 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Reward Modeling: Verifying GUI Agent via Online Proactive Interaction
Jan 31, 2026Reinforcement learning with verifiable rewards (RLVR) is pivotal for the continuous evolution of GUI agents, yet existing evaluation paradigms face significant limitations. Rule-based methods suffer from poor scalability and cannot handle open-ended tasks, while LLM-as-a-Judge approaches rely on passive visual observation, often failing to capture latent system states due to partial state observability. To address these challenges, we advocate for a paradigm shift from passive evaluation to Agentic Interactive Verification. We introduce VAGEN, a framework that employs a verifier agent equipped with interaction tools to autonomously plan verification strategies and proactively probe the environment for evidence of task completion. Leveraging the insight that GUI tasks are typically "easy to verify but hard to solve", VAGEN overcomes the bottlenecks of visual limitations. Experimental results on OSWorld-Verified and AndroidWorld benchmarks demonstrate that VAGEN significantly improves evaluation accuracy compared to LLM-as-a-Judge baselines and further enhances performance through test-time scaling strategies.
Variational Graph Auto-Encoder Based Inductive Learning Method for Semi-Supervised Classification
Mar 26, 2024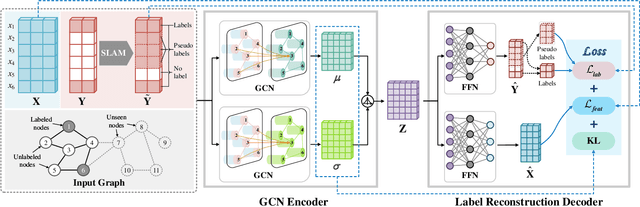
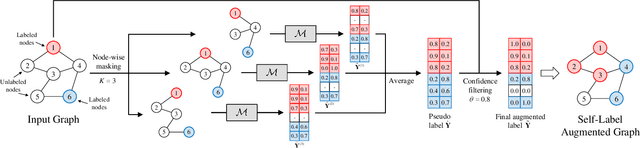
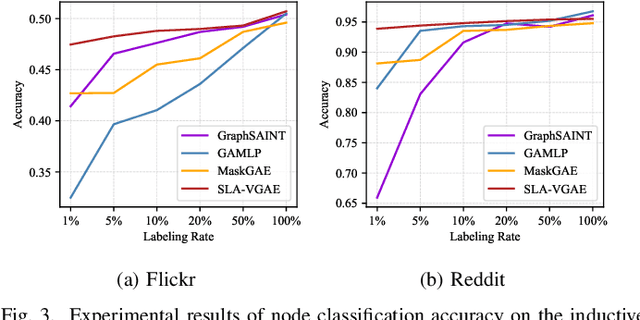
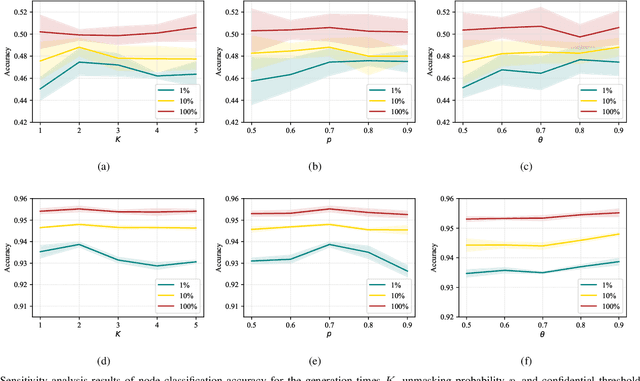
Graph representation learning is a fundamental research issue in various domains of applications, of which the inductive learning problem is particularly challenging as it requires models to generalize to unseen graph structures during inference. In recent years, graph neural networks (GNNs) have emerged as powerful graph models for inductive learning tasks such as node classification, whereas they typically heavily rely on the annotated nodes under a fully supervised training setting. Compared with the GNN-based methods, variational graph auto-encoders (VGAEs) are known to be more generalizable to capture the internal structural information of graphs independent of node labels and have achieved prominent performance on multiple unsupervised learning tasks. However, so far there is still a lack of work focusing on leveraging the VGAE framework for inductive learning, due to the difficulties in training the model in a supervised manner and avoiding over-fitting the proximity information of graphs. To solve these problems and improve the model performance of VGAEs for inductive graph representation learning, in this work, we propose the Self-Label Augmented VGAE model. To leverage the label information for training, our model takes node labels as one-hot encoded inputs and then performs label reconstruction in model training. To overcome the scarcity problem of node labels for semi-supervised settings, we further propose the Self-Label Augmentation Method (SLAM), which uses pseudo labels generated by our model with a node-wise masking approach to enhance the label information. Experiments on benchmark inductive learning graph datasets verify that our proposed model archives promising results on node classification with particular superiority under semi-supervised learning settings.
