 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX-Searcher: Augmenting LLMs' Search Capabilities through Agentic Planning and Execution
Mar 17, 2026Retrieval-augmented generation (RAG), based on large language models (LLMs), serves as a vital approach to retrieving and leveraging external knowledge in various domain applications. When confronted with complex multi-hop questions, single-round retrieval is often insufficient for accurate reasoning and problem solving. To enhance search capabilities for complex tasks, most existing works integrate multi-round iterative retrieval with reasoning processes via end-to-end training. While these approaches significantly improve problem-solving performance, they are still faced with challenges in task reasoning and model training, especially ambiguous retrieval execution paths and sparse rewards in end-to-end reinforcement learning (RL) process, leading to inaccurate retrieval results and performance degradation. To address these issues, in this paper, we proposes APEX-Searcher, a novel Agentic Planning and Execution framework to augment LLM search capabilities. Specifically, we introduce a two-stage agentic framework that decouples the retrieval process into planning and execution: It first employs RL with decomposition-specific rewards to optimize strategic planning; Built on the sub-task decomposition, it then applies supervised fine-tuning on high-quality multi-hop trajectories to equip the model with robust iterative sub-task execution capabilities. Extensive experiments demonstrate that our proposed framework achieves significant improvements in both multi-hop RAG and task planning performances across multiple benchmarks.
CineSRD: Leveraging Visual, Acoustic, and Linguistic Cues for Open-World Visual Media Speaker Diarization
Mar 17, 2026Traditional speaker diarization systems have primarily focused on constrained scenarios such as meetings and interviews, where the number of speakers is limited and acoustic conditions are relatively clean. To explore open-world speaker diarization, we extend this task to the visual media domain, encompassing complex audiovisual programs such as films and TV series. This new setting introduces several challenges, including long-form video understanding, a large number of speakers, cross-modal asynchrony between audio and visual cues, and uncontrolled in-the-wild variability. To address these challenges, we propose Cinematic Speaker Registration & Diarization (CineSRD), a unified multimodal framework that leverages visual, acoustic, and linguistic cues from video, speech, and subtitles for speaker annotation. CineSRD first performs visual anchor clustering to register initial speakers and then integrates an audio language model for speaker turn detection, refining annotations and supplementing unregistered off-screen speakers. Furthermore, we construct and release a dedicated speaker diarization benchmark for visual media that includes Chinese and English programs. Experimental results demonstrate that CineSRD achieves superior performance on the proposed benchmark and competitive results on conventional datasets, validating its robustness and generalizability in open-world visual media settings.
Flexible Entropy Control in RLVR with Gradient-Preserving Perspective
Feb 10, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a critical method for enhancing the reasoning capabilities of Large Language Models (LLMs). However, continuous training often leads to policy entropy collapse, characterized by a rapid decay in entropy that results in premature overconfidence, reduced output diversity, and vanishing gradient norms that inhibit learning. Gradient-Preserving Clipping is a primary factor influencing these dynamics, but existing mitigation strategies are largely static and lack a framework connecting clipping mechanisms to precise entropy control. This paper proposes reshaping entropy control in RL from the perspective of Gradient-Preserving Clipping. We first theoretically and empirically verify the contributions of specific importance sampling ratio regions to entropy growth and reduction. Leveraging these findings, we introduce a novel regulation mechanism using dynamic clipping threshold to precisely manage entropy. Furthermore, we design and evaluate dynamic entropy control strategies, including increase-then-decrease, decrease-increase-decrease, and oscillatory decay. Experimental results demonstrate that these strategies effectively mitigate entropy collapse, and achieve superior performance across multiple benchmarks.
