 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes LLM Alignment Really Need Diversity? An Empirical Study of Adapting RLVR Methods for Moral Reasoning
Mar 11, 2026Reinforcement learning with verifiable rewards (RLVR) has achieved remarkable success in logical reasoning tasks, yet whether large language model (LLM) alignment requires fundamentally different approaches remains unclear. Given the apparent tolerance for multiple valid responses in moral reasoning, a natural hypothesis is that alignment tasks inherently require diversity-seeking distribution-matching algorithms rather than reward-maximizing policy-based methods. We conduct the first comprehensive empirical study comparing both paradigms on MoReBench. To enable stable RLVR training, we build a rubric-grounded reward pipeline by training a Qwen3-1.7B judge model. Contrary to our hypothesis, we find that distribution-matching approaches do not demonstrate significant advantages over reward-maximizing methods as expected on alignment tasks. Through semantic visualization mapping high-reward responses to semantic space, we demonstrate that moral reasoning exhibits more concentrated high-reward distributions than mathematical reasoning, where diverse solution strategies yield similarly high rewards. This counter-intuitive finding explains why mode-seeking optimization proves equally or more effective for alignment tasks. Our results suggest that alignment tasks do not inherently require diversity-preserving algorithms, and standard reward-maximizing RLVR methods can effectively transfer to moral reasoning without explicit diversity mechanisms.
How Far Can Unsupervised RLVR Scale LLM Training?
Mar 09, 2026Unsupervised reinforcement learning with verifiable rewards (URLVR) offers a pathway to scale LLM training beyond the supervision bottleneck by deriving rewards without ground truth labels. Recent works leverage model intrinsic signals, showing promising early gains, yet their potential and limitations remain unclear. In this work, we revisit URLVR and provide a comprehensive analysis spanning taxonomy, theory and extensive experiments. We first classify URLVR methods into intrinsic versus external based on reward sources, then establish a unified theoretical framework revealing that all intrinsic methods converge toward sharpening the model's initial distribution This sharpening mechanism succeeds when initial confidence aligns with correctness but fails catastrophically when misaligned. Through systematic experiments, we show intrinsic rewards consistently follow a rise-then-fall pattern across methods, with collapse timing determined by model prior rather than engineering choices. Despite these scaling limits, we find intrinsic rewards remain valuable in test-time training on small datasets, and propose Model Collapse Step to measure model prior, serving as a practical indicator for RL trainability. Finally, we explore external reward methods that ground verification in computational asymmetries, showing preliminary evidence they may escape the confidence-correctness ceiling. Our findings chart boundaries for intrinsic URLVR while motivating paths toward scalable alternatives.
Flow of Spans: Generalizing Language Models to Dynamic Span-Vocabulary via GFlowNets
Feb 11, 2026Standard autoregressive language models generate text token-by-token from a fixed vocabulary, inducing a tree-structured state space when viewing token sampling as an action, which limits flexibility and expressiveness. Recent work introduces dynamic vocabulary by sampling retrieved text spans but overlooks that the same sentence can be composed of spans of varying lengths, lacking explicit modeling of the directed acyclic graph (DAG) state space. This leads to restricted exploration of compositional paths and is biased toward the chosen path. Generative Flow Networks (GFlowNets) are powerful for efficient exploring and generalizing over state spaces, particularly those with a DAG structure. However, prior GFlowNets-based language models operate at the token level and remain confined to tree-structured spaces, limiting their potential. In this work, we propose Flow of SpanS (FOSS), a principled GFlowNets framework for span generation. FoSS constructs a dynamic span vocabulary by segmenting the retrieved text flexibly, ensuring a DAG-structured state space, which allows GFlowNets to explore diverse compositional paths and improve generalization. With specialized reward models, FoSS generates diverse, high-quality text. Empirically, FoSS improves MAUVE scores by up to 12.5% over Transformer on text generation and achieves 3.5% gains on knowledge-intensive tasks, consistently outperforming state-of-the-art methods. Scaling experiments further demonstrate FoSS benefits from larger models, more data, and richer retrieval corpora, retaining its advantage over strong baselines.
