 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefusal Before Decoding: Detecting and Exploiting Refusal Signals in Intermediate LLM Activations
May 27, 2026In this paper, we investigate whether refusal behavior can be predicted from LLM intermediate activations before decoding using linear probes trained on residual stream activations at each transformer block. We find that refusal is linearly decodable well before the final layer, indicating that safety-relevant behavior is represented in intermediate activations before output generation. To test whether this signal is actionable, we introduce Mechanistic AutoDAN, a probe-guided variant of AutoDAN that replaces full-model fitness evaluation with partial forward passes and probe-based scoring inside a genetic prompt search loop. Across the evaluated models, our method achieves attack success rates competitive with vanilla AutoDAN while reducing per-iteration search time by up to 72%, and probe-guided prompts match or exceed AutoDAN's cross-model transfer in several configurations. We further find that the usefulness of probe guidance increases with model scale. Our results show that refusal is not only observable at the output level, but is encoded as a structured and actionable signal in intermediate LLM activations.
TIDE: Asymmetric Neural Circuits for Stabilized Temporal Inhibitory-Excitatory Dynamics
May 19, 2026Recent Continuous Thought Machine architecture decouples internal computation from external inputs via neural dynamics, but relies on multi-layer perceptrons without stability guarantees. We propose to model neural dynamics using asymmetric Excitatory-Inhibitory (E-I) networks, which can be stabilized via principles from network theory and can be expressed as energy-based systems optimized through a game-theoretic loss. Building on this perspective, we introduce Temporal Inhibitory-Excitatory Dynamic Engine (TIDE), a neuro-inspired architecture that computes internal representations through neural dynamics stabilized by incorporating the Wilson-Cowan dynamics and lateral inhibition. TIDE balances biological realism by, for instance, using Hierarchical Receptive Fields and enforcing Dale's principle to ensure a realistic $80:20$ E-I balance ratio with an end-to-end trainable architecture. The aim of this paper is to introduce a new architecture that brings neuro-inspired learning to the forefront. We present proofs of convergence, stability, and complexity bounds, along with empirical ablation studies. Overall, TIDE surpasses CTM with under $50\%$ of the training time and improves $\texttt{top-1}$ accuracy by an average of $+1.65\%$ on ImageNet under various perturbations.
Contextual Bandits for Resource-Constrained Devices using Probabilistic Learning
May 13, 2026Contextual bandits (CB) are online sequential decision-making problems under partial feedback that underpin many adaptive services. There is a growing demand to deploy CB agents directly on-device, under strict constraints on memory, compute, and energy. However, standard linear CB algorithms are often impractical for resource-constrained devices with their unfavorable scaling in computational and memory costs. Recently, HD-CB, a CB approach based on hyperdimensional computing principles, has been proposed to model and solve CB problems by moving into high-dimensional spaces. HD-CB offers faster convergence, favorable scalability, and improves memory efficiency compared to linear CB algorithms. However, its learning rule is accumulation-based: the values of action vectors grow over time, requiring high precision. While periodic binarization can prevent overflow in low-precision components, it may discard important information about magnitudes and degrade decision quality. This paper introduces probabilistic HD-CB, a low-precision variant that replaces deterministic accumulation with a probabilistic update rule. At each step, only a random subset of vector components is updated, with a time-decaying update probability, and component values are constrained to a predefined range [-k,+k]. This approach enables low-precision components, prevents overflow without periodic binarization, and reduces the expected update cost in proportion to the fraction of updated components. Off-policy evaluation on standardized synthetic CB benchmarks using the Open Bandit Pipeline shows that probabilistic HD-CB consistently outperforms binarized HD-CB at equal precision, while approaching the performance of HD-CB with as few as 3 bits per component.
