 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing with Hypervectors for Efficient Speaker Identification
Aug 28, 2022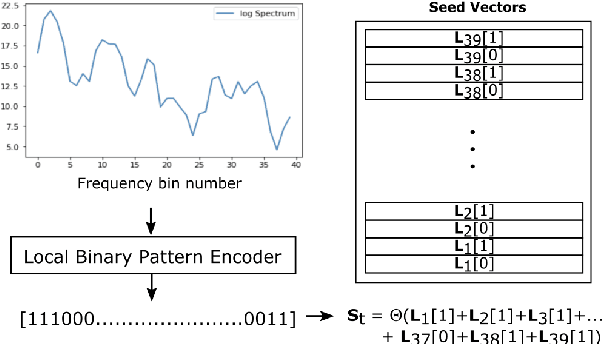

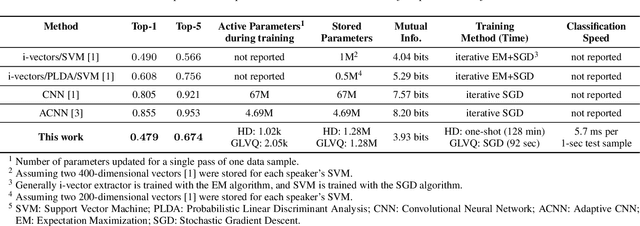
We introduce a method to identify speakers by computing with high-dimensional random vectors. Its strengths are simplicity and speed. With only 1.02k active parameters and a 128-minute pass through the training data we achieve Top-1 and Top-5 scores of 31% and 52% on the VoxCeleb1 dataset of 1,251 speakers. This is in contrast to CNN models requiring several million parameters and orders of magnitude higher computational complexity for only a 2$\times$ gain in discriminative power as measured in mutual information. An additional 92 seconds of training with Generalized Learning Vector Quantization (GLVQ) raises the scores to 48% and 67%. A trained classifier classifies 1 second of speech in 5.7 ms. All processing was done on standard CPU-based machines.
Generalized Key-Value Memory to Flexibly Adjust Redundancy in Memory-Augmented Networks
Mar 11, 2022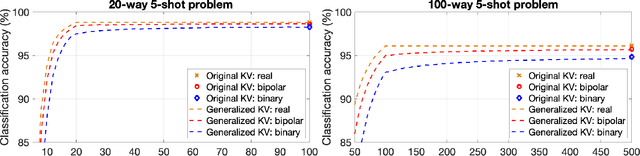
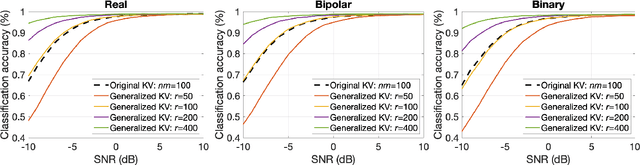
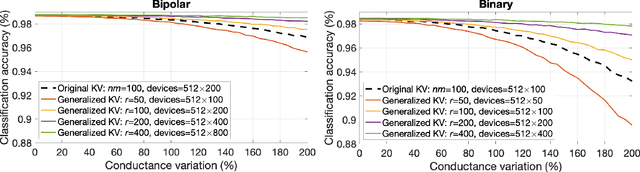
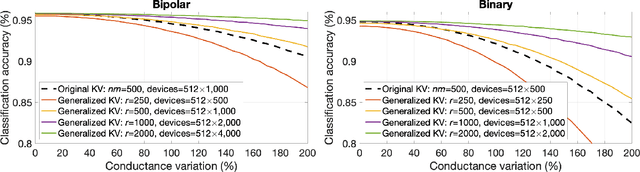
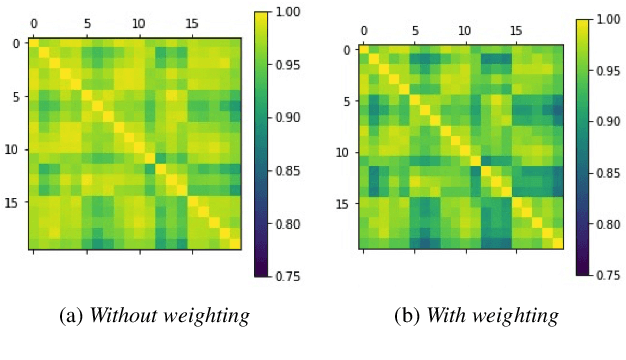
Memory-augmented neural networks enhance a neural network with an external key-value memory whose complexity is typically dominated by the number of support vectors in the key memory. We propose a generalized key-value memory that decouples its dimension from the number of support vectors by introducing a free parameter that can arbitrarily add or remove redundancy to the key memory representation. In effect, it provides an additional degree of freedom to flexibly control the trade-off between robustness and the resources required to store and compute the generalized key-value memory. This is particularly useful for realizing the key memory on in-memory computing hardware where it exploits nonideal, but extremely efficient non-volatile memory devices for dense storage and computation. Experimental results show that adapting this parameter on demand effectively mitigates up to 44% nonidealities, at equal accuracy and number of devices, without any need for neural network retraining.
