 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Grid Cell-Inspired Structured Vector Algebra for Cognitive Maps
Mar 11, 2025The entorhinal-hippocampal formation is the mammalian brain's navigation system, encoding both physical and abstract spaces via grid cells. This system is well-studied in neuroscience, and its efficiency and versatility make it attractive for applications in robotics and machine learning. While continuous attractor networks (CANs) successfully model entorhinal grid cells for encoding physical space, integrating both continuous spatial and abstract spatial computations into a unified framework remains challenging. Here, we attempt to bridge this gap by proposing a mechanistic model for versatile information processing in the entorhinal-hippocampal formation inspired by CANs and Vector Symbolic Architectures (VSAs), a neuro-symbolic computing framework. The novel grid-cell VSA (GC-VSA) model employs a spatially structured encoding scheme with 3D neuronal modules mimicking the discrete scales and orientations of grid cell modules, reproducing their characteristic hexagonal receptive fields. In experiments, the model demonstrates versatility in spatial and abstract tasks: (1) accurate path integration for tracking locations, (2) spatio-temporal representation for querying object locations and temporal relations, and (3) symbolic reasoning using family trees as a structured test case for hierarchical relationships.
Accurate Mapping of RNNs on Neuromorphic Hardware with Adaptive Spiking Neurons
Jul 18, 2024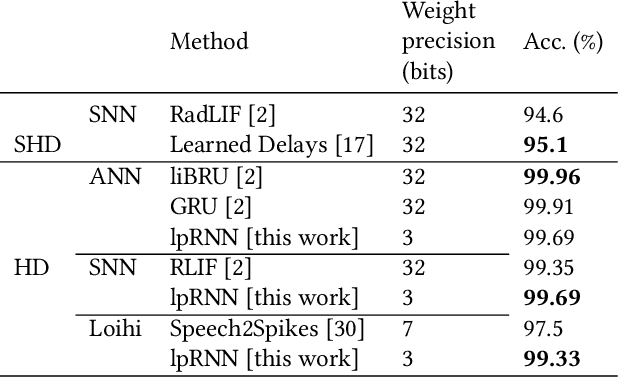
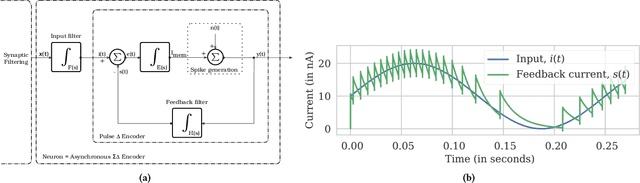
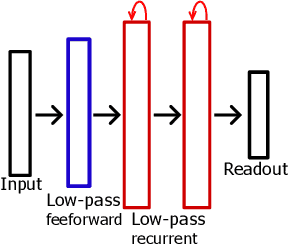
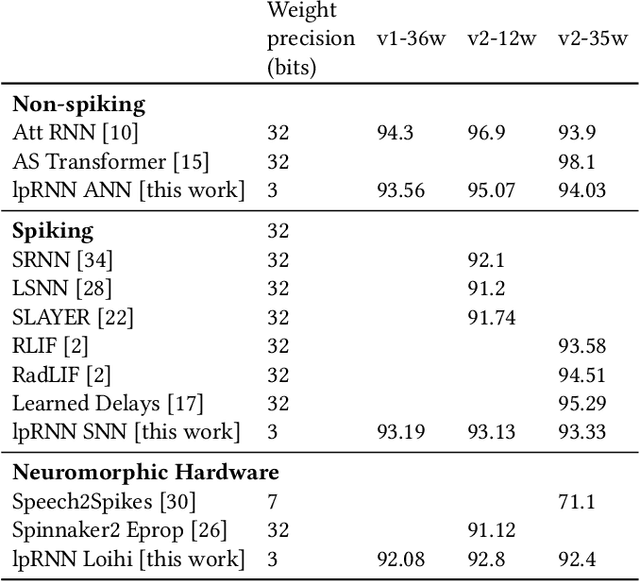
Thanks to their parallel and sparse activity features, recurrent neural networks (RNNs) are well-suited for hardware implementation in low-power neuromorphic hardware. However, mapping rate-based RNNs to hardware-compatible spiking neural networks (SNNs) remains challenging. Here, we present a ${\Sigma}{\Delta}$-low-pass RNN (lpRNN): an RNN architecture employing an adaptive spiking neuron model that encodes signals using ${\Sigma}{\Delta}$-modulation and enables precise mapping. The ${\Sigma}{\Delta}$-neuron communicates analog values using spike timing, and the dynamics of the lpRNN are set to match typical timescales for processing natural signals, such as speech. Our approach integrates rate and temporal coding, offering a robust solution for the efficient and accurate conversion of RNNs to SNNs. We demonstrate the implementation of the lpRNN on Intel's neuromorphic research chip Loihi, achieving state-of-the-art classification results on audio benchmarks using 3-bit weights. These results call for a deeper investigation of recurrency and adaptation in event-based systems, which may lead to insights for edge computing applications where power-efficient real-time inference is required.