Towards a Comprehensive Theory of Reservoir Computing
Nov 18, 2025In reservoir computing, an input sequence is processed by a recurrent neural network, the reservoir, which transforms it into a spatial pattern that a shallow readout network can then exploit for tasks such as memorization and time-series prediction or classification. Echo state networks (ESN) are a model class in which the reservoir is a traditional artificial neural network. This class contains many model types, each with sets of hyperparameters. Selecting models and parameter settings for particular applications requires a theory for predicting and comparing performances. Here, we demonstrate that recent developments of perceptron theory can be used to predict the memory capacity and accuracy of a wide variety of ESN models, including reservoirs with linear neurons, sigmoid nonlinear neurons, different types of recurrent matrices, and different types of readout networks. Across thirty variants of ESNs, we show that empirical results consistently confirm the theory's predictions. As a practical demonstration, the theory is used to optimize memory capacity of an ESN in the entire joint parameter space. Further, guided by the theory, we propose a novel ESN model with a readout network that does not require training, and which outperforms earlier ESN models without training. Finally, we characterize the geometry of the readout networks in ESNs, which reveals that many ESN models exhibit a similar regular simplex geometry as has been observed in the output weights of deep neural networks.
Efficient Hyperdimensional Computing with Modular Composite Representations
Nov 12, 2025The modular composite representation (MCR) is a computing model that represents information with high-dimensional integer vectors using modular arithmetic. Originally proposed as a generalization of the binary spatter code model, it aims to provide higher representational power while remaining a lighter alternative to models requiring high-precision components. Despite this potential, MCR has received limited attention. Systematic analyses of its trade-offs and comparisons with other models are lacking, sustaining the perception that its added complexity outweighs the improved expressivity. In this work, we revisit MCR by presenting its first extensive evaluation, demonstrating that it achieves a unique balance of capacity, accuracy, and hardware efficiency. Experiments measuring capacity demonstrate that MCR outperforms binary and integer vectors while approaching complex-valued representations at a fraction of their memory footprint. Evaluation on 123 datasets confirms consistent accuracy gains and shows that MCR can match the performance of binary spatter codes using up to 4x less memory. We investigate the hardware realization of MCR by showing that it maps naturally to digital logic and by designing the first dedicated accelerator. Evaluations on basic operations and 7 selected datasets demonstrate a speedup of up to 3 orders of magnitude and significant energy reductions compared to software implementation. When matched for accuracy against binary spatter codes, MCR achieves on average 3.08x faster execution and 2.68x lower energy consumption. These findings demonstrate that, although MCR requires more sophisticated operations than binary spatter codes, its modular arithmetic and higher per-component precision enable lower dimensionality. When realized with dedicated hardware, this results in a faster, more energy-efficient, and high-precision alternative to existing models.
Binding in hippocampal-entorhinal circuits enables compositionality in cognitive maps
Jun 27, 2024We propose a normative model for spatial representation in the hippocampal formation that combines optimality principles, such as maximizing coding range and spatial information per neuron, with an algebraic framework for computing in distributed representation. Spatial position is encoded in a residue number system, with individual residues represented by high-dimensional, complex-valued vectors. These are composed into a single vector representing position by a similarity-preserving, conjunctive vector-binding operation. Self-consistency between the representations of the overall position and of the individual residues is enforced by a modular attractor network whose modules correspond to the grid cell modules in entorhinal cortex. The vector binding operation can also associate different contexts to spatial representations, yielding a model for entorhinal cortex and hippocampus. We show that the model achieves normative desiderata including superlinear scaling of patterns with dimension, robust error correction, and hexagonal, carry-free encoding of spatial position. These properties in turn enable robust path integration and association with sensory inputs. More generally, the model formalizes how compositional computations could occur in the hippocampal formation and leads to testable experimental predictions.