Generalized Learning Vector Quantization for Classification in Randomized Neural Networks and Hyperdimensional Computing
Jun 17, 2021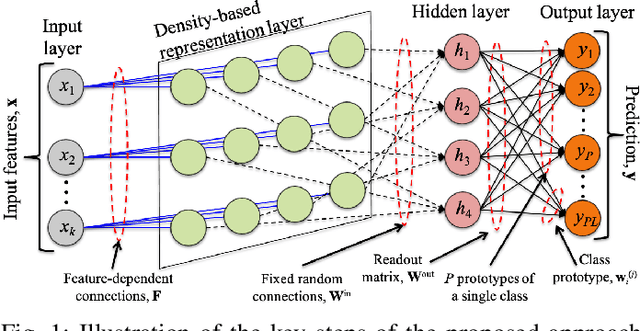
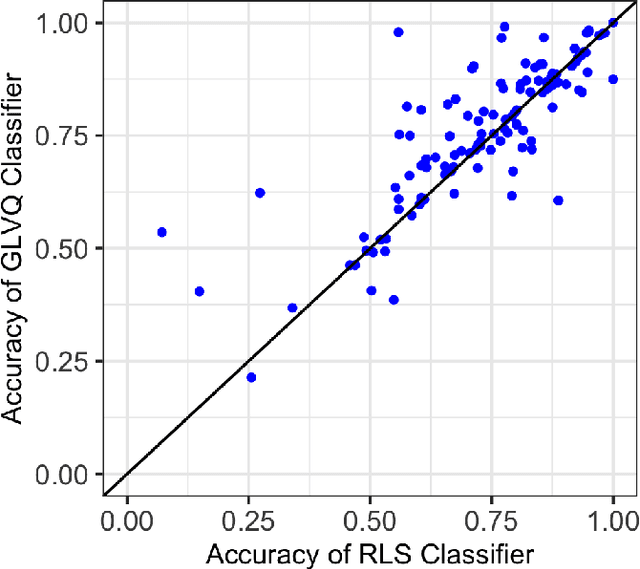
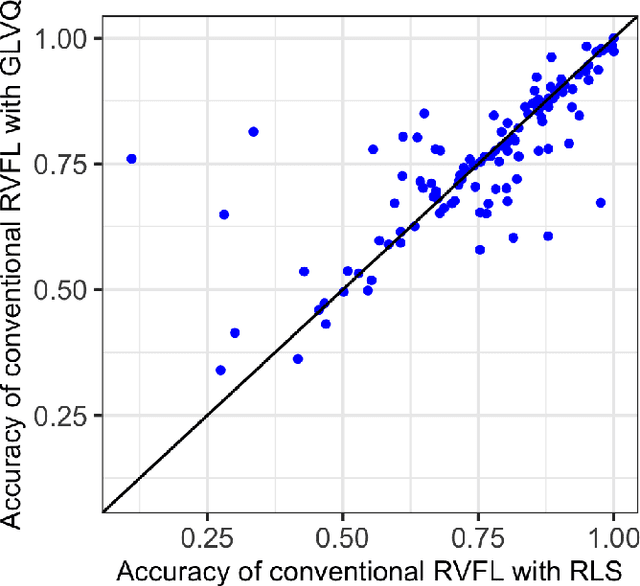
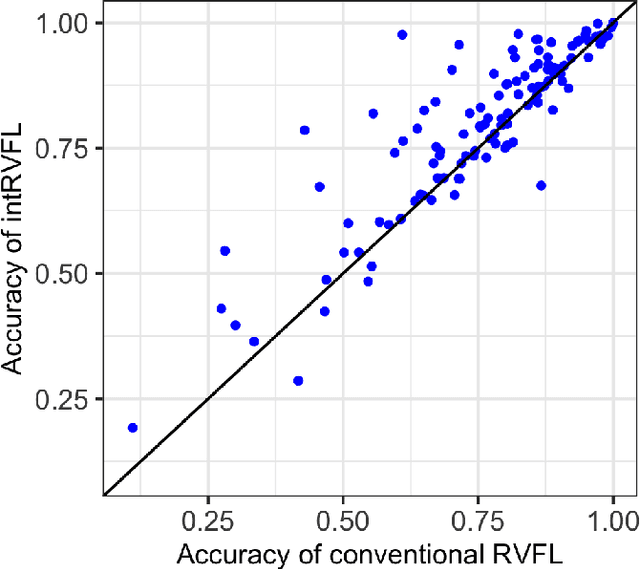
Machine learning algorithms deployed on edge devices must meet certain resource constraints and efficiency requirements. Random Vector Functional Link (RVFL) networks are favored for such applications due to their simple design and training efficiency. We propose a modified RVFL network that avoids computationally expensive matrix operations during training, thus expanding the network's range of potential applications. Our modification replaces the least-squares classifier with the Generalized Learning Vector Quantization (GLVQ) classifier, which only employs simple vector and distance calculations. The GLVQ classifier can also be considered an improvement upon certain classification algorithms popularly used in the area of Hyperdimensional Computing. The proposed approach achieved state-of-the-art accuracy on a collection of datasets from the UCI Machine Learning Repository - higher than previously proposed RVFL networks. We further demonstrate that our approach still achieves high accuracy while severely limited in training iterations (using on average only 21% of the least-squares classifier computational costs).