YAYI 2: Multilingual Open-Source Large Language Models
Dec 22, 2023As the latest advancements in natural language processing, large language models (LLMs) have achieved human-level language understanding and generation abilities in many real-world tasks, and even have been regarded as a potential path to the artificial general intelligence. To better facilitate research on LLMs, many open-source LLMs, such as Llama 2 and Falcon, have recently been proposed and gained comparable performances to proprietary models. However, these models are primarily designed for English scenarios and exhibit poor performances in Chinese contexts. In this technical report, we propose YAYI 2, including both base and chat models, with 30 billion parameters. YAYI 2 is pre-trained from scratch on a multilingual corpus which contains 2.65 trillion tokens filtered by our pre-training data processing pipeline. The base model is aligned with human values through supervised fine-tuning with millions of instructions and reinforcement learning from human feedback. Extensive experiments on multiple benchmarks, such as MMLU and CMMLU, consistently demonstrate that the proposed YAYI 2 outperforms other similar sized open-source models.
Isomorphic-Consistent Variational Graph Auto-Encoders for Multi-Level Graph Representation Learning
Dec 09, 2023Graph representation learning is a fundamental research theme and can be generalized to benefit multiple downstream tasks from the node and link levels to the higher graph level. In practice, it is desirable to develop task-agnostic general graph representation learning methods that are typically trained in an unsupervised manner. Related research reveals that the power of graph representation learning methods depends on whether they can differentiate distinct graph structures as different embeddings and map isomorphic graphs to consistent embeddings (i.e., the isomorphic consistency of graph models). However, for task-agnostic general graph representation learning, existing unsupervised graph models, represented by the variational graph auto-encoders (VGAEs), can only keep the isomorphic consistency within the subgraphs of 1-hop neighborhoods and thus usually manifest inferior performance on the more difficult higher-level tasks. To overcome the limitations of existing unsupervised methods, in this paper, we propose the Isomorphic-Consistent VGAE (IsoC-VGAE) for multi-level task-agnostic graph representation learning. We first devise a decoding scheme to provide a theoretical guarantee of keeping the isomorphic consistency under the settings of unsupervised learning. We then propose the Inverse Graph Neural Network (Inv-GNN) decoder as its intuitive realization, which trains the model via reconstructing the GNN node embeddings with multi-hop neighborhood information, so as to maintain the high-order isomorphic consistency within the VGAE framework. We conduct extensive experiments on the representative graph learning tasks at different levels, including node classification, link prediction and graph classification, and the results verify that our proposed model generally outperforms both the state-of-the-art unsupervised methods and representative supervised methods.
Spiking Variational Graph Auto-Encoders for Efficient Graph Representation Learning
Oct 24, 2022



Graph representation learning is a fundamental research issue and benefits a wide range of applications on graph-structured data. Conventional artificial neural network-based methods such as graph neural networks (GNNs) and variational graph auto-encoders (VGAEs) have achieved promising results in learning on graphs, but they suffer from extremely high energy consumption during training and inference stages. Inspired by the bio-fidelity and energy-efficiency of spiking neural networks (SNNs), recent methods attempt to adapt GNNs to the SNN framework by substituting spiking neurons for the activation functions. However, existing SNN-based GNN methods cannot be applied to the more general multi-node representation learning problem represented by link prediction. Moreover, these methods did not fully exploit the bio-fidelity of SNNs, as they still require costly multiply-accumulate (MAC) operations, which severely harm the energy efficiency. To address the above issues and improve energy efficiency, in this paper, we propose an SNN-based deep generative method, namely the Spiking Variational Graph Auto-Encoders (S-VGAE) for efficient graph representation learning. To deal with the multi-node problem, we propose a probabilistic decoder that generates binary latent variables as spiking node representations and reconstructs graphs via the weighted inner product. To avoid the MAC operations for energy efficiency, we further decouple the propagation and transformation layers of conventional GNN aggregators. We conduct link prediction experiments on multiple benchmark graph datasets, and the results demonstrate that our model consumes significantly lower energy with the performances superior or comparable to other ANN- and SNN-based methods for graph representation learning.
A Deep Latent Space Model for Graph Representation Learning
Jun 22, 2021



Graph representation learning is a fundamental problem for modeling relational data and benefits a number of downstream applications. Traditional Bayesian-based graph models and recent deep learning based GNN either suffer from impracticability or lack interpretability, thus combined models for undirected graphs have been proposed to overcome the weaknesses. As a large portion of real-world graphs are directed graphs (of which undirected graphs are special cases), in this paper, we propose a Deep Latent Space Model (DLSM) for directed graphs to incorporate the traditional latent variable based generative model into deep learning frameworks. Our proposed model consists of a graph convolutional network (GCN) encoder and a stochastic decoder, which are layer-wise connected by a hierarchical variational auto-encoder architecture. By specifically modeling the degree heterogeneity using node random factors, our model possesses better interpretability in both community structure and degree heterogeneity. For fast inference, the stochastic gradient variational Bayes (SGVB) is adopted using a non-iterative recognition model, which is much more scalable than traditional MCMC-based methods. The experiments on real-world datasets show that the proposed model achieves the state-of-the-art performances on both link prediction and community detection tasks while learning interpretable node embeddings. The source code is available at https://github.com/upperr/DLSM.