 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFGML-DG: Feynman-Inspired Cognitive Science Paradigm for Cross-Domain Medical Image Segmentation
Apr 12, 2026In medical image segmentation across multiple modalities (e.g., MRI, CT, etc.) and heterogeneous data sources (e.g., different hospitals and devices), Domain Generalization (DG) remains a critical challenge in AI-driven healthcare. This challenge primarily arises from domain shifts, imaging variations, and patient diversity, which often lead to degraded model performance in unseen domains. To address these limitations, we identify key issues in existing methods, including insufficient simplification of complex style features, inadequate reuse of domain knowledge, and a lack of feedback-driven optimization. To tackle these problems, inspired by Feynman's learning techniques in educational psychology, this paper introduces a cognitive science-inspired meta-learning paradigm for medical image domain generalization segmentation. We propose, for the first time, a cognitive-inspired Feynman-Guided Meta-Learning framework for medical image domain generalization segmentation (FGML-DG), which mimics human cognitive learning processes to enhance model learning and knowledge transfer. Specifically, we first leverage the 'concept understanding' principle from Feynman's learning method to simplify complex features across domains into style information statistics, achieving precise style feature alignment. Second, we design a meta-style memory and recall method (MetaStyle) to emulate the human memory system's utilization of past knowledge. Finally, we incorporate a Feedback-Driven Re-Training strategy (FDRT), which mimics Feynman's emphasis on targeted relearning, enabling the model to dynamically adjust learning focus based on prediction errors. Experimental results demonstrate that our method outperforms other existing domain generalization approaches on two challenging medical image domain generalization tasks.
QAQ: Bidirectional Semantic Coherence for Selecting High-Quality Synthetic Code Instructions
Mar 12, 2026Synthetic data has become essential for training code generation models, yet it introduces significant noise and hallucinations that are difficult to detect with current metrics. Existing data selection methods like Instruction-Following Difficulty (IFD) typically assess how hard a model generates an answer given a query ($A|Q$). However, this metric is ambiguous on noisy synthetic data, where low probability can distinguish between intrinsic task complexity and model-generated hallucinations. Here, we propose QAQ, a novel data selection framework that evaluates data quality from the reverse direction: how well can the answer predict the query ($Q|A$)? We define Reverse Mutual Information (RMI) to quantify the information gain about the query conditioned on the answer. Our analyses reveal that both extremes of RMI signal quality issues: low RMI indicates semantic misalignment, while excessively high RMI may contain defect patterns that LLMs easily recognize. Furthermore, we introduce a selection strategy based on the disagreement between strong and weak models to identify samples that are valid yet challenging. Experiments on the WarriorCoder dataset demonstrate that selecting just 25% of data using stratified RMI achieves comparable performance to full-data training, significantly outperforming existing data selection methods. Our approach highlights the importance of bidirectional semantic coherence in synthetic data curation, offering a scalable pathway to reduce computational costs without sacrificing model capability.
Models as Lego Builders: Assembling Malice from Benign Blocks via Semantic Blueprints
Mar 08, 2026Despite the rapid progress of Large Vision-Language Models (LVLMs), the integration of visual modalities introduces new safety vulnerabilities that adversaries can exploit to elicit biased or malicious outputs. In this paper, we demonstrate an underexplored vulnerability via semantic slot filling, where LVLMs complete missing slot values with unsafe content even when the slot types are deliberately crafted to appear benign. Building on this finding, we propose StructAttack, a simple yet effective single-query jailbreak framework under black-box settings. StructAttack decomposes a harmful query into a central topic and a set of benign-looking slot types, then embeds them as structured visual prompts (e.g., mind maps, tables, or sunburst diagrams) with small random perturbations. Paired with a completion-guided instruction, LVLMs automatically recompose the concealed semantics and generate unsafe outputs without triggering safety mechanisms. Although each slot appears benign in isolation (local benignness), StructAttack exploits LVLMs' reasoning to assemble these slots into coherent harmful semantics. Extensive experiments on multiple models and benchmarks show the efficacy of our proposed StructAttack.
