 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized multi-object classification and tracking with sparse feature resonator networks
Mar 23, 2026In visual scene understanding tasks, it is essential to capture both invariant and equivariant structure. While neural networks are frequently trained to achieve invariance to transformations such as translation, this often comes at the cost of losing access to equivariant information - e.g., the precise location of an object. Moreover, invariance is not naturally guaranteed through supervised learning alone, and many architectures generalize poorly to input transformations not encountered during training. Here, we take an approach based on analysis-by-synthesis and factoring using resonator networks. A generative model describes the construction of simple scenes containing MNIST digits and their transformations, like color and position. The resonator network inverts the generative model, and provides both invariant and equivariant information about particular objects. Sparse features learned from training data act as a basis set to provide flexibility in representing variable shapes of objects, allowing the resonator network to handle previously unseen digit shapes from the test set. The modular structure provides a shape module which contains information about the object shape with translation factored out, allowing a simple classifier to operate on centered digits. The classification layer is trained solely on centered data, requiring much less training data, and the network as a whole can identify objects with arbitrary translations without data augmentation. The natural attention-like mechanism of the resonator network also allows for analysis of scenes with multiple objects, where the network dynamics selects and centers only one object at a time. Further, the specific position information of a particular object can be extracted from the translation module, and we show that the resonator can be designed to track multiple moving objects with precision of a few pixels.
Towards a Comprehensive Theory of Reservoir Computing
Nov 18, 2025In reservoir computing, an input sequence is processed by a recurrent neural network, the reservoir, which transforms it into a spatial pattern that a shallow readout network can then exploit for tasks such as memorization and time-series prediction or classification. Echo state networks (ESN) are a model class in which the reservoir is a traditional artificial neural network. This class contains many model types, each with sets of hyperparameters. Selecting models and parameter settings for particular applications requires a theory for predicting and comparing performances. Here, we demonstrate that recent developments of perceptron theory can be used to predict the memory capacity and accuracy of a wide variety of ESN models, including reservoirs with linear neurons, sigmoid nonlinear neurons, different types of recurrent matrices, and different types of readout networks. Across thirty variants of ESNs, we show that empirical results consistently confirm the theory's predictions. As a practical demonstration, the theory is used to optimize memory capacity of an ESN in the entire joint parameter space. Further, guided by the theory, we propose a novel ESN model with a readout network that does not require training, and which outperforms earlier ESN models without training. Finally, we characterize the geometry of the readout networks in ESNs, which reveals that many ESN models exhibit a similar regular simplex geometry as has been observed in the output weights of deep neural networks.
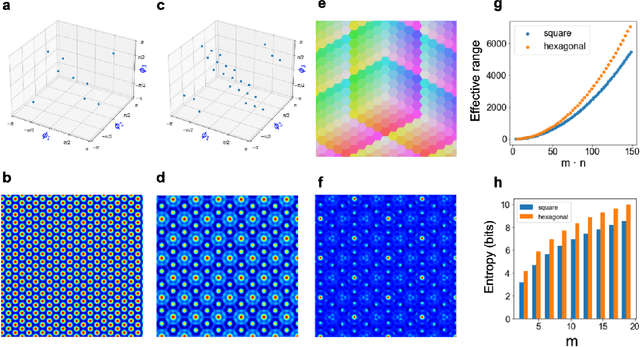
Binding in hippocampal-entorhinal circuits enables compositionality in cognitive maps
Jun 27, 2024We propose a normative model for spatial representation in the hippocampal formation that combines optimality principles, such as maximizing coding range and spatial information per neuron, with an algebraic framework for computing in distributed representation. Spatial position is encoded in a residue number system, with individual residues represented by high-dimensional, complex-valued vectors. These are composed into a single vector representing position by a similarity-preserving, conjunctive vector-binding operation. Self-consistency between the representations of the overall position and of the individual residues is enforced by a modular attractor network whose modules correspond to the grid cell modules in entorhinal cortex. The vector binding operation can also associate different contexts to spatial representations, yielding a model for entorhinal cortex and hippocampus. We show that the model achieves normative desiderata including superlinear scaling of patterns with dimension, robust error correction, and hexagonal, carry-free encoding of spatial position. These properties in turn enable robust path integration and association with sensory inputs. More generally, the model formalizes how compositional computations could occur in the hippocampal formation and leads to testable experimental predictions.