Distributed Representations Enable Robust Multi-Timescale Computation in Neuromorphic Hardware
May 02, 2024



Programming recurrent spiking neural networks (RSNNs) to robustly perform multi-timescale computation remains a difficult challenge. To address this, we show how the distributed approach offered by vector symbolic architectures (VSAs), which uses high-dimensional random vectors as the smallest units of representation, can be leveraged to embed robust multi-timescale dynamics into attractor-based RSNNs. We embed finite state machines into the RSNN dynamics by superimposing a symmetric autoassociative weight matrix and asymmetric transition terms. The transition terms are formed by the VSA binding of an input and heteroassociative outer-products between states. Our approach is validated through simulations with highly non-ideal weights; an experimental closed-loop memristive hardware setup; and on Loihi 2, where it scales seamlessly to large state machines. This work demonstrates the effectiveness of VSA representations for embedding robust computation with recurrent dynamics into neuromorphic hardware, without requiring parameter fine-tuning or significant platform-specific optimisation. This advances VSAs as a high-level representation-invariant abstract language for cognitive algorithms in neuromorphic hardware.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
Neuromorphic Visual Odometry with Resonator Networks
Sep 05, 2022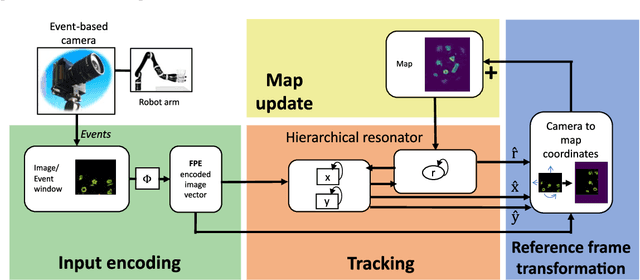
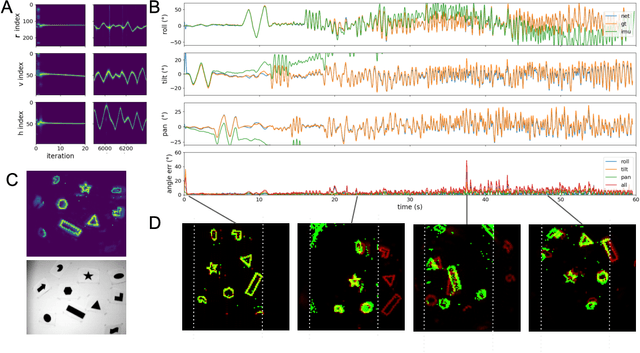
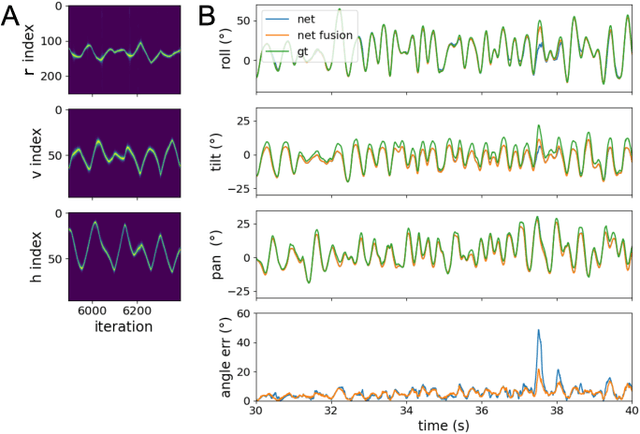
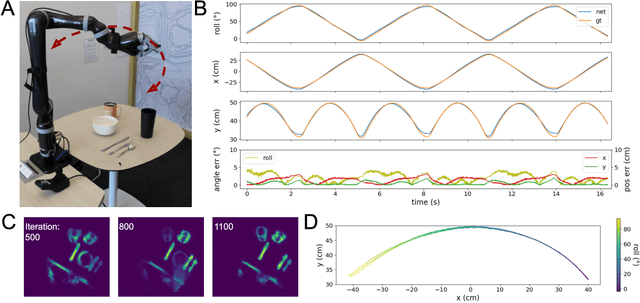
Autonomous agents require self-localization to navigate in unknown environments. They can use Visual Odometry (VO) to estimate self-motion and localize themselves using visual sensors. This motion-estimation strategy is not compromised by drift as inertial sensors or slippage as wheel encoders. However, VO with conventional cameras is computationally demanding, limiting its application in systems with strict low-latency, -memory, and -energy requirements. Using event-based cameras and neuromorphic computing hardware offers a promising low-power solution to the VO problem. However, conventional algorithms for VO are not readily convertible to neuromorphic hardware. In this work, we present a VO algorithm built entirely of neuronal building blocks suitable for neuromorphic implementation. The building blocks are groups of neurons representing vectors in the computational framework of Vector Symbolic Architecture (VSA) which