From Utterance to Vividity: Training Expressive Subtitle Translation LLM via Adaptive Local Preference Optimization
Feb 01, 2026The rapid development of Large Language Models (LLMs) has significantly enhanced the general capabilities of machine translation. However, as application scenarios become more complex, the limitations of LLMs in vertical domain translations are gradually becoming apparent. In this study, we focus on how to construct translation LLMs that meet the needs of domain customization. We take visual media subtitle translation as our topic and explore how to train expressive and vivid translation LLMs. We investigated the situations of subtitle translation and other domains of literal and liberal translation, verifying the reliability of LLM as reward model and evaluator for translation. Additionally, to train an expressive translation LLM, we constructed and released a multidirectional subtitle parallel corpus dataset and proposed the Adaptive Local Preference Optimization (ALPO) method to address fine-grained preference alignment. Experimental results demonstrate that ALPO achieves outstanding performance in multidimensional evaluation of translation quality.
Hermes the Polyglot: A Unified Framework to Enhance Expressiveness for Multimodal Interlingual Subtitling
Jan 31, 2026Interlingual subtitling, which translates subtitles of visual media into a target language, is essential for entertainment localization but has not yet been explored in machine translation. Although Large Language Models (LLMs) have significantly advanced the general capabilities of machine translation, the distinctive characteristics of subtitle texts pose persistent challenges in interlingual subtitling, particularly regarding semantic coherence, pronoun and terminology translation, and translation expressiveness. To address these issues, we present Hermes, an LLM-based automated subtitling framework. Hermes integrates three modules: Speaker Diarization, Terminology Identification, and Expressiveness Enhancement, which effectively tackle the above challenges. Experiments demonstrate that Hermes achieves state-of-the-art diarization performance and generates expressive, contextually coherent translations, thereby advancing research in interlingual subtitling.
MobileDreamer: Generative Sketch World Model for GUI Agent
Jan 07, 2026Mobile GUI agents have shown strong potential in real-world automation and practical applications. However, most existing agents remain reactive, making decisions mainly from current screen, which limits their performance on long-horizon tasks. Building a world model from repeated interactions enables forecasting action outcomes and supports better decision making for mobile GUI agents. This is challenging because the model must predict post-action states with spatial awareness while remaining efficient enough for practical deployment. In this paper, we propose MobileDreamer, an efficient world-model-based lookahead framework to equip the GUI agents based on the future imagination provided by the world model. It consists of textual sketch world model and rollout imagination for GUI agent. Textual sketch world model forecasts post-action states through a learning process to transform digital images into key task-related sketches, and designs a novel order-invariant learning strategy to preserve the spatial information of GUI elements. The rollout imagination strategy for GUI agent optimizes the action-selection process by leveraging the prediction capability of world model. Experiments on Android World show that MobileDreamer achieves state-of-the-art performance and improves task success by 5.25%. World model evaluations further verify that our textual sketch modeling accurately forecasts key GUI elements.