Computing with Residue Numbers in High-Dimensional Representation
Nov 08, 2023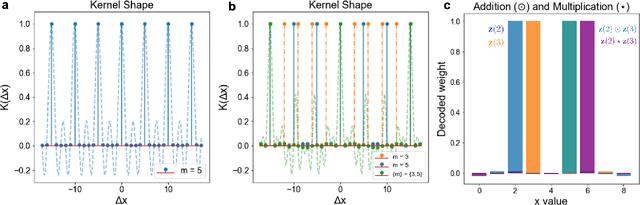
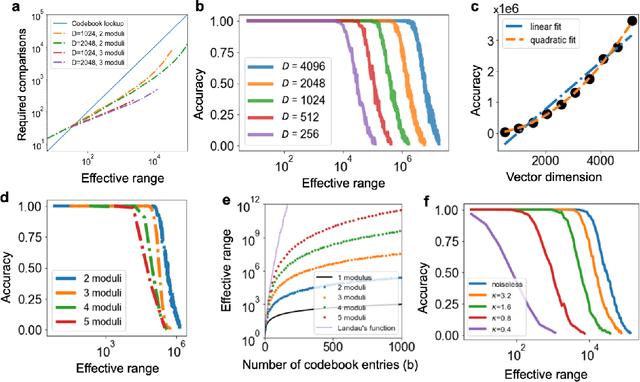
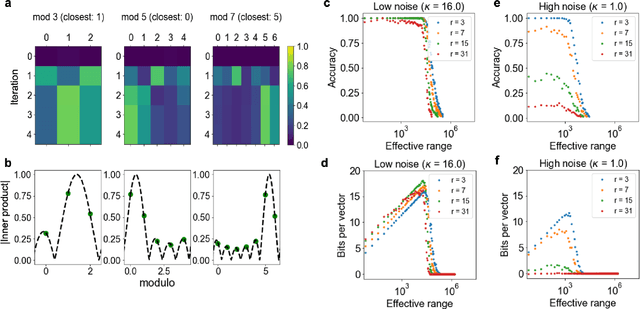
We introduce Residue Hyperdimensional Computing, a computing framework that unifies residue number systems with an algebra defined over random, high-dimensional vectors. We show how residue numbers can be represented as high-dimensional vectors in a manner that allows algebraic operations to be performed with component-wise, parallelizable operations on the vector elements. The resulting framework, when combined with an efficient method for factorizing high-dimensional vectors, can represent and operate on numerical values over a large dynamic range using vastly fewer resources than previous methods, and it exhibits impressive robustness to noise. We demonstrate the potential for this framework to solve computationally difficult problems in visual perception and combinatorial optimization, showing improvement over baseline methods. More broadly, the framework provides a possible account for the computational operations of grid cells in the brain, and it suggests new machine learning architectures for representing and manipulating numerical data.
Efficient Decoding of Compositional Structure in Holistic Representations
May 26, 2023We investigate the task of retrieving information from compositional distributed representations formed by Hyperdimensional Computing/Vector Symbolic Architectures and present novel techniques which achieve new information rate bounds. First, we provide an overview of the decoding techniques that can be used to approach the retrieval task. The techniques are categorized into four groups. We then evaluate the considered techniques in several settings that involve, e.g., inclusion of external noise and storage elements with reduced precision. In particular, we find that the decoding techniques from the sparse coding and compressed sensing literature (rarely used for Hyperdimensional Computing/Vector Symbolic Architectures) are also well-suited for decoding information from the compositional distributed representations. Combining these decoding techniques with interference cancellation ideas from communications improves previously reported bounds (Hersche et al., 2021) of the information rate of the distributed representations from 1.20 to 1.40 bits per dimension for smaller codebooks and from 0.60 to 1.26 bits per dimension for larger codebooks.
