 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGATHER: Convergence-Centric Hyper-Entity Retrieval for Zero-Shot Cell-Type Annotation
May 07, 2026Zero-shot single-cell cell-type annotation aims to determine a cell's type from a given set of expressed genes without any training. Existing knowledge-graph-based RAG approaches retrieve evidence by expanding from source entities and relying on iterative LLM reasoning. However, in this setting each query contains tens to hundreds of genes, where no single gene is decisive and the label emerges only from their collective co-occurrence. Such hyper-entity queries fundamentally challenge local, entity-wise exploration strategies, which reason from individual genes, leading to poor scalability and substantial LLM cost. We propose GATHER (Graph-Aware Traversal with Hyper-Entity Retrieval), a convergence-centric retriever tailored to hyper-entity queries. It performs global multi-source graph traversal and identifies topological convergence points -- nodes jointly reachable from many input genes. These convergence nodes act as high-information hyper-entities that capture entity synergy. By incorporating node- and path-importance scoring, GATHER selects informative evidence entirely without LLM involvement during retrieval. Instantiated on a self-constructed cell-centric biological knowledge graph (VCKG), GATHER outperforms strong KG-RAG baselines (ToG, ToG-2, RoG, PoG) on two datasets (Immune and Lung), achieving the highest exact-match accuracy (27.45% and 59.64%) with only a single LLM call per sample, compared to 2--61 calls for KG-RAG baselines. Our results demonstrate that convergence nodes compress multi-entity signals into compact, high-information evidence that conveys more per item than multi-hop paths, providing an efficient global alternative to local entity-wise reasoning.
Skip-Connected Policy Optimization for Implicit Advantage
Apr 09, 2026Group Relative Policy Optimization (GRPO) has proven effective in RLVR by using outcome-based rewards. While fine-grained dense rewards can theoretically improve performance, we reveal that under practical sampling budgets, Monte Carlo estimation yields high-variance and sign-inconsistent advantages for early reasoning tokens, paradoxically underperforming outcome-only GRPO. We propose Skip-Connected Optimization (SKPO), which decomposes reasoning into upstream and downstream phases: upstream receives dense rewards from downstream Monte Carlo sampling with single-stream optimization; downstream maintains group-relative optimization, where a skip connection concatenates the upstream segment with the original problem, enabling the model to leverage helpful upstream reasoning while preserving the freedom to bypass flawed reasoning through direct problem access. Experiments demonstrate improvements of 3.91% and 6.17% relative gains over the strongest baselines on Qwen2.5-Math-7B and Llama-3.2-3B respectively across mathematical benchmarks and out-of-domain tasks including general reasoning and code generation. Further analysis reveals an implicit advantage: SKPO generates trajectories with higher intermediate-step quality even when matched for final correctness.
SC-Arena: A Natural Language Benchmark for Single-Cell Reasoning with Knowledge-Augmented Evaluation
Feb 26, 2026Large language models (LLMs) are increasingly applied in scientific research, offering new capabilities for knowledge discovery and reasoning. In single-cell biology, however, evaluation practices for both general and specialized LLMs remain inadequate: existing benchmarks are fragmented across tasks, adopt formats such as multiple-choice classification that diverge from real-world usage, and rely on metrics lacking interpretability and biological grounding. We present SC-ARENA, a natural language evaluation framework tailored to single-cell foundation models. SC-ARENA formalizes a virtual cell abstraction that unifies evaluation targets by representing both intrinsic attributes and gene-level interactions. Within this paradigm, we define five natural language tasks (cell type annotation, captioning, generation, perturbation prediction, and scientific QA) that probe core reasoning capabilities in cellular biology. To overcome the limitations of brittle string-matching metrics, we introduce knowledge-augmented evaluation, which incorporates external ontologies, marker databases, and scientific literature to support biologically faithful and interpretable judgments. Experiments and analysis across both general-purpose and domain-specialized LLMs demonstrate that (i) under the Virtual Cell unified evaluation paradigm, current models achieve uneven performance on biologically complex tasks, particularly those demanding mechanistic or causal understanding; and (ii) our knowledge-augmented evaluation framework ensures biological correctness, provides interpretable, evidence-grounded rationales, and achieves high discriminative capacity, overcoming the brittleness and opacity of conventional metrics. SC-Arena thus provides a unified and interpretable framework for assessing LLMs in single-cell biology, pointing toward the development of biology-aligned, generalizable foundation models.