Vector Symbolic Architectures as a Computing Framework for Nanoscale Hardware
Jun 09, 2021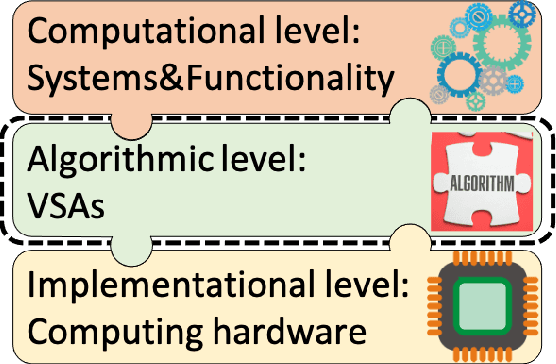
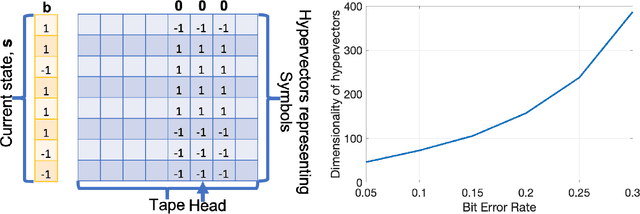
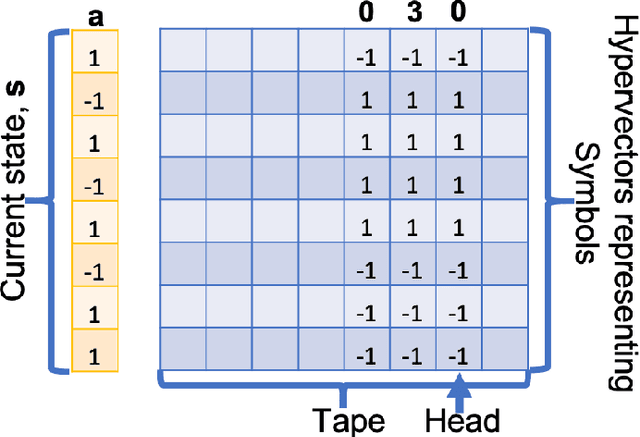
This article reviews recent progress in the development of the computing framework Vector Symbolic Architectures (also known as Hyperdimensional Computing). This framework is well suited for implementation in stochastic, nanoscale hardware and it naturally expresses the types of cognitive operations required for Artificial Intelligence (AI). We demonstrate in this article that the ring-like algebraic structure of Vector Symbolic Architectures offers simple but powerful operations on high-dimensional vectors that can support all data structures and manipulations relevant in modern computing. In addition, we illustrate the distinguishing feature of Vector Symbolic Architectures, "computing in superposition," which sets it apart from conventional computing. This latter property opens the door to efficient solutions to the difficult combinatorial search problems inherent in AI applications. Vector Symbolic Architectures are Turing complete, as we show, and we see them acting as a framework for computing with distributed representations in myriad AI settings. This paper serves as a reference for computer architects by illustrating techniques and philosophy of VSAs for distributed computing and relevance to emerging computing hardware, such as neuromorphic computing.