* 28 pages, 5 figures
Learning and generalization of compositional representations of visual scenes
Mar 23, 2023



Complex visual scenes that are composed of multiple objects, each with attributes, such as object name, location, pose, color, etc., are challenging to describe in order to train neural networks. Usually,deep learning networks are trained supervised by categorical scene descriptions. The common categorical description of a scene contains the names of individual objects but lacks information about other attributes. Here, we use distributed representations of object attributes and vector operations in a vector symbolic architecture to create a full compositional description of a scene in a high-dimensional vector. To control the scene composition, we use artificial images composed of multiple, translated and colored MNIST digits. In contrast to learning category labels, here we train deep neural networks to output the full compositional vector description of an input image. The output of the deep network can then be interpreted by a VSA resonator network, to extract object identity or other properties of indiviual objects. We evaluate the performance and generalization properties of the system on randomly generated scenes. Specifically, we show that the network is able to learn the task and generalize to unseen seen digit shapes and scene configurations. Further, the generalisation ability of the trained model is limited. For example, with a gap in the training data, like an object not shown in a particular image location during training, the learning does not automatically fill this gap.
Neuromorphic Visual Odometry with Resonator Networks
Sep 05, 2022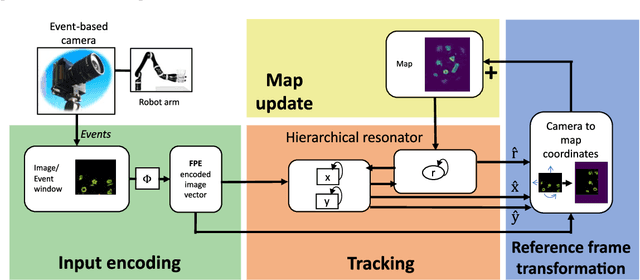
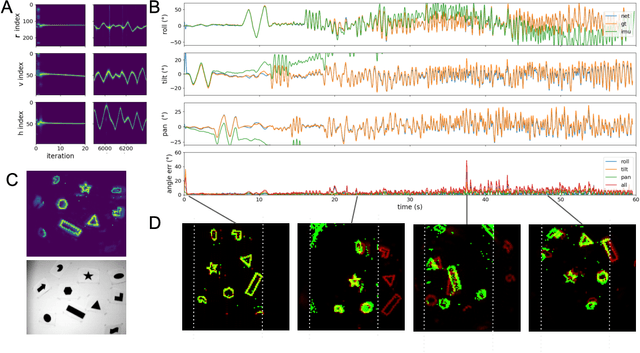
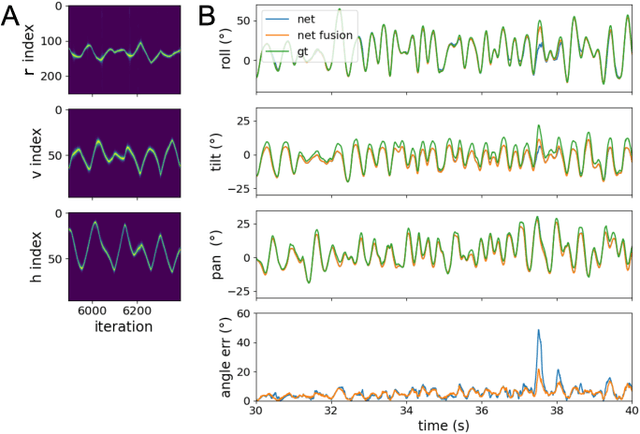
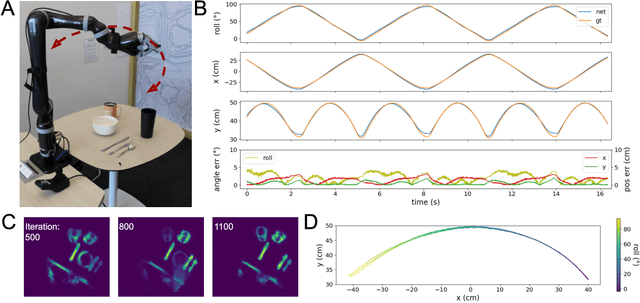
Autonomous agents require self-localization to navigate in unknown environments. They can use Visual Odometry (VO) to estimate self-motion and localize themselves using visual sensors. This motion-estimation strategy is not compromised by drift as inertial sensors or slippage as wheel encoders. However, VO with conventional cameras is computationally demanding, limiting its application in systems with strict low-latency, -memory, and -energy requirements. Using event-based cameras and neuromorphic computing hardware offers a promising low-power solution to the VO problem. However, conventional algorithms for VO are not readily convertible to neuromorphic hardware. In this work, we present a VO algorithm built entirely of neuronal building blocks suitable for neuromorphic implementation. The building blocks are groups of neurons representing vectors in the computational framework of Vector Symbolic Architecture (VSA) which was proposed as an abstraction layer to program neuromorphic hardware. The VO network we propose generates and stores a working memory of the presented visual environment. It updates this working memory while at the same time estimating the changing location and orientation of the camera. We demonstrate how VSA can be leveraged as a computing paradigm for neuromorphic robotics. Moreover, our results represent an important step towards using neuromorphic computing hardware for fast and power-efficient VO and the related task of simultaneous localization and mapping (SLAM). We validate this approach experimentally in a robotic task and with an event-based dataset, demonstrating state-of-the-art performance.