UltraStar: Semantic-Aware Star Graph Modeling for Echocardiography Navigation
Mar 02, 2026Echocardiography is critical for diagnosing cardiovascular diseases, yet the shortage of skilled sonographers hinders timely patient care, due to high operational difficulties. Consequently, research on automated probe navigation has significant clinical potential. To achieve robust navigation, it is essential to leverage historical scanning information, mimicking how experts rely on past feedback to adjust subsequent maneuvers. Practical scanning data collected from sonographers typically consists of noisy trajectories inherently generated through trial-and-error exploration. However, existing methods typically model this history as a sequential chain, forcing models to overfit these noisy paths, leading to performance degradation on long sequences. In this paper, we propose UltraStar, which reformulates probe navigation from path regression to anchor-based global localization. By establishing a Star Graph, UltraStar treats historical keyframes as spatial anchors connected directly to the current view, explicitly modeling geometric constraints for precise positioning. We further enhance the Star Graph with a semantic-aware sampling strategy that actively selects the representative landmarks from massive history logs, reducing redundancy for accurate anchoring. Extensive experiments on a dataset with over 1.31 million samples demonstrate that UltraStar outperforms baselines and scales better with longer input lengths, revealing a more effective topology for history modeling under noisy exploration.
DenoiseFlow: Uncertainty-Aware Denoising for Reliable LLM Agentic Workflows
Feb 28, 2026Autonomous agents are increasingly entrusted with complex, long-horizon tasks, ranging from mathematical reasoning to software generation. While agentic workflows facilitate these tasks by decomposing them into multi-step reasoning chains, reliability degrades significantly as the sequence lengthens. Specifically, minor interpretation errors in natural-language instructions tend to compound silently across steps. We term this failure mode accumulated semantic ambiguity. Existing approaches to mitigate this often lack runtime adaptivity, relying instead on static exploration budgets, reactive error recovery, or single-path execution that ignores uncertainty entirely. We formalize the multi-step reasoning process as a Noisy MDP and propose DenoiseFlow, a closed-loop framework that performs progressive denoising through three coordinated stages: (1)Sensing estimates per-step semantic uncertainty; (2)Regulating adaptively allocates computation by routing between fast single-path execution and parallel exploration based on estimated risk; and (3)Correcting performs targeted recovery via influence-based root-cause localization. Online self-calibration continuously aligns decision boundaries with verifier feedback, requiring no ground-truth labels. Experiments on six benchmarks spanning mathematical reasoning, code generation, and multi-hop QA show that DenoiseFlow achieves the highest accuracy on every benchmark (83.3% average, +1.3% over the strongest baseline) while reducing cost by 40--56% through adaptive branching. Detailed ablation studies further confirm framework-level's robustness and generality. Code is available at https://anonymous.4open.science/r/DenoiseFlow-21D3/.
P1-VL: Bridging Visual Perception and Scientific Reasoning in Physics Olympiads
Feb 10, 2026The transition from symbolic manipulation to science-grade reasoning represents a pivotal frontier for Large Language Models (LLMs), with physics serving as the critical test anchor for binding abstract logic to physical reality. Physics demands that a model maintain physical consistency with the laws governing the universe, a task that fundamentally requires multimodal perception to ground abstract logic in reality. At the Olympiad level, diagrams are often constitutive rather than illustrative, containing essential constraints, such as boundary conditions and spatial symmetries, that are absent from the text. To bridge this visual-logical gap, we introduce P1-VL, a family of open-source vision-language models engineered for advanced scientific reasoning. Our method harmonizes Curriculum Reinforcement Learning, which employs progressive difficulty expansion to stabilize post-training, with Agentic Augmentation, enabling iterative self-verification at inference. Evaluated on HiPhO, a rigorous benchmark of 13 exams from 2024-2025, our flagship P1-VL-235B-A22B becomes the first open-source Vision-Language Model (VLM) to secure 12 gold medals and achieves the state-of-the-art performance in the open-source models. Our agent-augmented system achieves the No.2 overall rank globally, trailing only Gemini-3-Pro. Beyond physics, P1-VL demonstrates remarkable scientific reasoning capacity and generalizability, establishing significant leads over base models in STEM benchmarks. By open-sourcing P1-VL, we provide a foundational step toward general-purpose physical intelligence to better align visual perceptions with abstract physical laws for machine scientific discovery.