SEMA: Simple yet Effective Learning for Multi-Turn Jailbreak Attacks
Feb 06, 2026Multi-turn jailbreaks capture the real threat model for safety-aligned chatbots, where single-turn attacks are merely a special case. Yet existing approaches break under exploration complexity and intent drift. We propose SEMA, a simple yet effective framework that trains a multi-turn attacker without relying on any existing strategies or external data. SEMA comprises two stages. Prefilling self-tuning enables usable rollouts by fine-tuning on non-refusal, well-structured, multi-turn adversarial prompts that are self-generated with a minimal prefix, thereby stabilizing subsequent learning. Reinforcement learning with intent-drift-aware reward trains the attacker to elicit valid multi-turn adversarial prompts while maintaining the same harmful objective. We anchor harmful intent in multi-turn jailbreaks via an intent-drift-aware reward that combines intent alignment, compliance risk, and level of detail. Our open-loop attack regime avoids dependence on victim feedback, unifies single- and multi-turn settings, and reduces exploration complexity. Across multiple datasets, victim models, and jailbreak judges, our method achieves state-of-the-art (SOTA) attack success rates (ASR), outperforming all single-turn baselines, manually scripted and template-driven multi-turn baselines, as well as our SFT (Supervised Fine-Tuning) and DPO (Direct Preference Optimization) variants. For instance, SEMA performs an average $80.1\%$ ASR@1 across three closed-source and open-source victim models on AdvBench, 33.9% over SOTA. The approach is compact, reproducible, and transfers across targets, providing a stronger and more realistic stress test for large language model (LLM) safety and enabling automatic redteaming to expose and localize failure modes. Our code is available at: https://github.com/fmmarkmq/SEMA.
Controlling Exploration-Exploitation in GFlowNets via Markov Chain Perspectives
Feb 03, 2026Generative Flow Network (GFlowNet) objectives implicitly fix an equal mixing of forward and backward policies, potentially constraining the exploration-exploitation trade-off during training. By further exploring the link between GFlowNets and Markov chains, we establish an equivalence between GFlowNet objectives and Markov chain reversibility, thereby revealing the origin of such constraints, and provide a framework for adapting Markov chain properties to GFlowNets. Building on these theoretical findings, we propose $α$-GFNs, which generalize the mixing via a tunable parameter $α$. This generalization enables direct control over exploration-exploitation dynamics to enhance mode discovery capabilities, while ensuring convergence to unique flows. Across various benchmarks, including Set, Bit Sequence, and Molecule Generation, $α$-GFN objectives consistently outperform previous GFlowNet objectives, achieving up to a $10 \times$ increase in the number of discovered modes.
FlowRL: Matching Reward Distributions for LLM Reasoning
Sep 18, 2025We propose FlowRL: matching the full reward distribution via flow balancing instead of maximizing rewards in large language model (LLM) reinforcement learning (RL). Recent advanced reasoning models adopt reward-maximizing methods (\eg, PPO and GRPO), which tend to over-optimize dominant reward signals while neglecting less frequent but valid reasoning paths, thus reducing diversity. In contrast, we transform scalar rewards into a normalized target distribution using a learnable partition function, and then minimize the reverse KL divergence between the policy and the target distribution. We implement this idea as a flow-balanced optimization method that promotes diverse exploration and generalizable reasoning trajectories. We conduct experiments on math and code reasoning tasks: FlowRL achieves a significant average improvement of $10.0\%$ over GRPO and $5.1\%$ over PPO on math benchmarks, and performs consistently better on code reasoning tasks. These results highlight reward distribution-matching as a key step toward efficient exploration and diverse reasoning in LLM reinforcement learning.