Neuromorphic Visual Scene Understanding with Resonator Networks
Aug 26, 2022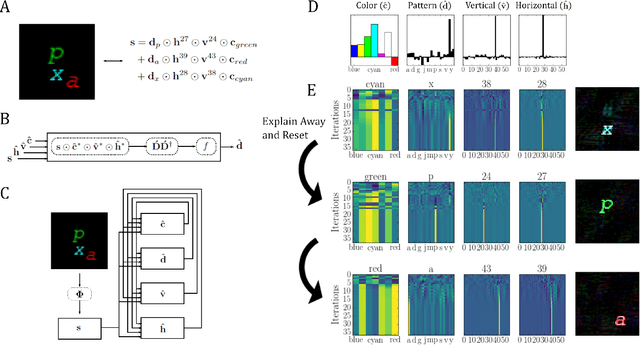
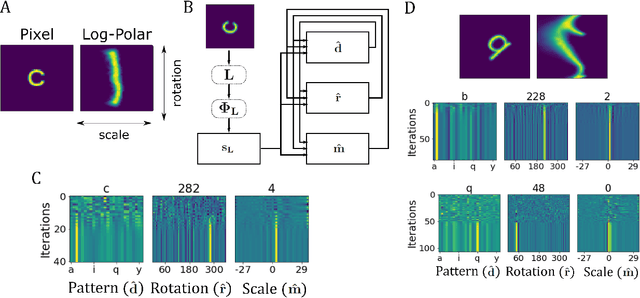
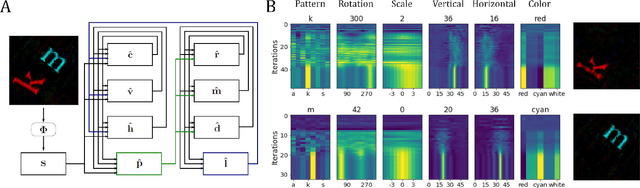
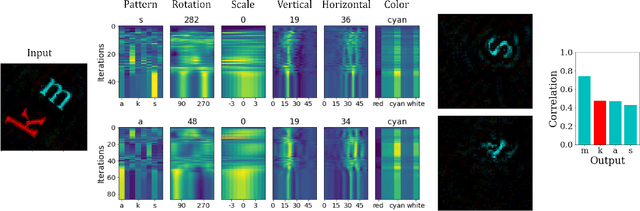
Inferring the position of objects and their rigid transformations is still an open problem in visual scene understanding. Here we propose a neuromorphic solution that utilizes an efficient factorization network which is based on three key concepts: (1) a computational framework based on Vector Symbolic Architectures (VSA) with complex-valued vectors; (2) the design of Hierarchical Resonator Networks (HRN) to deal with the non-commutative nature of translation and rotation in visual scenes, when both are used in combination; (3) the design of a multi-compartment spiking phasor neuron model for implementing complex-valued vector binding on neuromorphic hardware. The VSA framework uses vector binding operations to produce generative image models in which binding acts as the equivariant operation for geometric transformations. A scene can therefore be described as a sum of vector products, which in turn can be efficiently factorized by a resonator network to infer objects and their poses. The HRN enables the definition of a partitioned architecture in which vector binding is equivariant for horizontal and vertical translation within one partition, and for rotation and scaling within the other partition. The spiking neuron model allows to map the resonator network onto efficient and low-power neuromorphic hardware. In this work, we demonstrate our approach using synthetic scenes composed of simple 2D shapes undergoing rigid geometric transformations and color changes. A companion paper demonstrates this approach in real-world application scenarios for machine vision and robotics.