Compositional Factorization of Visual Scenes with Convolutional Sparse Coding and Resonator Networks
Apr 29, 2024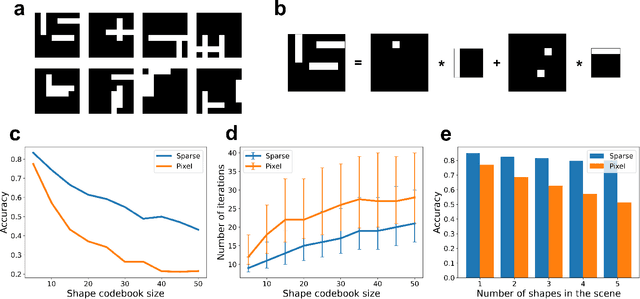
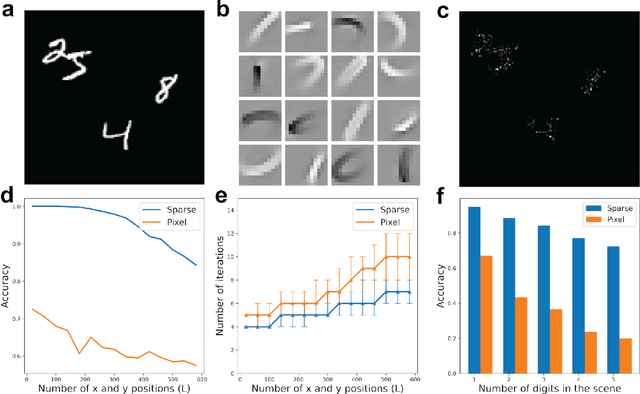
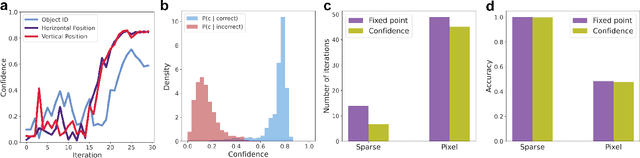
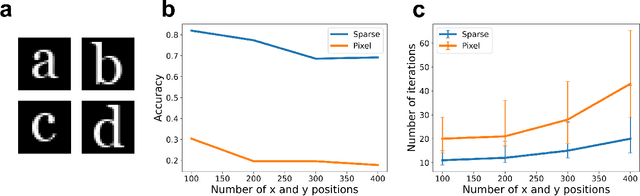
We propose a system for visual scene analysis and recognition based on encoding the sparse, latent feature-representation of an image into a high-dimensional vector that is subsequently factorized to parse scene content. The sparse feature representation is learned from image statistics via convolutional sparse coding, while scene parsing is performed by a resonator network. The integration of sparse coding with the resonator network increases the capacity of distributed representations and reduces collisions in the combinatorial search space during factorization. We find that for this problem the resonator network is capable of fast and accurate vector factorization, and we develop a confidence-based metric that assists in tracking the convergence of the resonator network.
Computing with Residue Numbers in High-Dimensional Representation
Nov 08, 2023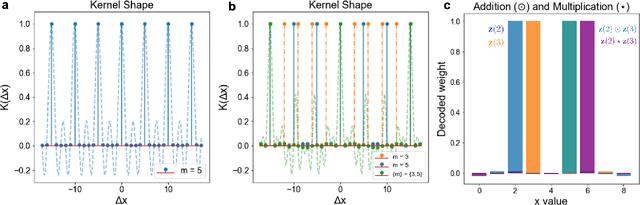
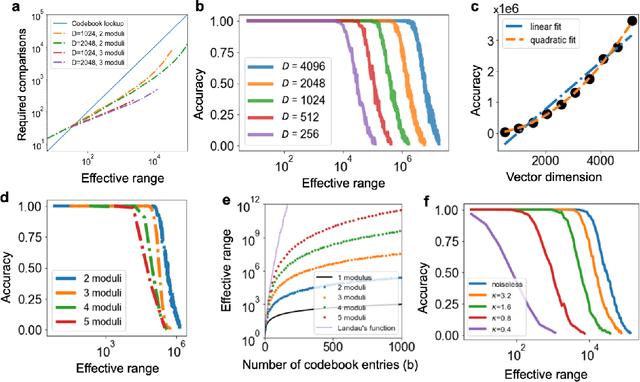
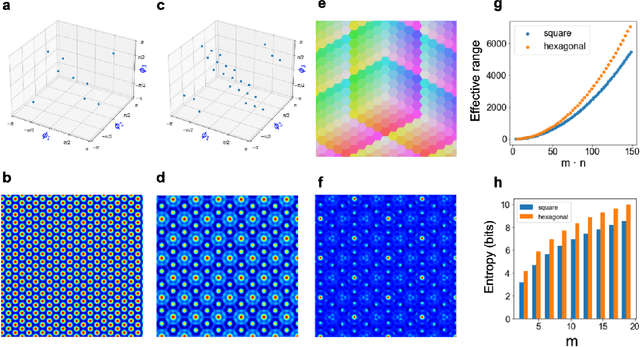
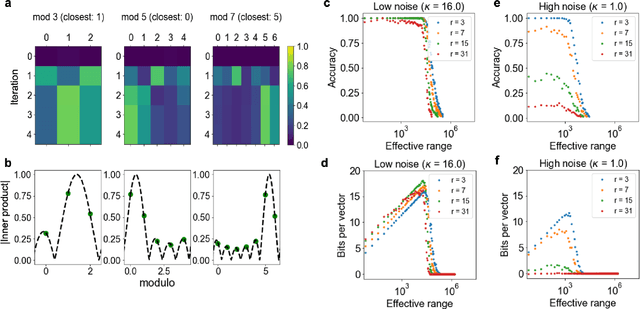
We introduce Residue Hyperdimensional Computing, a computing framework that unifies residue number systems with an algebra defined over random, high-dimensional vectors. We show how residue numbers can be represented as high-dimensional vectors in a manner that allows algebraic operations to be performed with component-wise, parallelizable operations on the vector elements. The resulting framework, when combined with an efficient method for factorizing high-dimensional vectors, can represent and operate on numerical values over a large dynamic range using vastly fewer resources than previous methods, and it exhibits impressive robustness to noise. We demonstrate the potential for this framework to solve computationally difficult problems in visual perception and combinatorial optimization, showing improvement over baseline methods. More broadly, the framework provides a possible account for the computational operations of grid cells in the brain, and it suggests new machine learning architectures for representing and manipulating numerical data.