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
Sep 11, 2025Vision-Language-Action (VLA) models have recently emerged as a powerful paradigm for robotic manipulation. Despite substantial progress enabled by large-scale pretraining and supervised fine-tuning (SFT), these models face two fundamental challenges: (i) the scarcity and high cost of large-scale human-operated robotic trajectories required for SFT scaling, and (ii) limited generalization to tasks involving distribution shift. Recent breakthroughs in Large Reasoning Models (LRMs) demonstrate that reinforcement learning (RL) can dramatically enhance step-by-step reasoning capabilities, raising a natural question: Can RL similarly improve the long-horizon step-by-step action planning of VLA? In this work, we introduce SimpleVLA-RL, an efficient RL framework tailored for VLA models. Building upon veRL, we introduce VLA-specific trajectory sampling, scalable parallelization, multi-environment rendering, and optimized loss computation. When applied to OpenVLA-OFT, SimpleVLA-RL achieves SoTA performance on LIBERO and even outperforms $\pi_0$ on RoboTwin 1.0\&2.0 with the exploration-enhancing strategies we introduce. SimpleVLA-RL not only reduces dependence on large-scale data and enables robust generalization, but also remarkably surpasses SFT in real-world tasks. Moreover, we identify a novel phenomenon ``pushcut'' during RL training, wherein the policy discovers previously unseen patterns beyond those seen in the previous training process. Github: https://github.com/PRIME-RL/SimpleVLA-RL
A Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
Towards a Unified View of Large Language Model Post-Training
Sep 04, 2025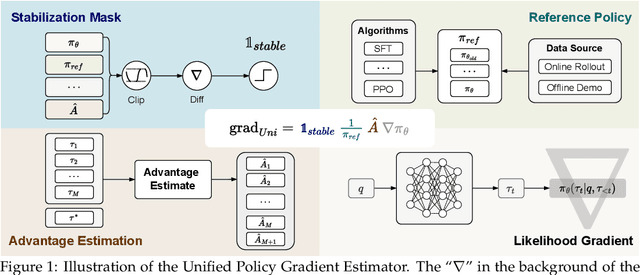

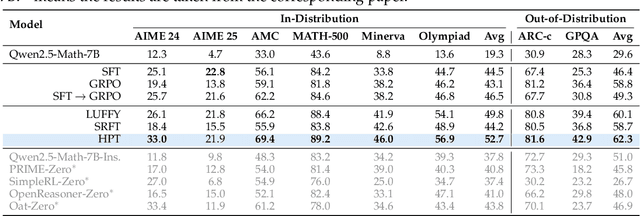
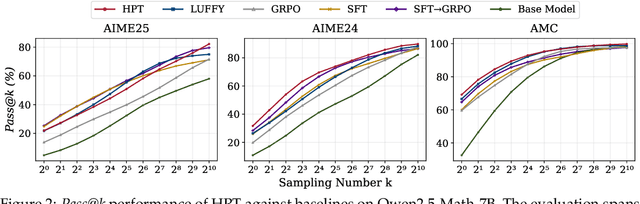
Two major sources of training data exist for post-training modern language models: online (model-generated rollouts) data, and offline (human or other-model demonstrations) data. These two types of data are typically used by approaches like Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT), respectively. In this paper, we show that these approaches are not in contradiction, but are instances of a single optimization process. We derive a Unified Policy Gradient Estimator, and present the calculations of a wide spectrum of post-training approaches as the gradient of a common objective under different data distribution assumptions and various bias-variance tradeoffs. The gradient estimator is constructed with four interchangeable parts: stabilization mask, reference policy denominator, advantage estimate, and likelihood gradient. Motivated by our theoretical findings, we propose Hybrid Post-Training (HPT), an algorithm that dynamically selects different training signals. HPT is designed to yield both effective exploitation of demonstration and stable exploration without sacrificing learned reasoning patterns. We provide extensive experiments and ablation studies to verify the effectiveness of our unified theoretical framework and HPT. Across six mathematical reasoning benchmarks and two out-of-distribution suites, HPT consistently surpasses strong baselines across models of varying scales and families.
Reasoning with Exploration: An Entropy Perspective
Jun 17, 2025Balancing exploration and exploitation is a central goal in reinforcement learning (RL). Despite recent advances in enhancing language model (LM) reasoning, most methods lean toward exploitation, and increasingly encounter performance plateaus. In this work, we revisit entropy -- a signal of exploration in RL -- and examine its relationship to exploratory reasoning in LMs. Through empirical analysis, we uncover strong positive correlations between high-entropy regions and three types of exploratory reasoning actions: (1) pivotal tokens that determine or connect logical steps, (2) reflective actions such as self-verification and correction, and (3) rare behaviors under-explored by the base LMs. Motivated by this, we introduce a minimal modification to standard RL with only one line of code: augmenting the advantage function with an entropy-based term. Unlike traditional maximum-entropy methods which encourage exploration by promoting uncertainty, we encourage exploration by promoting longer and deeper reasoning chains. Notably, our method achieves significant gains on the Pass@K metric -- an upper-bound estimator of LM reasoning capabilities -- even when evaluated with extremely large K values, pushing the boundaries of LM reasoning.