 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Gradient-based Adversarial Attacks on Point Cloud Classification
May 28, 2025Gradient-based adversarial attacks have become a dominant approach for evaluating the robustness of point cloud classification models. However, existing methods often rely on uniform update rules that fail to consider the heterogeneous nature of point clouds, resulting in excessive and perceptible perturbations. In this paper, we rethink the design of gradient-based attacks by analyzing the limitations of conventional gradient update mechanisms and propose two new strategies to improve both attack effectiveness and imperceptibility. First, we introduce WAAttack, a novel framework that incorporates weighted gradients and an adaptive step-size strategy to account for the non-uniform contribution of points during optimization. This approach enables more targeted and subtle perturbations by dynamically adjusting updates according to the local structure and sensitivity of each point. Second, we propose SubAttack, a complementary strategy that decomposes the point cloud into subsets and focuses perturbation efforts on structurally critical regions. Together, these methods represent a principled rethinking of gradient-based adversarial attacks for 3D point cloud classification. Extensive experiments demonstrate that our approach outperforms state-of-the-art baselines in generating highly imperceptible adversarial examples. Code will be released upon paper acceptance.
LLM-Guided Taxonomy and Hierarchical Uncertainty for 3D Point CLoud Active Learning
May 25, 2025We present a novel active learning framework for 3D point cloud semantic segmentation that, for the first time, integrates large language models (LLMs) to construct hierarchical label structures and guide uncertainty-based sample selection. Unlike prior methods that treat labels as flat and independent, our approach leverages LLM prompting to automatically generate multi-level semantic taxonomies and introduces a recursive uncertainty projection mechanism that propagates uncertainty across hierarchy levels. This enables spatially diverse, label-aware point selection that respects the inherent semantic structure of 3D scenes. Experiments on S3DIS and ScanNet v2 show that our method achieves up to 4% mIoU improvement under extremely low annotation budgets (e.g., 0.02%), substantially outperforming existing baselines. Our results highlight the untapped potential of LLMs as knowledge priors in 3D vision and establish hierarchical uncertainty modeling as a powerful paradigm for efficient point cloud annotation.
Less is More: Efficient Point Cloud Reconstruction via Multi-Head Decoders
May 25, 2025We challenge the common assumption that deeper decoder architectures always yield better performance in point cloud reconstruction. Our analysis reveals that, beyond a certain depth, increasing decoder complexity leads to overfitting and degraded generalization. Additionally, we propose a novel multi-head decoder architecture that exploits the inherent redundancy in point clouds by reconstructing complete shapes from multiple independent heads, each operating on a distinct subset of points. The final output is obtained by concatenating the predictions from all heads, enhancing both diversity and fidelity. Extensive experiments on ModelNet40 and ShapeNetPart demonstrate that our approach achieves consistent improvements across key metrics--including Chamfer Distance (CD), Hausdorff Distance (HD), Earth Mover's Distance (EMD), and F1-score--outperforming standard single-head baselines. Our findings highlight that output diversity and architectural design can be more critical than depth alone for effective and efficient point cloud reconstruction.
Controllable 3D Outdoor Scene Generation via Scene Graphs
Mar 10, 2025Three-dimensional scene generation is crucial in computer vision, with applications spanning autonomous driving, gaming and the metaverse. Current methods either lack user control or rely on imprecise, non-intuitive conditions. In this work, we propose a method that uses, scene graphs, an accessible, user friendly control format to generate outdoor 3D scenes. We develop an interactive system that transforms a sparse scene graph into a dense BEV (Bird's Eye View) Embedding Map, which guides a conditional diffusion model to generate 3D scenes that match the scene graph description. During inference, users can easily create or modify scene graphs to generate large-scale outdoor scenes. We create a large-scale dataset with paired scene graphs and 3D semantic scenes to train the BEV embedding and diffusion models. Experimental results show that our approach consistently produces high-quality 3D urban scenes closely aligned with the input scene graphs. To the best of our knowledge, this is the first approach to generate 3D outdoor scenes conditioned on scene graphs.
