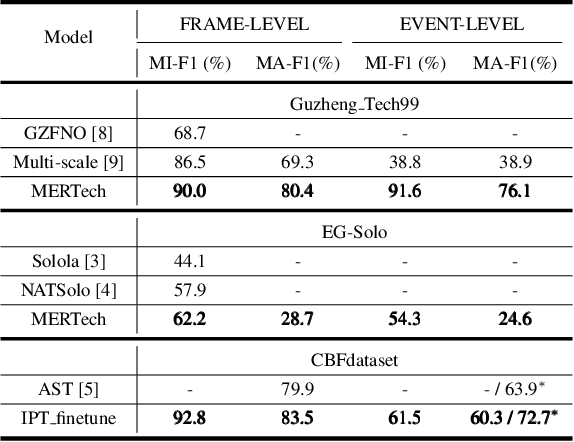
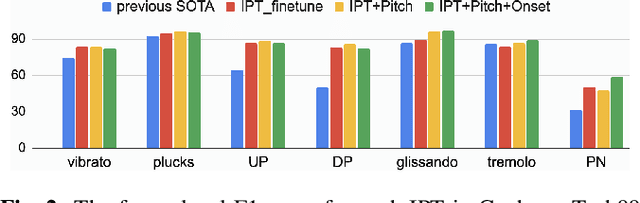
Instrument playing techniques (IPTs) constitute a pivotal component of musical expression. However, the development of automatic IPT detection methods suffers from limited labeled data and inherent class imbalance issues. In this paper, we propose to apply a self-supervised learning model pre-trained on large-scale unlabeled music data and finetune it on IPT detection tasks. This approach addresses data scarcity and class imbalance challenges. Recognizing the significance of pitch in capturing the nuances of IPTs and the importance of onset in locating IPT events, we investigate multi-task finetuning with pitch and onset detection as auxiliary tasks. Additionally, we apply a post-processing approach for event-level prediction, where an IPT activation initiates an event only if the onset output confirms an onset in that frame. Our method outperforms prior approaches in both frame-level and event-level metrics across multiple IPT benchmark datasets. Further experiments demonstrate the efficacy of multi-task finetuning on each IPT class.
Source-free Active Domain Adaptation for Diabetic Retinopathy Grading Based on Ultra-wide-field Fundus Image
Sep 19, 2023Domain adaptation (DA) has been widely applied in the diabetic retinopathy (DR) grading of unannotated ultra-wide-field (UWF) fundus images, which can transfer annotated knowledge from labeled color fundus images. However, suffering from huge domain gaps and complex real-world scenarios, the DR grading performance of most mainstream DA is far from that of clinical diagnosis. To tackle this, we propose a novel source-free active domain adaptation (SFADA) in this paper. Specifically, we focus on DR grading problem itself and propose to generate features of color fundus images with continuously evolving relationships of DRs, actively select a few valuable UWF fundus images for labeling with local representation matching, and adapt model on UWF fundus images with DR lesion prototypes. Notably, the SFADA also takes data privacy and computational efficiency into consideration. Extensive experimental results demonstrate that our proposed SFADA achieves state-of-the-art DR grading performance, increasing accuracy by 20.9% and quadratic weighted kappa by 18.63% compared with baseline and reaching 85.36% and 92.38% respectively. These investigations show that the potential of our approach for real clinical practice is promising.
Frame-Level Multi-Label Playing Technique Detection Using Multi-Scale Network and Self-Attention Mechanism
Mar 23, 2023Instrument playing technique (IPT) is a key element of musical presentation. However, most of the existing works for IPT detection only concern monophonic music signals, yet little has been done to detect IPTs in polyphonic instrumental solo pieces with overlapping IPTs or mixed IPTs. In this paper, we formulate it as a frame-level multi-label classification problem and apply it to Guzheng, a Chinese plucked string instrument. We create a new dataset, Guzheng\_Tech99, containing Guzheng recordings and onset, offset, pitch, IPT annotations of each note. Because different IPTs vary a lot in their lengths, we propose a new method to solve this problem using multi-scale network and self-attention. The multi-scale network extracts features from different scales, and the self-attention mechanism applied to the feature maps at the coarsest scale further enhances the long-range feature extraction. Our approach outperforms existing works by a large margin, indicating its effectiveness in IPT detection.