was proposed as an abstraction layer to program neuromorphic hardware. The VO network we propose generates and stores a working memory of the presented visual environment. It updates this working memory while at the same time estimating the changing location and orientation of the camera. We demonstrate how VSA can be leveraged as a computing paradigm for neuromorphic robotics. Moreover, our results represent an important step towards using neuromorphic computing hardware for fast and power-efficient VO and the related task of simultaneous localization and mapping (SLAM). We validate this approach experimentally in a robotic task and with an event-based dataset, demonstrating state-of-the-art performance.
Neuromorphic Visual Scene Understanding with Resonator Networks
Aug 26, 2022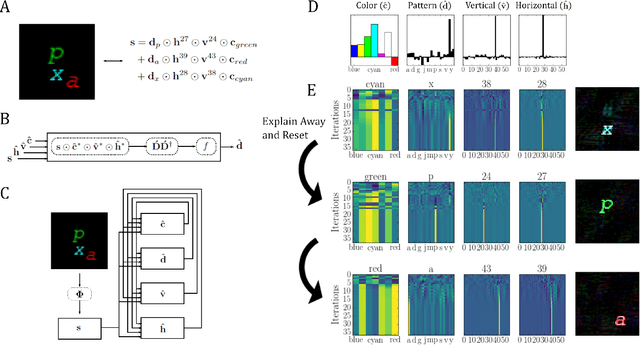
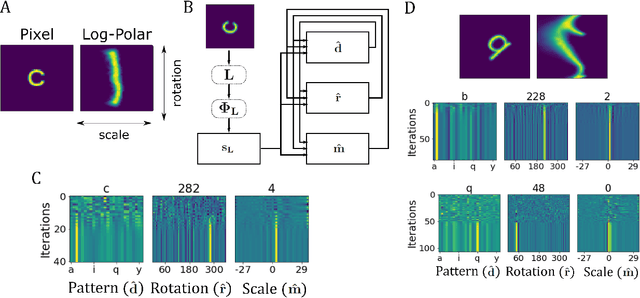
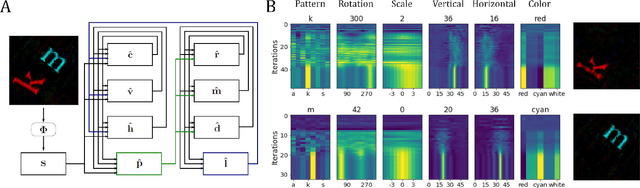
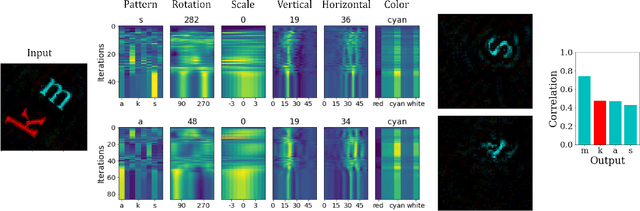
Inferring the position of objects and their rigid transformations is still an open problem in visual scene understanding. Here we propose a neuromorphic solution that utilizes an efficient factorization network which is based on three key concepts: (1) a computational framework based on Vector Symbolic Architectures (VSA) with complex-valued vectors; (2) the design of Hierarchical Resonator Networks (HRN) to deal with the non-commutative nature of translation and rotation in visual scenes, when both are used in combination; (3) the design of a multi-compartment spiking phasor neuron model for implementing complex-valued vector binding on neuromorphic hardware. The VSA framework uses vector binding operations to produce generative image models in which binding acts as the equivariant operation for geometric transformations. A scene can therefore be described as a sum of vector products, which in turn can be efficiently factorized by a resonator network to infer objects and their poses. The HRN enables the definition of a partitioned architecture in which vector binding is equivariant for horizontal and vertical translation within one partition, and for rotation and scaling within the other partition. The spiking neuron model allows to map the resonator network onto efficient and low-power neuromorphic hardware. In this work, we demonstrate our approach using synthetic scenes composed of simple 2D shapes undergoing rigid geometric transformations and color changes. A companion paper demonstrates this approach in real-world application scenarios for machine vision and robotics.