Efficient emotion recognition using hyperdimensional computing with combinatorial channel encoding and cellular automata
Apr 06, 2021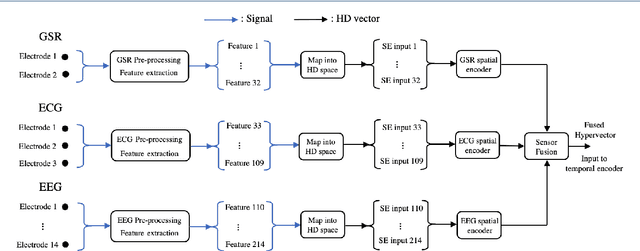
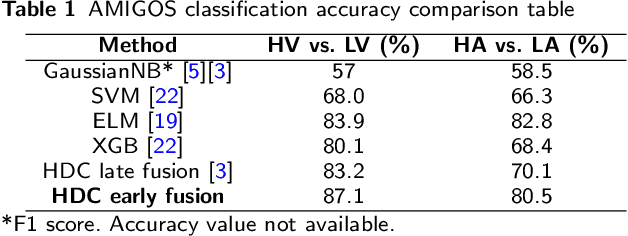
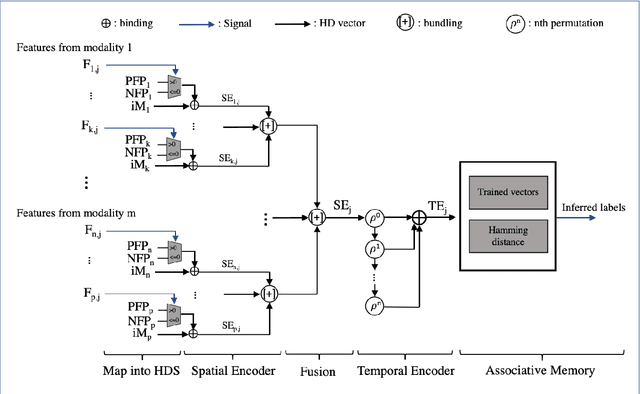
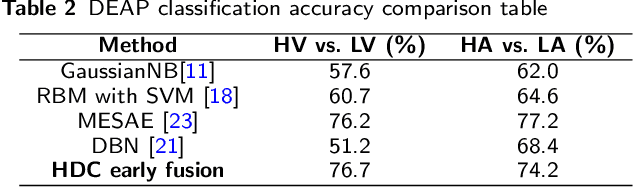
In this paper, a hardware-optimized approach to emotion recognition based on the efficient brain-inspired hyperdimensional computing (HDC) paradigm is proposed. Emotion recognition provides valuable information for human-computer interactions, however the large number of input channels (>200) and modalities (>3) involved in emotion recognition are significantly expensive from a memory perspective. To address this, methods for memory reduction and optimization are proposed, including a novel approach that takes advantage of the combinatorial nature of the encoding process, and an elementary cellular automaton. HDC with early sensor fusion is implemented alongside the proposed techniques achieving two-class multi-modal classification accuracies of >76% for valence and >73% for arousal on the multi-modal AMIGOS and DEAP datasets, almost always better than state of the art. The required vector storage is seamlessly reduced by 98% and the frequency of vector requests by at least 1/5. The results demonstrate the potential of efficient hyperdimensional computing for low-power, multi-channeled emotion recognition tasks.
