 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Efficient Point Cloud Reconstruction via Multi-Head Decoders
May 25, 2025We challenge the common assumption that deeper decoder architectures always yield better performance in point cloud reconstruction. Our analysis reveals that, beyond a certain depth, increasing decoder complexity leads to overfitting and degraded generalization. Additionally, we propose a novel multi-head decoder architecture that exploits the inherent redundancy in point clouds by reconstructing complete shapes from multiple independent heads, each operating on a distinct subset of points. The final output is obtained by concatenating the predictions from all heads, enhancing both diversity and fidelity. Extensive experiments on ModelNet40 and ShapeNetPart demonstrate that our approach achieves consistent improvements across key metrics--including Chamfer Distance (CD), Hausdorff Distance (HD), Earth Mover's Distance (EMD), and F1-score--outperforming standard single-head baselines. Our findings highlight that output diversity and architectural design can be more critical than depth alone for effective and efficient point cloud reconstruction.
HyperEmbed: Tradeoffs Between Resources and Performance in NLP Tasks with Hyperdimensional Computing enabled Embedding of n-gram Statistics
Mar 03, 2020
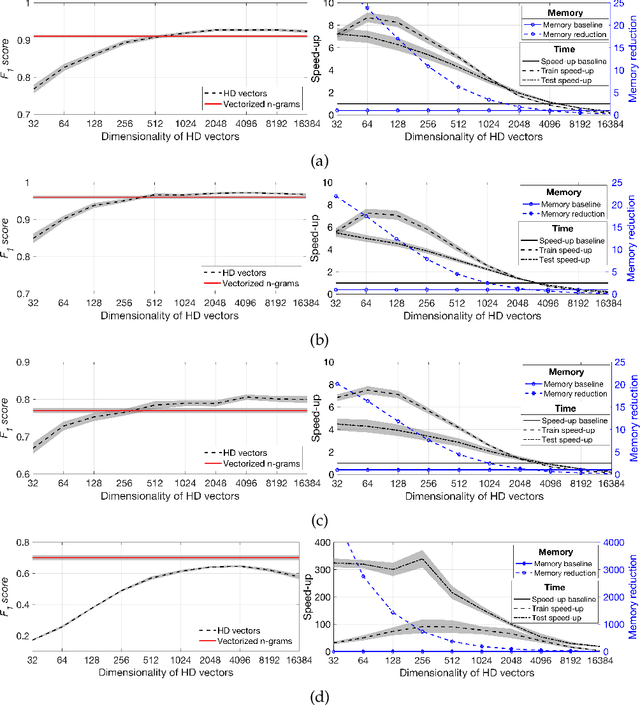
Recent advances in Deep Learning have led to a significant performance increase on several NLP tasks, however, the models become more and more computationally demanding. Therefore, this paper tackles the domain of computationally efficient algorithms for NLP tasks. In particular, it investigates distributed representations of n-gram statistics of texts. The representations are formed using hyperdimensional computing enabled embedding. These representations then serve as features, which are used as input to standard classifiers. We investigate the applicability of the embedding on one large and three small standard datasets for classification tasks using nine classifiers. The embedding achieved on par F1 scores while decreasing the time and memory requirements by several times compared to the conventional n-gram statistics, e.g., for one of the classifiers on a small dataset, the memory reduction was 6.18 times; while train and test speed-ups were 4.62 and 3.84 times, respectively. For many classifiers on the large dataset, the memory reduction was about 100 times and train and test speed-ups were over 100 times. More importantly, the usage of distributed representations formed via hyperdimensional computing allows dissecting the strict dependency between the dimensionality of the representation and the parameters of n-gram statistics, thus, opening a room for tradeoffs.
Subword Semantic Hashing for Intent Classification on Small Datasets
Oct 16, 2018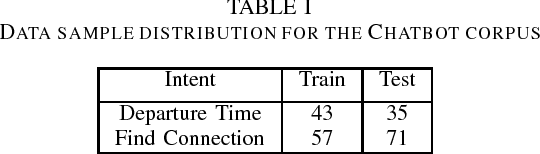

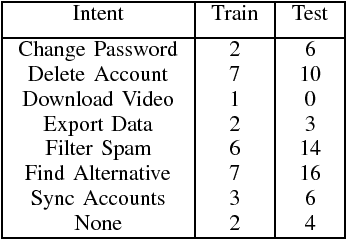
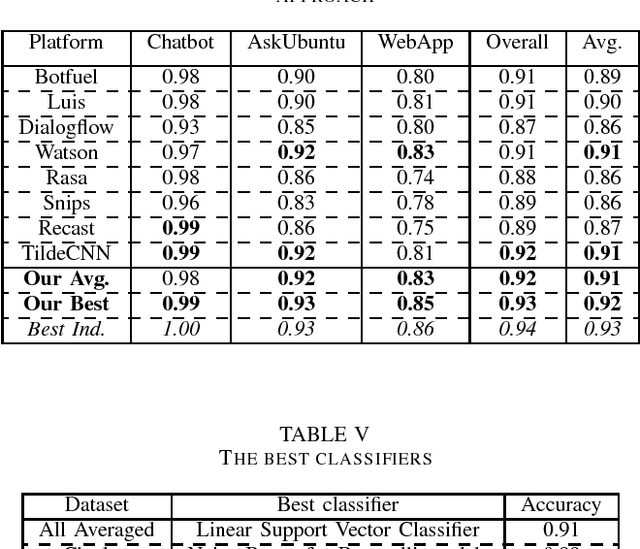
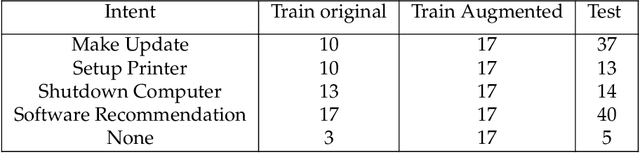
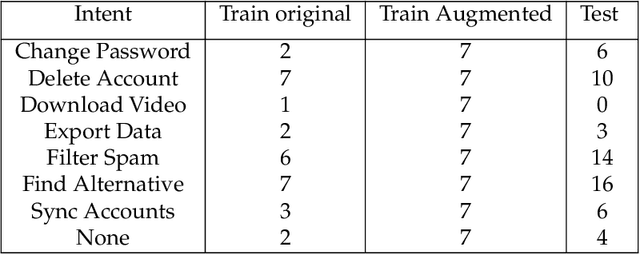
In this paper, we introduce the use of Semantic Hashing as embedding for the task of Intent Classification and outperform previous state-of-the-art methods on three frequently used benchmarks. Intent Classification on a small dataset is a challenging task for data-hungry state-of-the-art Deep Learning based systems. Semantic Hashing is an attempt to overcome such a challenge and learn robust text classification. Current word embedding based methods are dependent on vocabularies. One of the major drawbacks of such methods is out-of-vocabulary terms, especially when having small training datasets and using a wider vocabulary. This is the case in Intent Classification for chatbots, where typically small datasets are extracted from internet communication. Two problems arise by the use of internet communication. First, such datasets miss a lot of terms in the vocabulary to use word embeddings efficiently. Second, users frequently make spelling errors. Typically, the models for intent classification are not trained with spelling errors and it is difficult to think about ways in which users will make mistakes. Models depending on a word vocabulary will always face such issues. An ideal classifier should handle spelling errors inherently. With Semantic Hashing, we overcome these challenges and achieve state-of-the-art results on three datasets: AskUbuntu, Chatbot, and Web Application. Our benchmarks are available online: https://github.com/kumar-shridhar/Know-Your-Intent