Event-driven Vision and Control for UAVs on a Neuromorphic Chip
Aug 19, 2021
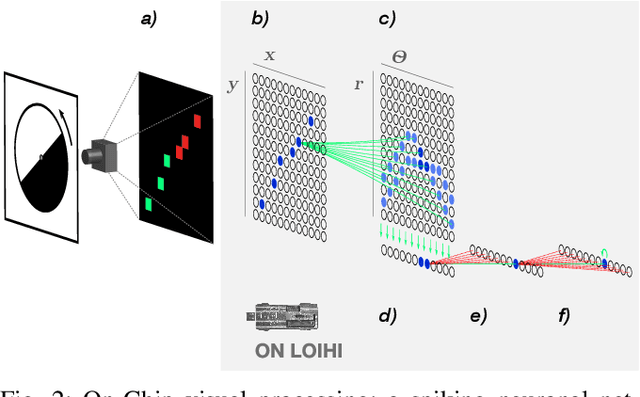


Event-based vision sensors achieve up to three orders of magnitude better speed vs. power consumption trade off in high-speed control of UAVs compared to conventional image sensors. Event-based cameras produce a sparse stream of events that can be processed more efficiently and with a lower latency than images, enabling ultra-fast vision-driven control. Here, we explore how an event-based vision algorithm can be implemented as a spiking neuronal network on a neuromorphic chip and used in a drone controller. We show how seamless integration of event-based perception on chip leads to even faster control rates and lower latency. In addition, we demonstrate how online adaptation of the SNN controller can be realised using on-chip learning. Our spiking neuronal network on chip is the first example of a neuromorphic vision-based controller solving a high-speed UAV control task. The excellent scalability of processing in neuromorphic hardware opens the possibility to solve more challenging visual tasks in the future and integrate visual perception in fast control loops.
The Backpropagation Algorithm Implemented on Spiking Neuromorphic Hardware
Jun 13, 2021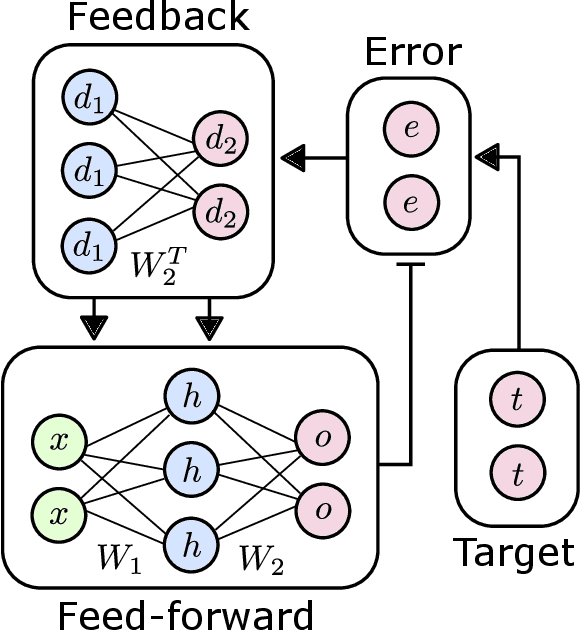
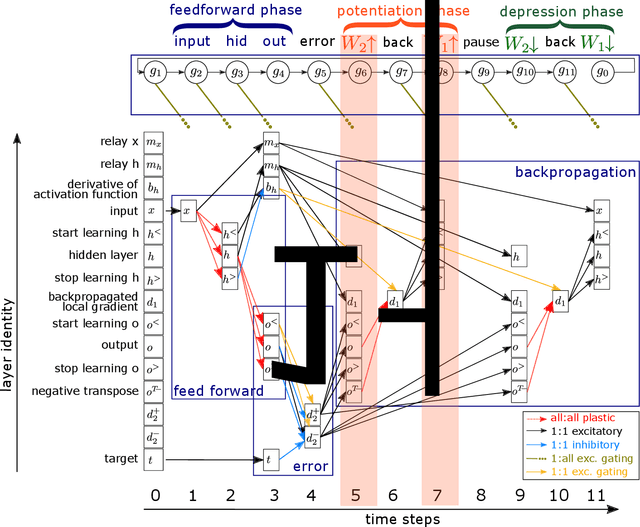
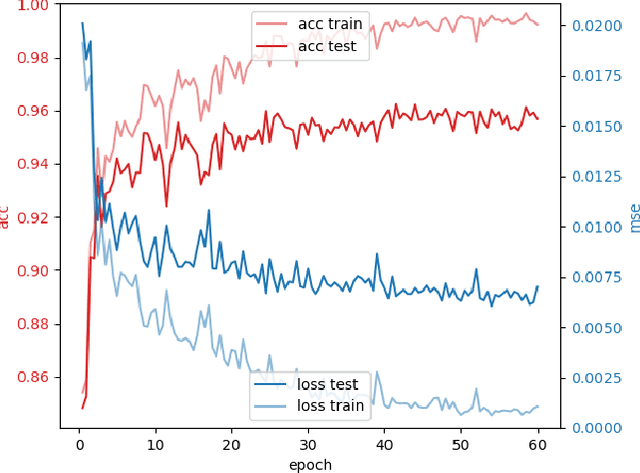

The capabilities of natural neural systems have inspired new generations of machine learning algorithms as well as neuromorphic very large-scale integrated (VLSI) circuits capable of fast, low-power information processing. However, most modern machine learning algorithms are not neurophysiologically