Enhancing Sampling Protocol for Robust Point Cloud Classification
Aug 22, 2024Established sampling protocols for 3D point cloud learning, such as Farthest Point Sampling (FPS) and Fixed Sample Size (FSS), have long been recognized and utilized. However, real-world data often suffer from corrputions such as sensor noise, which violates the benignness assumption of point cloud in current protocols. Consequently, they are notably vulnerable to noise, posing significant safety risks in critical applications like autonomous driving. To address these issues, we propose an enhanced point cloud sampling protocol, PointDR, which comprises two components: 1) Downsampling for key point identification and 2) Resampling for flexible sample size. Furthermore, differentiated strategies are implemented for training and inference processes. Particularly, an isolation-rated weight considering local density is designed for the downsampling method, assisting it in performing random key points selection in the training phase and bypassing noise in the inference phase. A local-geometry-preserved upsampling is incorporated into resampling, facilitating it to maintain a stochastic sample size in the training stage and complete insufficient data in the inference. It is crucial to note that the proposed protocol is free of model architecture altering and extra learning, thus minimal efforts are demanded for its replacement of the existing one. Despite the simplicity, it substantially improves the robustness of point cloud learning, showcased by outperforming the state-of-the-art methods on multiple benchmarks of corrupted point cloud classification. The code will be available upon the paper's acceptance.
Pyramid Diffusion for Fine 3D Large Scene Generation
Nov 20, 2023
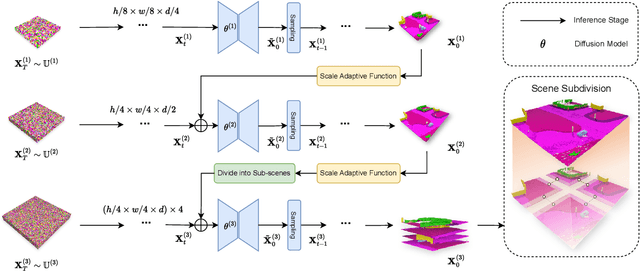
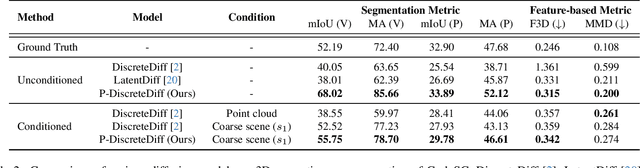

Directly transferring the 2D techniques to 3D scene generation is challenging due to significant resolution reduction and the scarcity of comprehensive real-world 3D scene datasets. To address these issues, our work introduces the Pyramid Discrete Diffusion model (PDD) for 3D scene generation. This novel approach employs a multi-scale model capable of progressively generating high-quality 3D scenes from coarse to fine. In this way, the PDD can generate high-quality scenes within limited resource constraints and does not require additional data sources. To the best of our knowledge, we are the first to adopt the simple but effective coarse-to-fine strategy for 3D large scene generation. Our experiments, covering both unconditional and conditional generation, have yielded impressive results, showcasing the model's effectiveness and robustness in generating realistic and detailed 3D scenes. Our code will be available to the public.
An Exponential Factorization Machine with Percentage Error Minimization to Retail Sales Forecasting
Sep 22, 2020
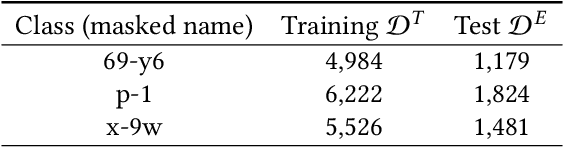

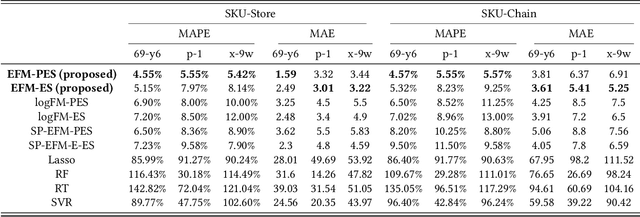
This paper proposes a new approach to sales forecasting for new products with long lead time but short product life cycle. These SKUs are usually sold for one season only, without any replenishments. An exponential factorization machine (EFM) sales forecast model is developed to solve this problem which not only considers SKU attributes, but also pairwise interactions. The EFM model is significantly different from the original Factorization Machines (FM) from two-fold: (1) the attribute-level formulation for explanatory variables and (2) exponential formulation for the positive response variable. The attribute-level formation excludes infeasible intra-attribute interactions and results in more efficient feature engineering comparing with the conventional one-hot encoding, while the exponential formulation is demonstrated more effective than the log-transformation for the positive but not skewed distributed responses. In order to estimate the parameters, percentage error squares (PES) and error squares (ES) are minimized by a proposed adaptive batch gradient descent method over the training set. Real-world data provided by a footwear retailer in Singapore is used for testing the proposed approach. The forecasting performance in terms of both mean absolute percentage error (MAPE) and mean absolute error (MAE) compares favourably with not only off-the-shelf models but also results reported by extant sales and demand forecasting studies. The effectiveness of the proposed approach is also demonstrated by two external public datasets. Moreover, we prove the theoretical relationships between PES and ES minimization, and present an important property of the PES minimization for regression models; that it trains models to underestimate data. This property fits the situation of sales forecasting where unit-holding cost is much greater than the unit-shortage cost.