Think on your Feet: Adaptive Thinking via Reinforcement Learning for Social Agents
May 04, 2025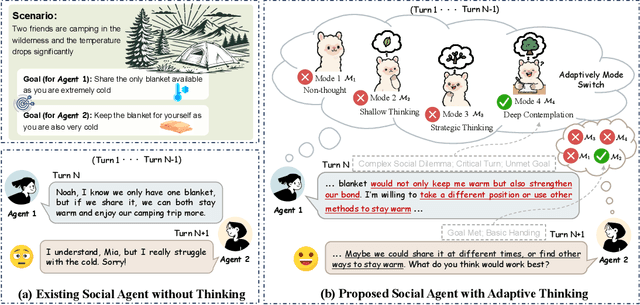
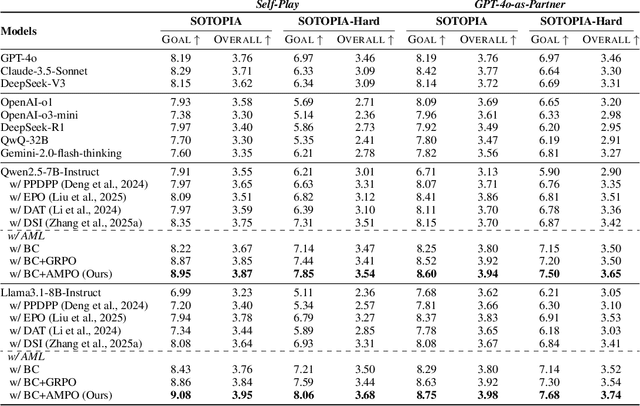
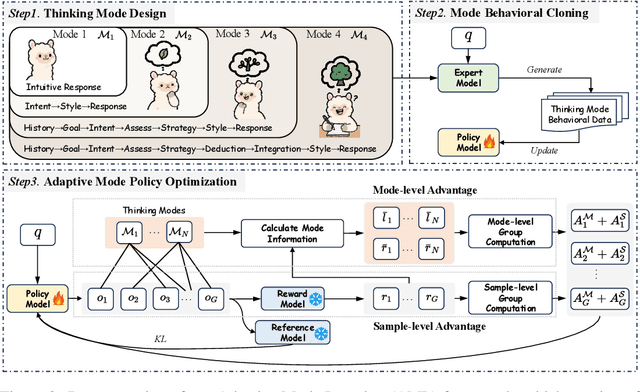
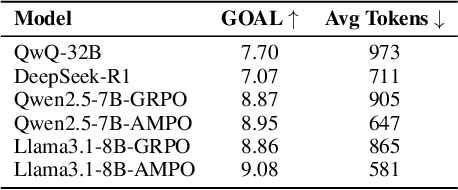
Effective social intelligence simulation requires language agents to dynamically adjust reasoning depth, a capability notably absent in current approaches. While existing methods either lack this kind of reasoning capability or enforce uniform long chain-of-thought reasoning across all scenarios, resulting in excessive token usage and inappropriate social simulation. In this paper, we propose $\textbf{A}$daptive $\textbf{M}$ode $\textbf{L}$earning ($\textbf{AML}$) that strategically selects from four thinking modes (intuitive reaction $\rightarrow$ deep contemplation) based on real-time context. Our framework's core innovation, the $\textbf{A}$daptive $\textbf{M}$ode $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{AMPO}$) algorithm, introduces three key advancements over existing methods: (1) Multi-granular thinking mode design, (2) Context-aware mode switching across social interaction, and (3) Token-efficient reasoning via depth-adaptive processing. Extensive experiments on social intelligence tasks confirm that AML achieves 15.6% higher task performance than state-of-the-art methods. Notably, our method outperforms GRPO by 7.0% with 32.8% shorter reasoning chains. These results demonstrate that context-sensitive thinking mode selection, as implemented in AMPO, enables more human-like adaptive reasoning than GRPO's fixed-depth approach
DEMO: Reframing Dialogue Interaction with Fine-grained Element Modeling
Dec 06, 2024



Large language models (LLMs) have made dialogue one of the central modes of human-machine interaction, leading to the accumulation of vast amounts of conversation logs and increasing demand for dialogue generation. A conversational life-cycle spans from the Prelude through the Interlocution to the Epilogue, encompassing various elements. Despite the existence of numerous dialogue-related studies, there is a lack of benchmarks that encompass comprehensive dialogue elements, hindering precise modeling and systematic evaluation. To bridge this gap, we introduce an innovative research task $\textbf{D}$ialogue $\textbf{E}$lement $\textbf{MO}$deling, including $\textit{Element Awareness}$ and $\textit{Dialogue Agent Interaction}$, and propose a novel benchmark, $\textbf{DEMO}$, designed for a comprehensive dialogue modeling and assessment. Inspired by imitation learning, we further build the agent which possesses the adept ability to model dialogue elements based on the DEMO benchmark. Extensive experiments indicate that existing LLMs still exhibit considerable potential for enhancement, and our DEMO agent has superior performance in both in-domain and out-of-domain tasks.