Adaptive EMG-based hand gesture recognition using hyperdimensional computing
Jan 02, 2019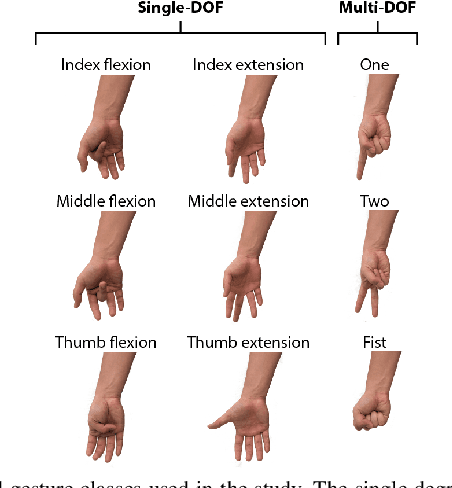


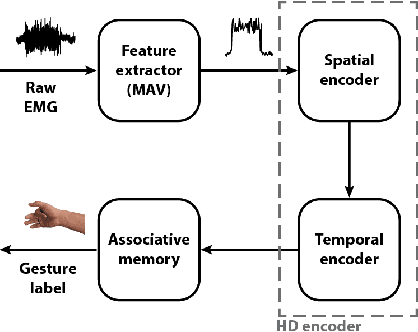
Accurate recognition of hand gestures is crucial to the functionality of smart prosthetics and other modern human-computer interfaces. Many machine learning-based classifiers use electromyography (EMG) signals as input features, but they often misclassify gestures performed in different situational contexts (changing arm position, reapplication of electrodes, etc.) or with different effort levels due to changing signal properties. Here, we describe a learning and classification algorithm based on hyperdimensional (HD) computing that, unlike traditional machine learning algorithms, enables computationally efficient updates to incrementally incorporate new data and adapt to changing contexts. EMG signal encoding for both training and classification is performed using the same set of simple operations on 10,000-element random hypervectors enabling updates on the fly. Through human experiments using a custom EMG acquisition system, we demonstrate 88.87% classification accuracy on 13 individual finger flexion and extension gestures. Using simple model updates, we preserve this accuracy with less than 5.48% degradation when expanding to 21 commonly used gestures or when subject to changing situational contexts. We also show that the same methods for updating models can be used to account for variations resulting from the effort level with which a gesture is performed.
Hyperdimensional Computing Nanosystem
Nov 23, 2018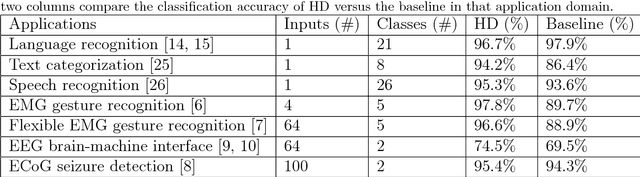
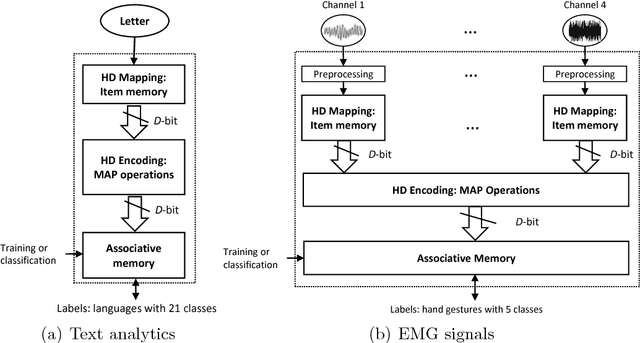
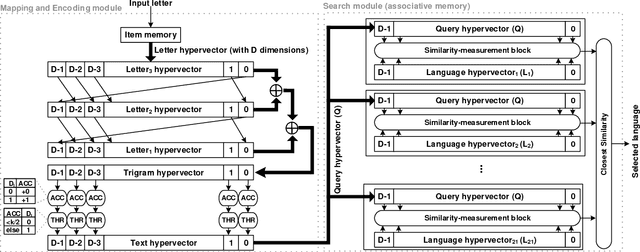
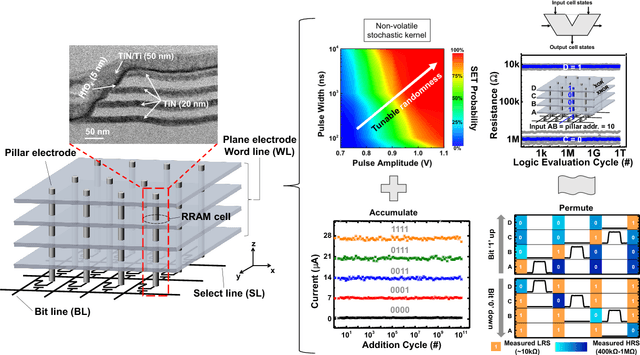
One viable solution for continuous reduction in energy-per-operation is to rethink functionality to cope with uncertainty by adopting computational approaches that are inherently robust to uncertainty. It requires a novel look at data representations, associated operations, and circuits, and at materials and substrates that enable them. 3D integrated nanotechnologies combined with novel brain-inspired computational paradigms that support fast learning and fault tolerance could lead the way. Recognizing the very size of the brain's circuits, hyperdimensional (HD) computing can model neural activity patterns with points in a HD space, that is, with hypervectors as large randomly