 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized multi-object classification and tracking with sparse feature resonator networks
Mar 23, 2026In visual scene understanding tasks, it is essential to capture both invariant and equivariant structure. While neural networks are frequently trained to achieve invariance to transformations such as translation, this often comes at the cost of losing access to equivariant information - e.g., the precise location of an object. Moreover, invariance is not naturally guaranteed through supervised learning alone, and many architectures generalize poorly to input transformations not encountered during training. Here, we take an approach based on analysis-by-synthesis and factoring using resonator networks. A generative model describes the construction of simple scenes containing MNIST digits and their transformations, like color and position. The resonator network inverts the generative model, and provides both invariant and equivariant information about particular objects. Sparse features learned from training data act as a basis set to provide flexibility in representing variable shapes of objects, allowing the resonator network to handle previously unseen digit shapes from the test set. The modular structure provides a shape module which contains information about the object shape with translation factored out, allowing a simple classifier to operate on centered digits. The classification layer is trained solely on centered data, requiring much less training data, and the network as a whole can identify objects with arbitrary translations without data augmentation. The natural attention-like mechanism of the resonator network also allows for analysis of scenes with multiple objects, where the network dynamics selects and centers only one object at a time. Further, the specific position information of a particular object can be extracted from the translation module, and we show that the resonator can be designed to track multiple moving objects with precision of a few pixels.
Learning over time using a neuromorphic adaptive control algorithm for robotic arms
Oct 03, 2022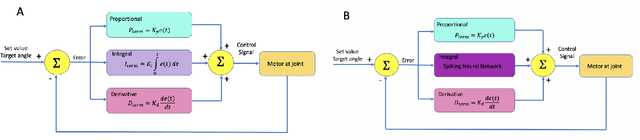

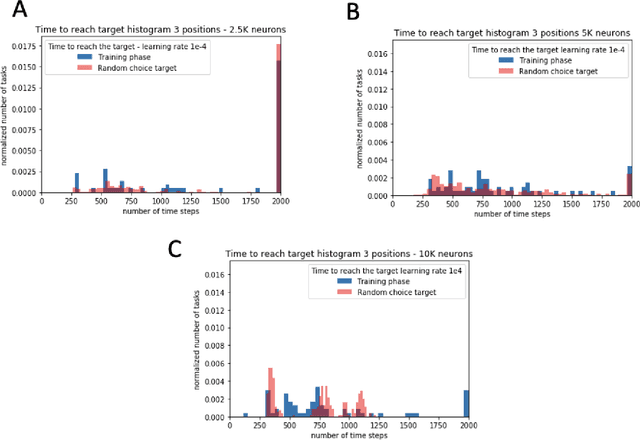
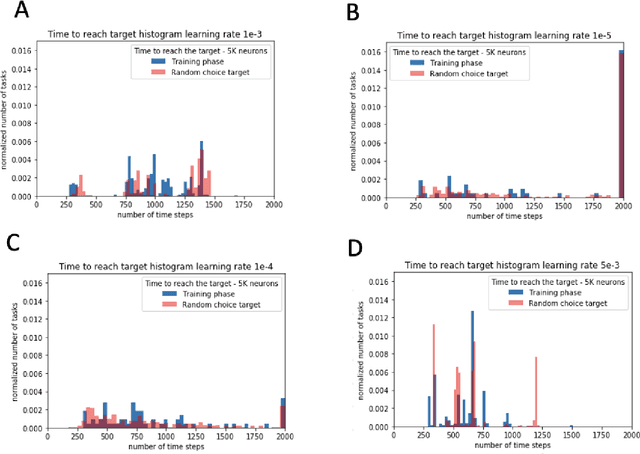
In this paper, we explore the ability of a robot arm to learn the underlying operation space defined by the positions (x, y, z) that the arm's end-effector can reach, including disturbances, by deploying and thoroughly evaluating a Spiking Neural Network SNN-based adaptive control algorithm. While traditional control algorithms for robotics have limitations in both adapting to new and dynamic environments, we show that the robot arm can learn the operational space and complete tasks faster over time. We also demonstrate that the adaptive robot control algorithm based on SNNs enables a fast response while maintaining energy efficiency. We obtained these results by performing an extensive search of the adaptive algorithm parameter space, and evaluating algorithm performance for different SNN network sizes, learning rates, dynamic robot arm trajectories, and response times. We show that the robot arm learns to complete tasks 15% faster in specific experiment scenarios such as scenarios with six or nine random target points.