Variational Graph Auto-Encoder Based Inductive Learning Method for Semi-Supervised Classification
Mar 26, 2024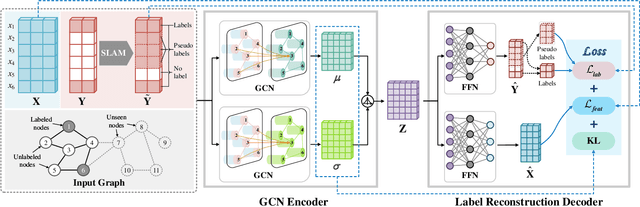
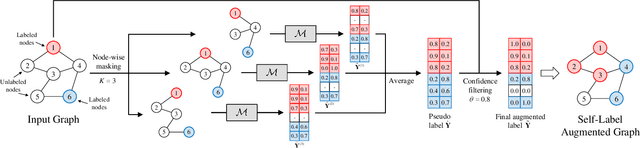
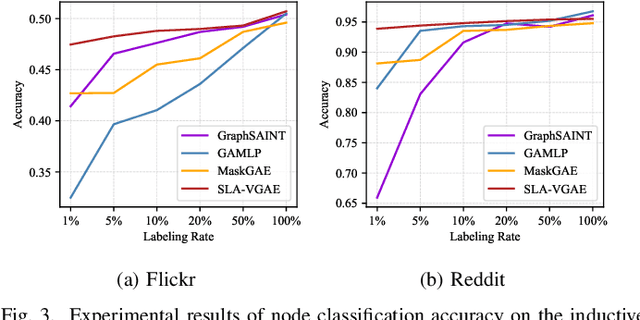
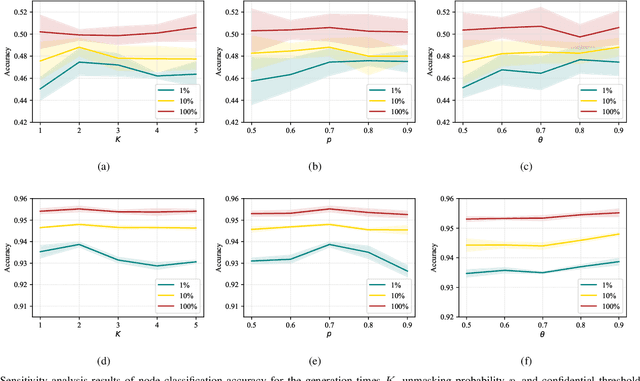
Graph representation learning is a fundamental research issue in various domains of applications, of which the inductive learning problem is particularly challenging as it requires models to generalize to unseen graph structures during inference. In recent years, graph neural networks (GNNs) have emerged as powerful graph models for inductive learning tasks such as node classification, whereas they typically heavily rely on the annotated nodes under a fully supervised training setting. Compared with the GNN-based methods, variational graph auto-encoders (VGAEs) are known to be more generalizable to capture the internal structural information of graphs independent of node labels and have achieved prominent performance on multiple unsupervised learning tasks. However, so far there is still a lack of work focusing on leveraging the VGAE framework for inductive learning, due to the difficulties in training the model in a supervised manner and avoiding over-fitting the proximity information of graphs. To solve these problems and improve the model performance of VGAEs for inductive graph representation learning, in this work, we propose the Self-Label Augmented VGAE model. To leverage the label information for training, our model takes node labels as one-hot encoded inputs and then performs label reconstruction in model training. To overcome the scarcity problem of node labels for semi-supervised settings, we further propose the Self-Label Augmentation Method (SLAM), which uses pseudo labels generated by our model with a node-wise masking approach to enhance the label information. Experiments on benchmark inductive learning graph datasets verify that our proposed model archives promising results on node classification with particular superiority under semi-supervised learning settings.
YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction
Jan 08, 2024



The difficulty of the information extraction task lies in dealing with the task-specific label schemas and heterogeneous data structures. Recent work has proposed methods based on large language models to uniformly model different information extraction tasks. However, these existing methods are deficient in their information extraction capabilities for Chinese languages other than English. In this paper, we propose an end-to-end chat-enhanced instruction tuning framework for universal information extraction (YAYI-UIE), which supports both Chinese and English. Specifically, we utilize dialogue data and information extraction data to enhance the information extraction performance jointly. Experimental results show that our proposed framework achieves state-of-the-art performance on Chinese datasets while also achieving comparable performance on English datasets under both supervised settings and zero-shot settings.