plausible and thus are not directly implementable in neuromorphic hardware. In particular, the workhorse of modern deep learning, the backpropagation algorithm, has proven difficult to translate to neuromorphic hardware. In this study, we present a neuromorphic, spiking backpropagation algorithm based on pulse-gated dynamical information coordination and processing, implemented on Intel's Loihi neuromorphic research processor. We demonstrate a proof-of-principle three-layer circuit that learns to classify digits from the MNIST dataset. This implementation shows a path for using massively parallel, low-power, low-latency neuromorphic processors in modern deep learning applications.
Visual Pattern Recognition with on On-chip Learning: towards a Fully Neuromorphic Approach
Aug 08, 2020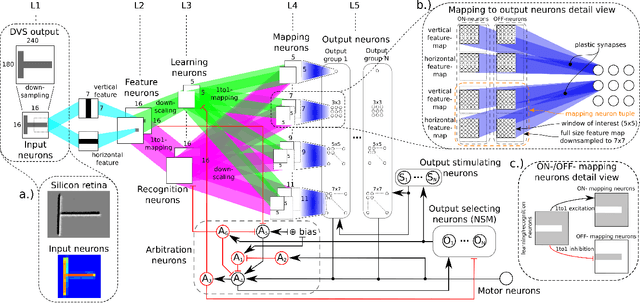


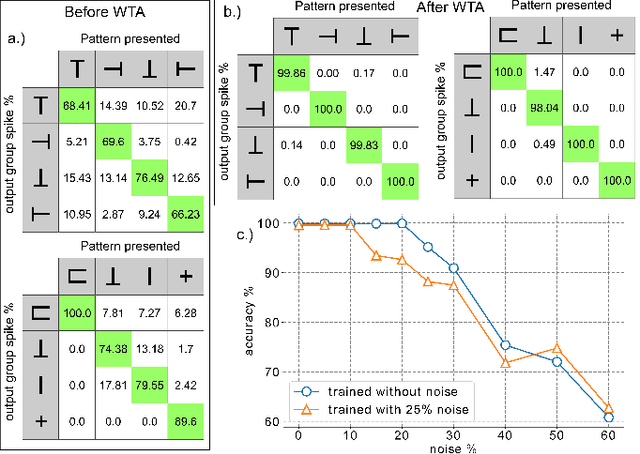
We present a spiking neural network (SNN) for visual pattern recognition with on-chip learning on neuromorphichardware. We show how this network can learn simple visual patterns composed of horizontal and vertical bars sensed by a Dynamic Vision Sensor, using a local spike-based plasticity rule. During recognition, the network classifies the pattern's identity while at the same time estimating its location and scale. We build on previous work that used learning with neuromorphic hardware in the loop and demonstrate that the proposed network can properly operate with on-chip learning, demonstrating a complete neuromorphic pattern learning and recognition setup. Our results show that the network is robust against noise on the input (no accuracy drop when adding 130% noise) and against up to 20% noise in the neuron parameters.