GEBench: Benchmarking Image Generation Models as GUI Environments
Feb 09, 2026Recent advancements in image generation models have enabled the prediction of future Graphical User Interface (GUI) states based on user instructions. However, existing benchmarks primarily focus on general domain visual fidelity, leaving the evaluation of state transitions and temporal coherence in GUI-specific contexts underexplored. To address this gap, we introduce GEBench, a comprehensive benchmark for evaluating dynamic interaction and temporal coherence in GUI generation. GEBench comprises 700 carefully curated samples spanning five task categories, covering both single-step interactions and multi-step trajectories across real-world and fictional scenarios, as well as grounding point localization. To support systematic evaluation, we propose GE-Score, a novel five-dimensional metric that assesses Goal Achievement, Interaction Logic, Content Consistency, UI Plausibility, and Visual Quality. Extensive evaluations on current models indicate that while they perform well on single-step transitions, they struggle significantly with maintaining temporal coherence and spatial grounding over longer interaction sequences. Our findings identify icon interpretation, text rendering, and localization precision as critical bottlenecks. This work provides a foundation for systematic assessment and suggests promising directions for future research toward building high-fidelity generative GUI environments. The code is available at: https://github.com/stepfun-ai/GEBench.
OrthoGeoLoRA: Geometric Parameter-Efficient Fine-Tuning for Structured Social Science Concept Retrieval on theWeb
Jan 14, 2026Large language models and text encoders increasingly power web-based information systems in the social sciences, including digital libraries, data catalogues, and search interfaces used by researchers, policymakers, and civil society. Full fine-tuning is often computationally and energy intensive, which can be prohibitive for smaller institutions and non-profit organizations in the Web4Good ecosystem. Parameter-Efficient Fine-Tuning (PEFT), especially Low-Rank Adaptation (LoRA), reduces this cost by updating only a small number of parameters. We show that the standard LoRA update $ΔW = BA^\top$ has geometric drawbacks: gauge freedom, scale ambiguity, and a tendency toward rank collapse. We introduce OrthoGeoLoRA, which enforces an SVD-like form $ΔW = BΣA^\top$ by constraining the low-rank factors to be orthogonal (Stiefel manifold). A geometric reparameterization implements this constraint while remaining compatible with standard optimizers such as Adam and existing fine-tuning pipelines. We also propose a benchmark for hierarchical concept retrieval over the European Language Social Science Thesaurus (ELSST), widely used to organize social science resources in digital repositories. Experiments with a multilingual sentence encoder show that OrthoGeoLoRA outperforms standard LoRA and several strong PEFT variants on ranking metrics under the same low-rank budget, offering a more compute- and parameter-efficient path to adapt foundation models in resource-constrained settings.
BEDA: Belief Estimation as Probabilistic Constraints for Performing Strategic Dialogue Acts
Dec 31, 2025Strategic dialogue requires agents to execute distinct dialogue acts, for which belief estimation is essential. While prior work often estimates beliefs accurately, it lacks a principled mechanism to use those beliefs during generation. We bridge this gap by first formalizing two core acts Adversarial and Alignment, and by operationalizing them via probabilistic constraints on what an agent may generate. We instantiate this idea in BEDA, a framework that consists of the world set, the belief estimator for belief estimation, and the conditional generator that selects acts and realizes utterances consistent with the inferred beliefs. Across three settings, Conditional Keeper Burglar (CKBG, adversarial), Mutual Friends (MF, cooperative), and CaSiNo (negotiation), BEDA consistently outperforms strong baselines: on CKBG it improves success rate by at least 5.0 points across backbones and by 20.6 points with GPT-4.1-nano; on Mutual Friends it achieves an average improvement of 9.3 points; and on CaSiNo it achieves the optimal deal relative to all baselines. These results indicate that casting belief estimation as constraints provides a simple, general mechanism for reliable strategic dialogue.