DLLM-Searcher: Adapting Diffusion Large Language Model for Search Agents
Feb 03, 2026Recently, Diffusion Large Language Models (dLLMs) have demonstrated unique efficiency advantages, enabled by their inherently parallel decoding mechanism and flexible generation paradigm. Meanwhile, despite the rapid advancement of Search Agents, their practical deployment is constrained by a fundamental limitation, termed as 1) Latency Challenge: the serial execution of multi-round reasoning, tool calling, and tool response waiting under the ReAct agent paradigm induces severe end-to-end latency. Intuitively, dLLMs can leverage their distinctive strengths to optimize the operational efficiency of agents under the ReAct agent paradigm. Practically, existing dLLM backbones face the 2) Agent Ability Challenge. That is, existing dLLMs exhibit remarkably weak reasoning and tool-calling capabilities, preventing these advantages from being effectively realized in practice. In this paper, we propose DLLM-Searcher, an optimization framework for dLLM-based Search Agents. To solve the Agent Ability Challenge, we design a two-stage post-training pipeline encompassing Agentic Supervised Fine-Tuning (Agentic SFT) and Agentic Variance-Reduced Preference Optimization Agentic VRPO, which enhances the backbone dLLM's information seeking and reasoning capabilities. To mitigate the Latency Challenge, we leverage the flexible generation mechanism of dLLMs and propose a novel agent paradigm termed Parallel-Reasoning and Acting P-ReAct. P-ReAct guides the model to prioritize decoding tool_call instructions, thereby allowing the model to keep thinking while waiting for the tool's return. Experimental results demonstrate that DLLM-Searcher achieves performance comparable to mainstream LLM-based search agents and P-ReAct delivers approximately 15% inference acceleration. Our code is available at https://anonymous.4open.science/r/DLLM-Searcher-553C
A Step to Decouple Optimization in 3DGS
Jan 26, 20263D Gaussian Splatting (3DGS) has emerged as a powerful technique for real-time novel view synthesis. As an explicit representation optimized through gradient propagation among primitives, optimization widely accepted in deep neural networks (DNNs) is actually adopted in 3DGS, such as synchronous weight updating and Adam with the adaptive gradient. However, considering the physical significance and specific design in 3DGS, there are two overlooked details in the optimization of 3DGS: (i) update step coupling, which induces optimizer state rescaling and costly attribute updates outside the viewpoints, and (ii) gradient coupling in the moment, which may lead to under- or over-effective regularization. Nevertheless, such a complex coupling is under-explored. After revisiting the optimization of 3DGS, we take a step to decouple it and recompose the process into: Sparse Adam, Re-State Regularization and Decoupled Attribute Regularization. Taking a large number of experiments under the 3DGS and 3DGS-MCMC frameworks, our work provides a deeper understanding of these components. Finally, based on the empirical analysis, we re-design the optimization and propose AdamW-GS by re-coupling the beneficial components, under which better optimization efficiency and representation effectiveness are achieved simultaneously.
