 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom User Interface to Agent Interface: Efficiency Optimization of UI Representations for LLM Agents
Dec 15, 2025
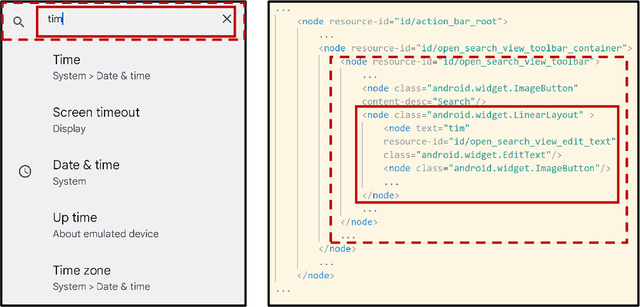
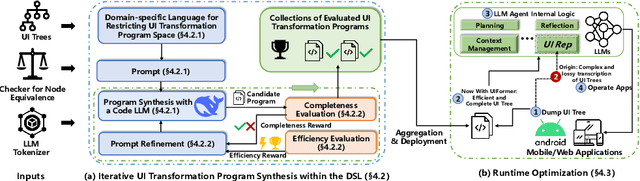
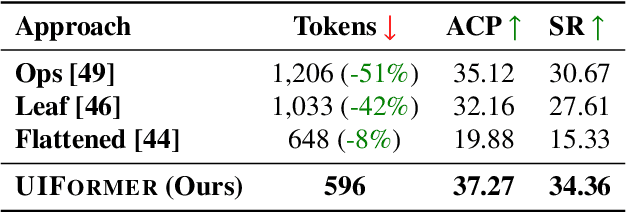
While Large Language Model (LLM) agents show great potential for automated UI navigation such as automated UI testing and AI assistants, their efficiency has been largely overlooked. Our motivating study reveals that inefficient UI representation creates a critical performance bottleneck. However, UI representation optimization, formulated as the task of automatically generating programs that transform UI representations, faces two unique challenges. First, the lack of Boolean oracles, which traditional program synthesis uses to decisively validate semantic correctness, poses a fundamental challenge to co-optimization of token efficiency and completeness. Second, the need to process large, complex UI trees as input while generating long, compositional transformation programs, making the search space vast and error-prone. Toward addressing the preceding limitations, we present UIFormer, the first automated optimization framework that synthesizes UI transformation programs by conducting constraint-based optimization with structured decomposition of the complex synthesis task. First, UIFormer restricts the program space using a domain-specific language (DSL) that captures UI-specific operations. Second, UIFormer conducts LLM-based iterative refinement with correctness and efficiency rewards, providing guidance for achieving the efficiency-completeness co-optimization. UIFormer operates as a lightweight plugin that applies transformation programs for seamless integration with existing LLM agents, requiring minimal modifications to their core logic. Evaluations across three UI navigation benchmarks spanning Android and Web platforms with five LLMs demonstrate that UIFormer achieves 48.7% to 55.8% token reduction with minimal runtime overhead while maintaining or improving agent performance. Real-world industry deployment at WeChat further validates the practical impact of UIFormer.
Instruction-augmented Multimodal Alignment for Image-Text and Element Matching
Apr 16, 2025With the rapid advancement of text-to-image (T2I) generation models, assessing the semantic alignment between generated images and text descriptions has become a significant research challenge. Current methods, including those based on Visual Question Answering (VQA), still struggle with fine-grained assessments and precise quantification of image-text alignment. This paper presents an improved evaluation method named Instruction-augmented Multimodal Alignment for Image-Text and Element Matching (iMatch), which evaluates image-text semantic alignment by fine-tuning multimodal large language models. We introduce four innovative augmentation strategies: First, the QAlign strategy creates a precise probabilistic mapping to convert discrete scores from multimodal large language models into continuous matching scores. Second, a validation set augmentation strategy uses pseudo-labels from model predictions to expand training data, boosting the model's generalization performance. Third, an element augmentation strategy integrates element category labels to refine the model's understanding of image-text matching. Fourth, an image augmentation strategy employs techniques like random lighting to increase the model's robustness. Additionally, we propose prompt type augmentation and score perturbation strategies to further enhance the accuracy of element assessments. Our experimental results show that the iMatch method significantly surpasses existing methods, confirming its effectiveness and practical value. Furthermore, our iMatch won first place in the CVPR NTIRE 2025 Text to Image Generation Model Quality Assessment - Track 1 Image-Text Alignment.
Testing Untestable Neural Machine Translation: An Industrial Case
Oct 03, 2018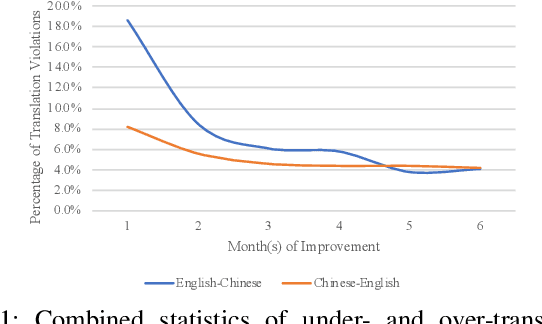
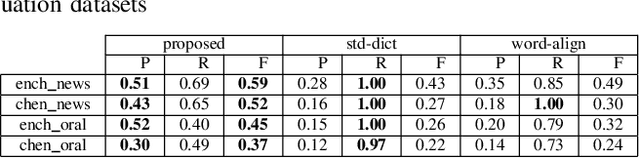

Neural Machine Translation (NMT) has been widely adopted recently due to its advantages compared with the traditional Statistical Machine Translation (SMT). However, an NMT system still often produces translation failures due to the complexity of natural language and sophistication in designing neural networks. While in-house black-box system testing based on reference translations (i.e., examples of valid translations) has been a common practice for NMT quality assurance, an increasingly critical industrial practice, named in-vivo testing, exposes unseen types or instances of translation failures when real users are using a deployed industrial NMT system. To fill the gap of lacking test oracle for in-vivo testing of an NMT system, in this paper, we propose a new approach for automatically identifying translation failures, without requiring reference translations for a translation task; our approach can directly serve as a test oracle for in-vivo testing. Our approach focuses on properties of natural language translation that can be checked systematically and uses information from both the test inputs (i.e., the texts to be translated) and the test outputs (i.e., the translations under inspection) of the NMT system. Our evaluation conducted on real-world datasets shows that our approach can effectively detect targeted property violations as translation failures. Our experiences on deploying our approach in both production and development environments of WeChat (a messenger app with over one billion monthly active users) demonstrate high effectiveness of our approach along with high industry impact.