Deep Learning in Spiking Phasor Neural Networks
Apr 01, 2022

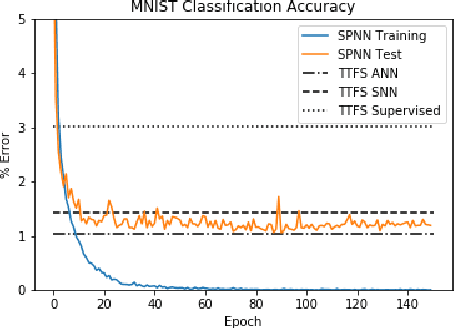
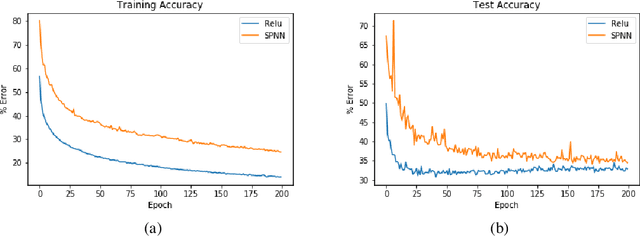
Spiking Neural Networks (SNNs) have attracted the attention of the deep learning community for use in low-latency, low-power neuromorphic hardware, as well as models for understanding neuroscience. In this paper, we introduce Spiking Phasor Neural Networks (SPNNs). SPNNs are based on complex-valued Deep Neural Networks (DNNs), representing phases by spike times. Our model computes robustly employing a spike timing code and gradients can be formed using the complex domain. We train SPNNs on CIFAR-10, and demonstrate that the performance exceeds that of other timing coded SNNs, approaching results with comparable real-valued DNNs.
Integer Factorization with Compositional Distributed Representations
Mar 02, 2022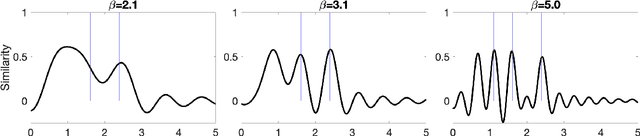
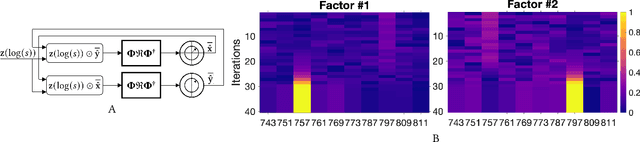
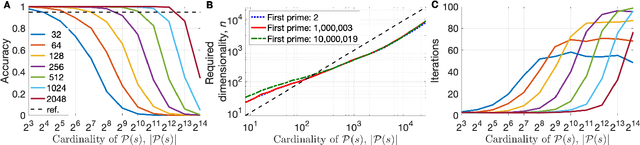
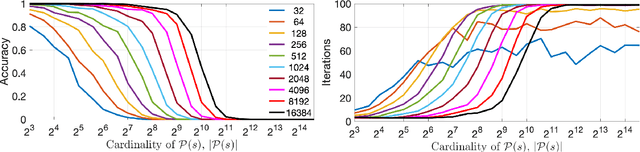
In this paper, we present an approach to integer factorization using distributed representations formed with Vector Symbolic Architectures. The approach formulates integer factorization in a manner such that it can be solved using neural networks and potentially implemented on parallel neuromorphic hardware. We introduce a method for encoding numbers in distributed vector spaces and explain how the resonator network can solve the integer factorization problem. We evaluate the approach on factorization of semiprimes by measuring the factorization accuracy versus the scale of the problem. We also demonstrate how the proposed approach generalizes beyond the factorization of semiprimes; in principle, it can be used for factorization of any composite number. This work demonstrates how a well-known combinatorial search problem may be formulated and solved within the framework of Vector Symbolic Architectures, and it opens the door to solving similarly difficult problems in other domains.