Efficient Decoding of Compositional Structure in Holistic Representations
May 26, 2023We investigate the task of retrieving information from compositional distributed representations formed by Hyperdimensional Computing/Vector Symbolic Architectures and present novel techniques which achieve new information rate bounds. First, we provide an overview of the decoding techniques that can be used to approach the retrieval task. The techniques are categorized into four groups. We then evaluate the considered techniques in several settings that involve, e.g., inclusion of external noise and storage elements with reduced precision. In particular, we find that the decoding techniques from the sparse coding and compressed sensing literature (rarely used for Hyperdimensional Computing/Vector Symbolic Architectures) are also well-suited for decoding information from the compositional distributed representations. Combining these decoding techniques with interference cancellation ideas from communications improves previously reported bounds (Hersche et al., 2021) of the information rate of the distributed representations from 1.20 to 1.40 bits per dimension for smaller codebooks and from 0.60 to 1.26 bits per dimension for larger codebooks.
* 28 pages, 5 figures
Efficient Optimization with Higher-Order Ising Machines
Dec 07, 2022A prominent approach to solving combinatorial optimization problems on parallel hardware is Ising machines, i.e., hardware implementations of networks of interacting binary spin variables. Most Ising machines leverage second-order interactions although important classes of optimization problems, such as satisfiability problems, map more seamlessly to Ising networks with higher-order interactions. Here, we demonstrate that higher-order Ising machines can solve satisfiability problems more resource-efficiently in terms of the number of spin variables and their connections when compared to traditional second-order Ising machines. Further, our results show on a benchmark dataset of Boolean \textit{k}-satisfiability problems that higher-order Ising machines implemented with coupled oscillators rapidly find solutions that are better than second-order Ising machines, thus, improving the current state-of-the-art for Ising machines.