Physics-Constrained Diffusion Reconstruction with Posterior Correction for Quantitative and Fast PET Imaging
Aug 20, 2025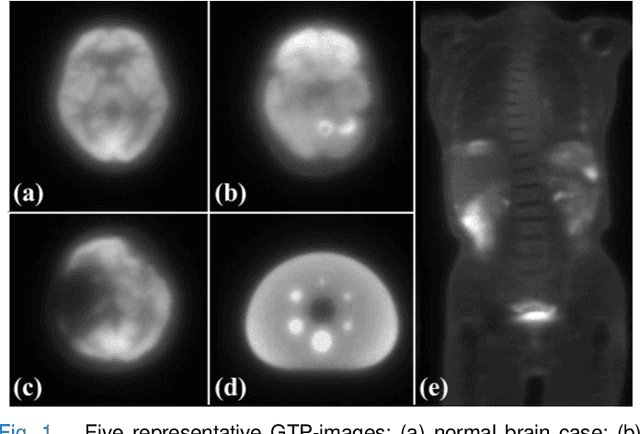
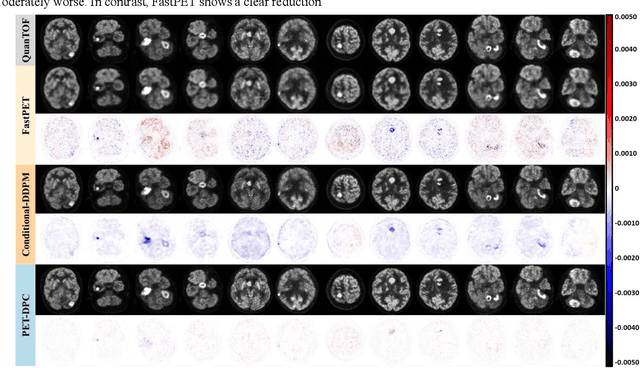
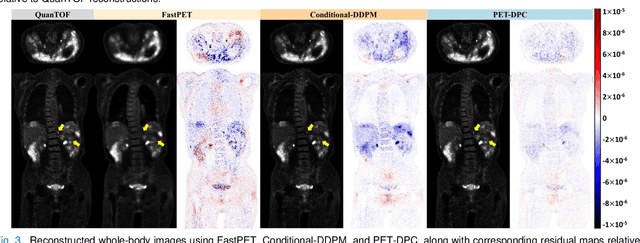
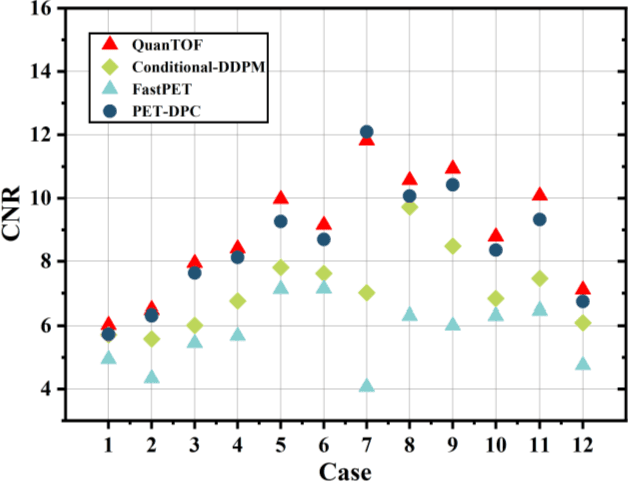
Deep learning-based reconstruction of positron emission tomography(PET) data has gained increasing attention in recent years. While these methods achieve fast reconstruction,concerns remain regarding quantitative accuracy and the presence of artifacts,stemming from limited model interpretability,data driven dependence, and overfitting risks.These challenges have hindered clinical adoption.To address them,we propose a conditional diffusion model with posterior physical correction (PET-DPC) for PET image reconstruction. An innovative normalization procedure generates the input Geometric TOF Probabilistic Image (GTP-image),while physical information is incorporated during the diffusion sampling process to perform posterior scatter,attenuation,and random corrections. The model was trained and validated on 300 brain and 50 whole-body PET datasets,a physical phantom,and 20 simulated brain datasets. PET-DPC produced reconstructions closely aligned with fully corrected OSEM images,outperforming end-to-end deep learning models in quantitative metrics and,in some cases, surpassing traditional iterative methods. The model also generalized well to out-of-distribution(OOD) data. Compared to iterative methods,PET-DPC reduced reconstruction time by 50% for brain scans and 85% for whole-body scans. Ablation studies confirmed the critical role of posterior correction in implementing scatter and attenuation corrections,enhancing reconstruction accuracy. Experiments with physical phantoms further demonstrated PET-DPC's ability to preserve background uniformity and accurately reproduce tumor-to-background intensity ratios. Overall,these results highlight PET-DPC as a promising approach for rapid, quantitatively accurate PET reconstruction,with strong potential to improve clinical imaging workflows.