Cognitive-YOLO: LLM-Driven Architecture Synthesis from First Principles of Data for Object Detection
Dec 13, 2025Designing high-performance object detection architectures is a complex task, where traditional manual design is time-consuming and labor-intensive, and Neural Architecture Search (NAS) is computationally prohibitive. While recent approaches using Large Language Models (LLMs) show promise, they often function as iterative optimizers within a search loop, rather than generating architectures directly from a holistic understanding of the data. To address this gap, we propose Cognitive-YOLO, a novel framework for LLM-driven architecture synthesis that generates network configurations directly from the intrinsic characteristics of the dataset. Our method consists of three stages: first, an analysis module extracts key meta-features (e.g., object scale distribution and scene density) from the target dataset; second, the LLM reasons upon these features, augmented with state-of-the-art components retrieved via Retrieval-Augmented Generation (RAG), to synthesize the architecture into a structured Neural Architecture Description Language (NADL); finally, a compiler instantiates this description into a deployable model. Extensive experiments on five diverse object detection datasets demonstrate that our proposed Cognitive-YOLO consistently generates superior architectures, achieving highly competitive performance and demonstrating a superior performance-per-parameter trade-off compared to strong baseline models across multiple benchmarks. Crucially, our ablation studies prove that the LLM's data-driven reasoning is the primary driver of performance, demonstrating that a deep understanding of data "first principles" is more critical for achieving a superior architecture than simply retrieving SOTA components.
RxSafeBench: Identifying Medication Safety Issues of Large Language Models in Simulated Consultation
Nov 06, 2025Numerous medical systems powered by Large Language Models (LLMs) have achieved remarkable progress in diverse healthcare tasks. However, research on their medication safety remains limited due to the lack of real world datasets, constrained by privacy and accessibility issues. Moreover, evaluation of LLMs in realistic clinical consultation settings, particularly regarding medication safety, is still underexplored. To address these gaps, we propose a framework that simulates and evaluates clinical consultations to systematically assess the medication safety capabilities of LLMs. Within this framework, we generate inquiry diagnosis dialogues with embedded medication risks and construct a dedicated medication safety database, RxRisk DB, containing 6,725 contraindications, 28,781 drug interactions, and 14,906 indication-drug pairs. A two-stage filtering strategy ensures clinical realism and professional quality, resulting in the benchmark RxSafeBench with 2,443 high-quality consultation scenarios. We evaluate leading open-source and proprietary LLMs using structured multiple choice questions that test their ability to recommend safe medications under simulated patient contexts. Results show that current LLMs struggle to integrate contraindication and interaction knowledge, especially when risks are implied rather than explicit. Our findings highlight key challenges in ensuring medication safety in LLM-based systems and provide insights into improving reliability through better prompting and task-specific tuning. RxSafeBench offers the first comprehensive benchmark for evaluating medication safety in LLMs, advancing safer and more trustworthy AI-driven clinical decision support.
Jinx: Unlimited LLMs for Probing Alignment Failures
Aug 12, 2025Unlimited, or so-called helpful-only language models are trained without safety alignment constraints and never refuse user queries. They are widely used by leading AI companies as internal tools for red teaming and alignment evaluation. For example, if a safety-aligned model produces harmful outputs similar to an unlimited model, this indicates alignment failures that require further attention. Despite their essential role in assessing alignment, such models are not available to the research community. We introduce Jinx, a helpful-only variant of popular open-weight LLMs. Jinx responds to all queries without refusals or safety filtering, while preserving the base model's capabilities in reasoning and instruction following. It provides researchers with an accessible tool for probing alignment failures, evaluating safety boundaries, and systematically studying failure modes in language model safety.
R1-Searcher++: Incentivizing the Dynamic Knowledge Acquisition of LLMs via Reinforcement Learning
May 22, 2025Large Language Models (LLMs) are powerful but prone to hallucinations due to static knowledge. Retrieval-Augmented Generation (RAG) helps by injecting external information, but current methods often are costly, generalize poorly, or ignore the internal knowledge of the model. In this paper, we introduce R1-Searcher++, a novel framework designed to train LLMs to adaptively leverage both internal and external knowledge sources. R1-Searcher++ employs a two-stage training strategy: an initial SFT Cold-start phase for preliminary format learning, followed by RL for Dynamic Knowledge Acquisition. The RL stage uses outcome-supervision to encourage exploration, incorporates a reward mechanism for internal knowledge utilization, and integrates a memorization mechanism to continuously assimilate retrieved information, thereby enriching the model's internal knowledge. By leveraging internal knowledge and external search engine, the model continuously improves its capabilities, enabling efficient retrieval-augmented reasoning. Our experiments demonstrate that R1-Searcher++ outperforms previous RAG and reasoning methods and achieves efficient retrieval. The code is available at https://github.com/RUCAIBox/R1-Searcher-plus.