generated patterns. At its very core, HD computing is about manipulating and comparing these patterns inside memory. Emerging nanotechnologies such as carbon nanotube field effect transistors (CNFETs) and resistive RAM (RRAM), and their monolithic 3D integration offer opportunities for hardware implementations of HD computing through tight integration of logic and memory, energy-efficient computation, and unique device characteristics. We experimentally demonstrate and characterize an end-to-end HD computing nanosystem built using monolithic 3D integration of CNFETs and RRAM. With our nanosystem, we experimentally demonstrate classification of 21 languages with measured accuracy of up to 98% on >20,000 sentences (6.4 million characters), training using one text sample (~100,000 characters) per language, and resilient operation (98% accuracy) despite 78% hardware errors in HD representation (outputs stuck at 0 or 1). By exploiting the unique properties of the underlying nanotechnologies, we show that HD computing, when implemented with monolithic 3D integration, can be up to 420X more energy-efficient while using 25X less area compared to traditional silicon CMOS implementations.
An EMG Gesture Recognition System with Flexible High-Density Sensors and Brain-Inspired High-Dimensional Classifier
Apr 05, 2018

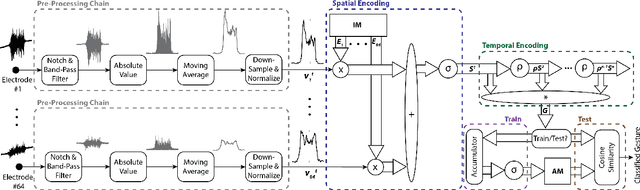
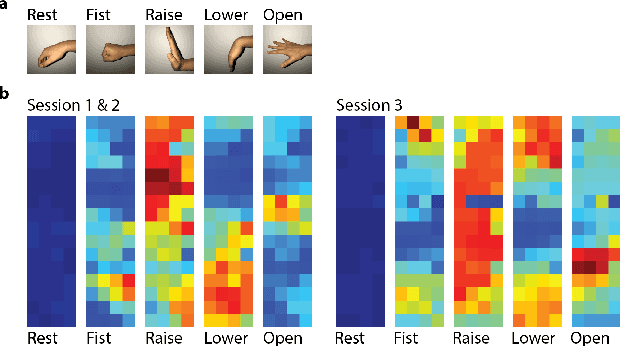
EMG-based gesture recognition shows promise for human-machine interaction. Systems are often afflicted by signal and electrode variability which degrades performance over time. We present an end-to-end system combating this variability using a large-area, high-density sensor array and a robust classification algorithm. EMG electrodes are fabricated on a flexible substrate and interfaced to a custom wireless device for 64-channel signal acquisition and streaming. We use brain-inspired high-dimensional (HD) computing for processing EMG features in one-shot learning. The HD algorithm is tolerant to noise and electrode misplacement and can quickly learn from few gestures without gradient descent or back-propagation. We achieve an average classification accuracy of 96.64% for five gestures, with only 7% degradation when training and testing across different days. Our system maintains this accuracy when trained with only three trials of gestures; it also demonstrates comparable accuracy with the state-of-the-art when trained with one trial.