Event-based attention and tracking on neuromorphic hardware
Jul 09, 2019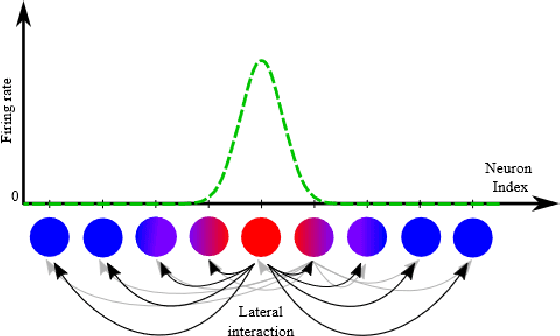
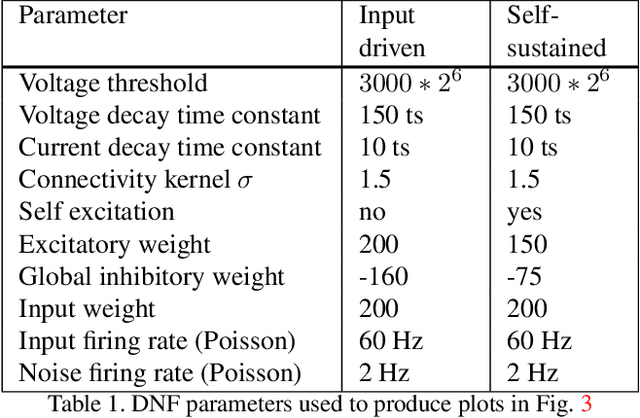
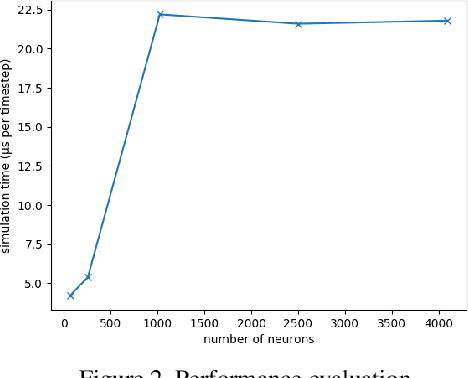
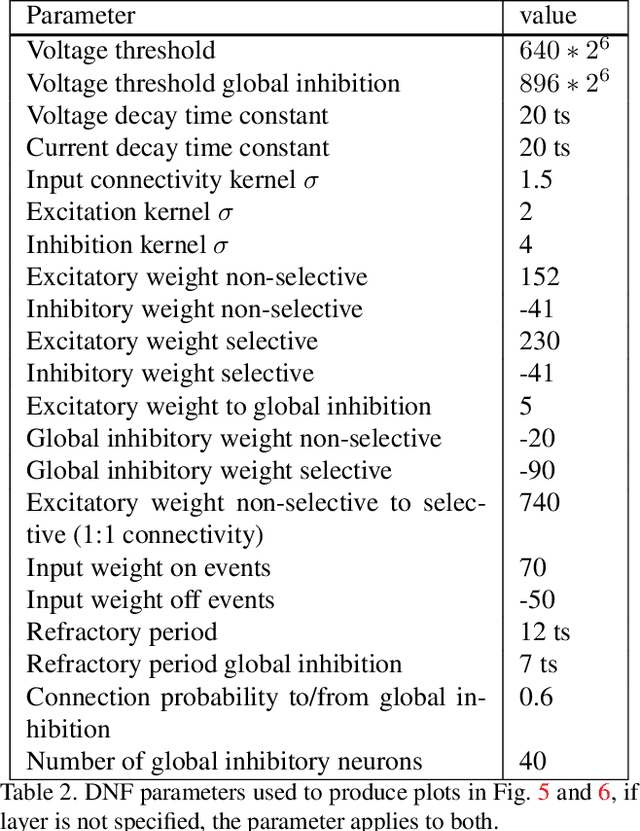
We present a fully event-driven vision and processing system for selective attention and tracking, realized on a neuromorphic processor Loihi interfaced to an event-based Dynamic Vision Sensor DAVIS. The attention mechanism is realized as a recurrent spiking neural network that implements attractor-dynamics of dynamic neural fields. We demonstrate capability of the system to create sustained activation that supports object tracking when distractors are present or when the object slows down or stops, reducing the number of generated events.