Tight Gap-Dependent Memory-Regret Trade-Off for Single-Pass Streaming Stochastic Multi-Armed Bandits
Mar 04, 2025
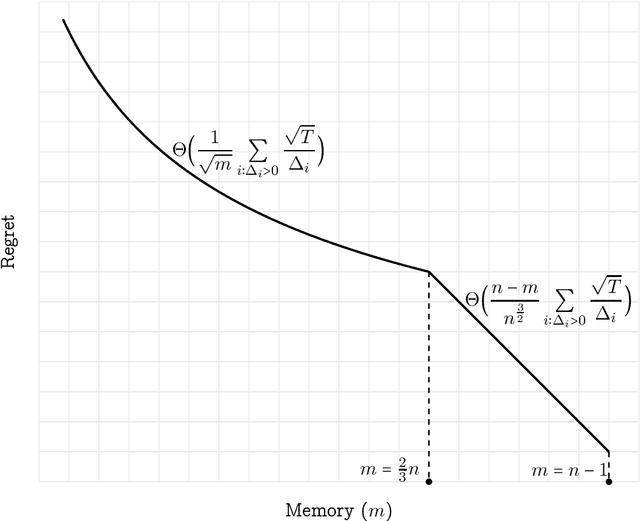
We study the problem of minimizing gap-dependent regret for single-pass streaming stochastic multi-armed bandits (MAB). In this problem, the $n$ arms are present in a stream, and at most $m<n$ arms and their statistics can be stored in the memory. We establish tight non-asymptotic regret bounds regarding all relevant parameters, including the number of arms $n$, the memory size $m$, the number of rounds $T$ and $(\Delta_i)_{i\in [n]}$ where $\Delta_i$ is the reward mean gap between the best arm and the $i$-th arm. These gaps are not known in advance by the player. Specifically, for any constant $\alpha \ge 1$, we present two algorithms: one applicable for $m\ge \frac{2}{3}n$ with regret at most $O_\alpha\Big(\frac{(n-m)T^{\frac{1}{\alpha + 1}}}{n^{1 + {\frac{1}{\alpha + 1}}}}\displaystyle\sum_{i:\Delta_i > 0}\Delta_i^{1 - 2\alpha}\Big)$ and another applicable for $m<\frac{2}{3}n$ with regret at most $O_\alpha\Big(\frac{T^{\frac{1}{\alpha+1}}}{m^{\frac{1}{\alpha+1}}}\displaystyle\sum_{i:\Delta_i > 0}\Delta_i^{1 - 2\alpha}\Big)$. We also prove matching lower bounds for both cases by showing that for any constant $\alpha\ge 1$ and any $m\leq k < n$, there exists a set of hard instances on which the regret of any algorithm is $\Omega_\alpha\Big(\frac{(k-m+1) T^{\frac{1}{\alpha+1}}}{k^{1 + \frac{1}{\alpha+1}}} \sum_{i:\Delta_i > 0}\Delta_i^{1-2\alpha}\Big)$. This is the first tight gap-dependent regret bound for streaming MAB. Prior to our work, an $O\Big(\sum_{i\colon\Delta>0} \frac{\sqrt{T}\log T}{\Delta_i}\Big)$ upper bound for the special case of $\alpha=1$ and $m=O(1)$ was established by Agarwal, Khanna and Patil (COLT'22). In contrast, our results provide the correct order of regret as $\Theta\Big(\frac{1}{\sqrt{m}}\sum_{i\colon\Delta>0}\frac{\sqrt{T}}{\Delta_i}\Big)$.