* Accepted by ACM Transactions on Knowledge Discovery from Data (ACM TKDD)
Revisiting Modified Greedy Algorithm for Monotone Submodular Maximization with a Knapsack Constraint
Aug 12, 2020

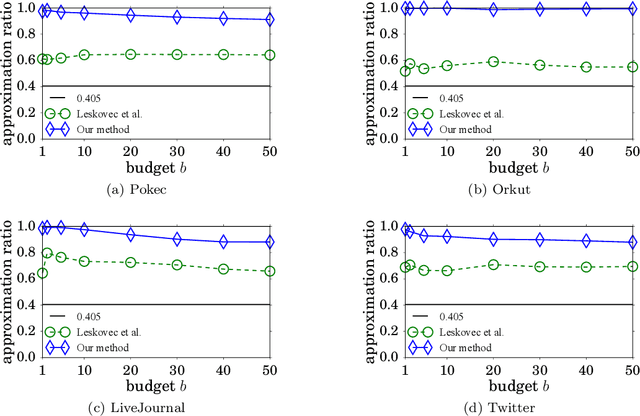
Monotone submodular maximization with a knapsack constraint is NP-hard. Various approximation algorithms have been devised to address this optimization problem. In this paper, we revisit the widely known modified greedy algorithm. First, we show that this algorithm can achieve an approximation factor of $0.405$, which significantly improves the known factor of $0.357$ given by Wolsey or $(1-1/\mathrm{e})/2\approx 0.316$ given by Khuller et al. More importantly, our analysis uncovers a gap in Khuller et al.'s proof for the extensively mentioned approximation factor of $(1-1/\sqrt{\mathrm{e}})\approx 0.393$ in the literature to clarify a long time of misunderstanding on this issue. Second, we enhance the modified greedy algorithm to derive a data-dependent upper bound on the optimum. We empirically demonstrate the tightness of our upper bound with a real-world application. The bound enables us to obtain a data-dependent ratio typically much higher than $0.405$ between the solution value of the modified greedy algorithm and the optimum. It can also be used to significantly improve the efficiency of algorithms such as branch and bound.
Campus3D: A Photogrammetry Point Cloud Benchmark for Hierarchical Understanding of Outdoor Scene
Aug 11, 2020
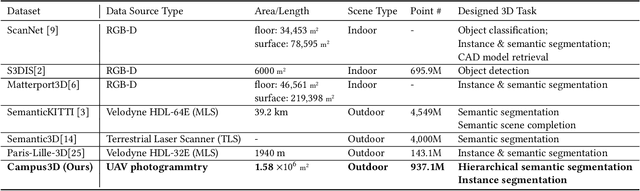

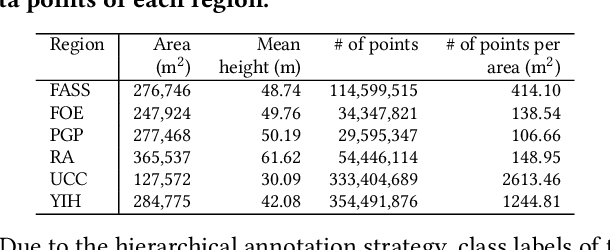
Learning on 3D scene-based point cloud has received extensive attention as its promising application in many fields, and well-annotated and multisource datasets can catalyze the development of those data-driven approaches. To facilitate the research of this area, we present a richly-annotated 3D point cloud dataset for multiple outdoor scene understanding tasks and also an effective learning framework for its hierarchical segmentation task. The dataset was generated via the photogrammetric processing on unmanned aerial vehicle (UAV) images of the National University of Singapore (NUS) campus, and has been point-wisely annotated with both hierarchical and instance-based labels. Based on it, we formulate a hierarchical learning problem for 3D point cloud segmentation and propose a measurement evaluating consistency across various hierarchies. To solve this problem, a two-stage method including multi-task (MT) learning and hierarchical ensemble (HE) with consistency consideration is proposed. Experimental results demonstrate the superiority of the proposed method and potential advantages of our hierarchical annotations. In addition, we benchmark results of semantic and instance segmentation, which is accessible online at https://3d.dataset.site with the dataset and all source codes.
