 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Empirical Study of Vision-Language Pre-trained Model for Supervised Cross-Modal Retrieval
Paper and Code
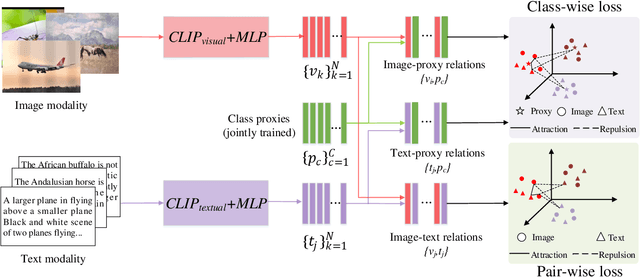
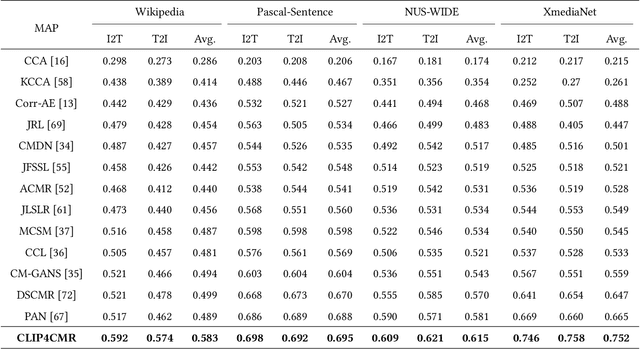
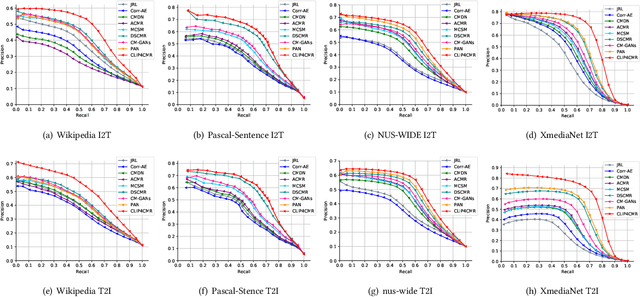
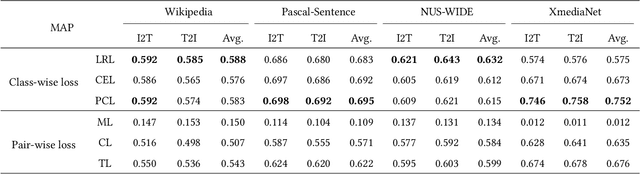
Cross-Modal Retrieval (CMR) is an important research topic across multimodal computing and information retrieval, which takes one type of data as the query to retrieve relevant data of another type, and has been widely used in many real-world applications. Recently, the vision-language pre-trained model represented by CLIP has demonstrated its superiority of learning visual and textual representations and its impressive performance on various vision and language related tasks. Although CLIP as well as the previous pre-trained models have shown great performance improvement in unsupervised CMR, the performance and impact of these pre-trained models on supervised CMR were rarely explored due to the lack of multimodal class-level associations. In this paper, we take CLIP as the current representative vision-language pre-trained model to conduct a comprehensive empirical study and provide insights on its performance and impact on supervised CMR. To this end, we first propose a novel model CLIP4CMR (\textbf{CLIP For} supervised \textbf{C}ross-\textbf{M}odal \textbf{R}etrieval) that employs pre-trained CLIP as backbone network to perform supervised CMR. We then revisit the existing loss function design in CMR, including the most common pair-wise losses, class-wise losses and hybrid ones, and provide insights on applying CLIP. Moreover, we investigate several concerned issues in supervised CMR and provide new perspectives for this field via CLIP4CMR, including the robustness to modality imbalance and the sensitivity to hyper-parameters. Extensive experimental results show that the CLIP4CMR achieves SOTA results with significant improvements on the benchmark datasets Wikipedia, NUS-WIDE, Pascal-Sentence and XmediaNet. Our data and codes are publicly available at https://github.com/zhixiongz/CLIP4CMR.