 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEDA: Belief Estimation as Probabilistic Constraints for Performing Strategic Dialogue Acts
Dec 31, 2025Strategic dialogue requires agents to execute distinct dialogue acts, for which belief estimation is essential. While prior work often estimates beliefs accurately, it lacks a principled mechanism to use those beliefs during generation. We bridge this gap by first formalizing two core acts Adversarial and Alignment, and by operationalizing them via probabilistic constraints on what an agent may generate. We instantiate this idea in BEDA, a framework that consists of the world set, the belief estimator for belief estimation, and the conditional generator that selects acts and realizes utterances consistent with the inferred beliefs. Across three settings, Conditional Keeper Burglar (CKBG, adversarial), Mutual Friends (MF, cooperative), and CaSiNo (negotiation), BEDA consistently outperforms strong baselines: on CKBG it improves success rate by at least 5.0 points across backbones and by 20.6 points with GPT-4.1-nano; on Mutual Friends it achieves an average improvement of 9.3 points; and on CaSiNo it achieves the optimal deal relative to all baselines. These results indicate that casting belief estimation as constraints provides a simple, general mechanism for reliable strategic dialogue.
Seek in the Dark: Reasoning via Test-Time Instance-Level Policy Gradient in Latent Space
May 19, 2025Reasoning ability, a core component of human intelligence, continues to pose a significant challenge for Large Language Models (LLMs) in the pursuit of AGI. Although model performance has improved under the training scaling law, significant challenges remain, particularly with respect to training algorithms, such as catastrophic forgetting, and the limited availability of novel training data. As an alternative, test-time scaling enhances reasoning performance by increasing test-time computation without parameter updating. Unlike prior methods in this paradigm focused on token space, we propose leveraging latent space for more effective reasoning and better adherence to the test-time scaling law. We introduce LatentSeek, a novel framework that enhances LLM reasoning through Test-Time Instance-level Adaptation (TTIA) within the model's latent space. Specifically, LatentSeek leverages policy gradient to iteratively update latent representations, guided by self-generated reward signals. LatentSeek is evaluated on a range of reasoning benchmarks, including GSM8K, MATH-500, and AIME2024, across multiple LLM architectures. Results show that LatentSeek consistently outperforms strong baselines, such as Chain-of-Thought prompting and fine-tuning-based methods. Furthermore, our analysis demonstrates that LatentSeek is highly efficient, typically converging within a few iterations for problems of average complexity, while also benefiting from additional iterations, thereby highlighting the potential of test-time scaling in the latent space. These findings position LatentSeek as a lightweight, scalable, and effective solution for enhancing the reasoning capabilities of LLMs.
Variational Graph Auto-Encoder Based Inductive Learning Method for Semi-Supervised Classification
Mar 26, 2024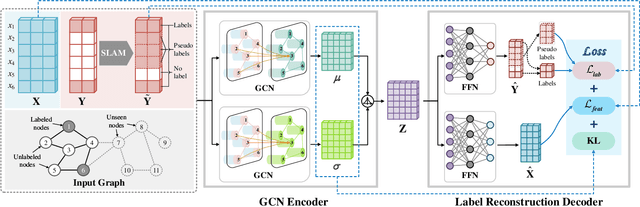
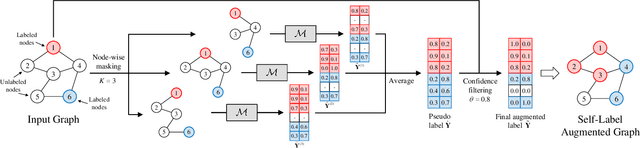
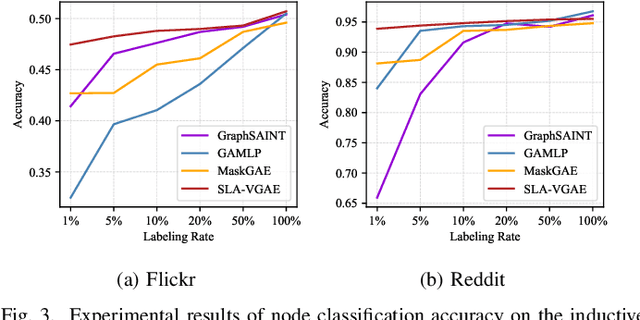
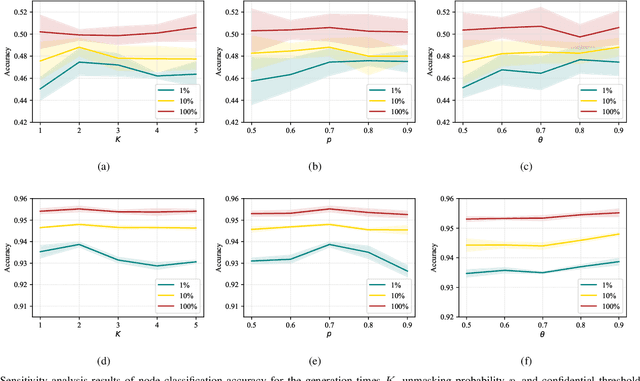
Graph representation learning is a fundamental research issue in various domains of applications, of which the inductive learning problem is particularly challenging as it requires models to generalize to unseen graph structures during inference. In recent years, graph neural networks (GNNs) have emerged as powerful graph models for inductive learning tasks such as node classification, whereas they typically heavily rely on the annotated nodes under a fully supervised training setting. Compared with the GNN-based methods, variational graph auto-encoders (VGAEs) are known to be more generalizable to capture the internal structural information of graphs independent of node labels and have achieved prominent performance on multiple unsupervised learning tasks. However, so far there is still a lack of work focusing on leveraging the VGAE framework for inductive learning, due to the difficulties in training the model in a supervised manner and avoiding over-fitting the proximity information of graphs. To solve these problems and improve the model performance of VGAEs for inductive graph representation learning, in this work, we propose the Self-Label Augmented VGAE model. To leverage the label information for training, our model takes node labels as one-hot encoded inputs and then performs label reconstruction in model training. To overcome the scarcity problem of node labels for semi-supervised settings, we further propose the Self-Label Augmentation Method (SLAM), which uses pseudo labels generated by our model with a node-wise masking approach to enhance the label information. Experiments on benchmark inductive learning graph datasets verify that our proposed model archives promising results on node classification with particular superiority under semi-supervised learning settings.
YAYI 2: Multilingual Open-Source Large Language Models
Dec 22, 2023As the latest advancements in natural language processing, large language models (LLMs) have achieved human-level language understanding and generation abilities in many real-world tasks, and even have been regarded as a potential path to the artificial general intelligence. To better facilitate research on LLMs, many open-source LLMs, such as Llama 2 and Falcon, have recently been proposed and gained comparable performances to proprietary models. However, these models are primarily designed for English scenarios and exhibit poor performances in Chinese contexts. In this technical report, we propose YAYI 2, including both base and chat models, with 30 billion parameters. YAYI 2 is pre-trained from scratch on a multilingual corpus which contains 2.65 trillion tokens filtered by our pre-training data processing pipeline. The base model is aligned with human values through supervised fine-tuning with millions of instructions and reinforcement learning from human feedback. Extensive experiments on multiple benchmarks, such as MMLU and CMMLU, consistently demonstrate that the proposed YAYI 2 outperforms other similar sized open-source models.