* Accepted by the 28th ACM International Conference on Multimedia (ACM MM 2020)
WeText: Scene Text Detection under Weak Supervision
Oct 13, 2017
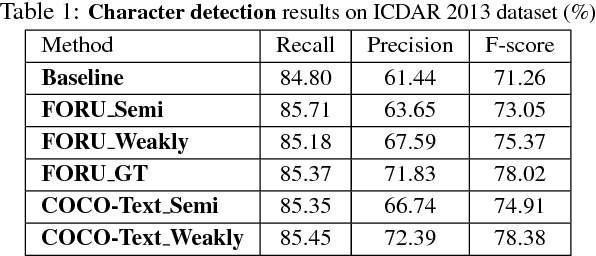
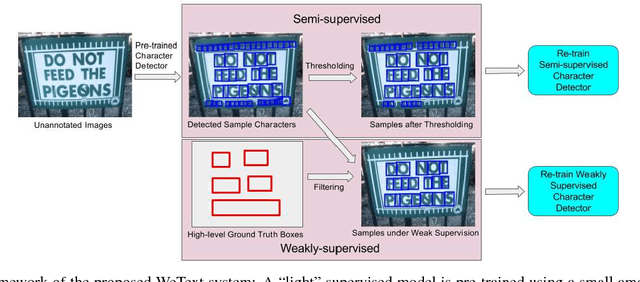
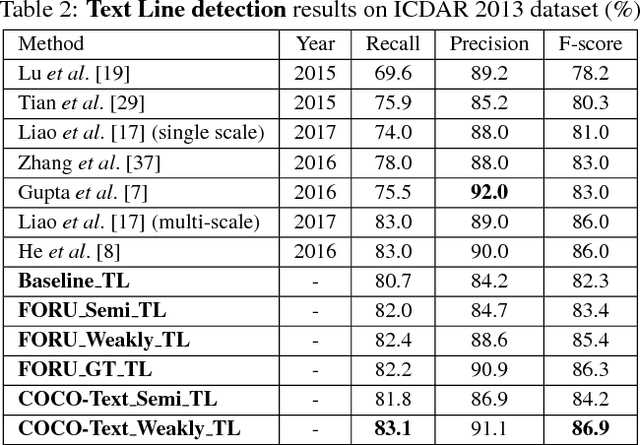
The requiring of large amounts of annotated training data has become a common constraint on various deep learning systems. In this paper, we propose a weakly supervised scene text detection method (WeText) that trains robust and accurate scene text detection models by learning from unannotated or weakly annotated data. With a "light" supervised model trained on a small fully annotated dataset, we explore semi-supervised and weakly supervised learning on a large unannotated dataset and a large weakly annotated dataset, respectively. For the unsupervised learning, the light supervised model is applied to the unannotated dataset to search for more character training samples, which are further combined with the small annotated dataset to retrain a superior character detection model. For the weakly supervised learning, the character searching is guided by high-level annotations of words/text lines that are widely available and also much easier to prepare. In addition, we design an unified scene character detector by adapting regression based deep networks, which greatly relieves the error accumulation issue that widely exists in most traditional approaches. Extensive experiments across different unannotated and weakly annotated datasets show that the scene text detection performance can be clearly boosted under both scenarios, where the weakly supervised learning can achieve the state-of-the-art performance by using only 229 fully annotated scene text images.