 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Text Representation Learning with Information-Theoretic Perspective for Adversarial Robustness
Paper and Code
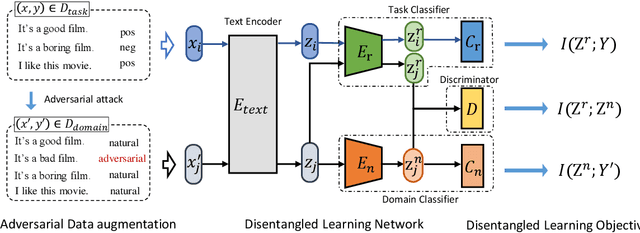

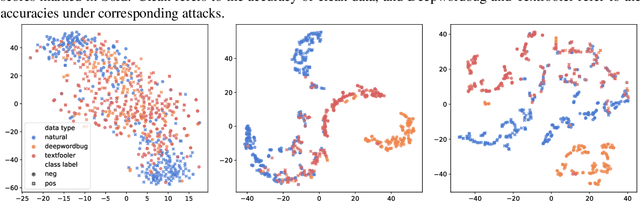
Adversarial vulnerability remains a major obstacle to constructing reliable NLP systems. When imperceptible perturbations are added to raw input text, the performance of a deep learning model may drop dramatically under attacks. Recent work argues the adversarial vulnerability of the model is caused by the non-robust features in supervised training. Thus in this paper, we tackle the adversarial robustness challenge from the view of disentangled representation learning, which is able to explicitly disentangle robust and non-robust features in text. Specifically, inspired by the variation of information (VI) in information theory, we derive a disentangled learning objective composed of mutual information to represent both the semantic representativeness of latent embeddings and differentiation of robust and non-robust features. On the basis of this, we design a disentangled learning network to estimate these mutual information. Experiments on text classification and entailment tasks show that our method significantly outperforms the representative methods under adversarial attacks, indicating that discarding non-robust features is critical for improving adversarial robustness.