Bioinspired Smooth Neuromorphic Control for Robotic Arms
Sep 06, 2022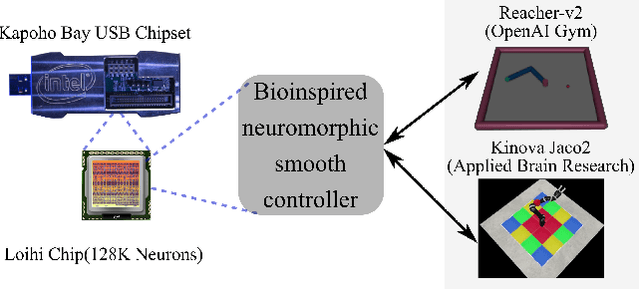
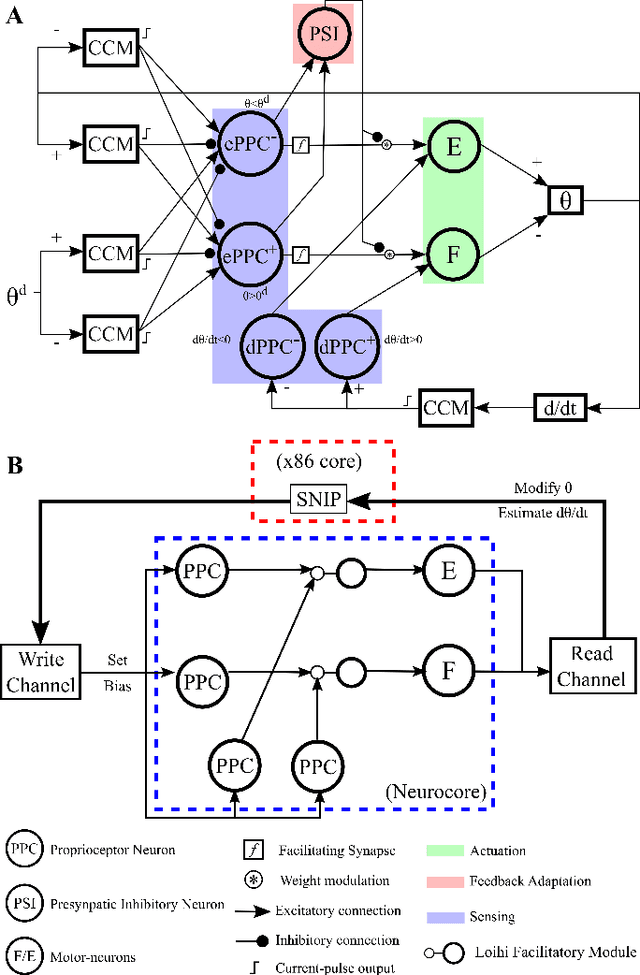
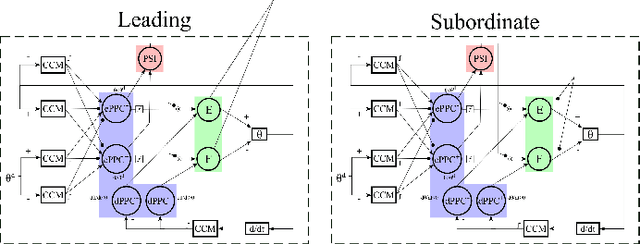
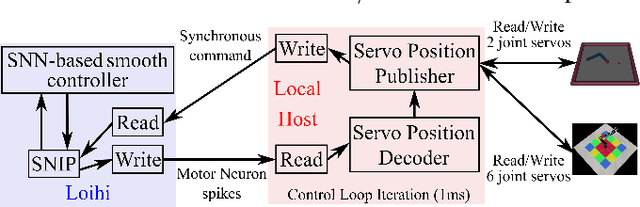
Replicating natural human movements is a long-standing goal of robotics control theory. Drawing inspiration from biology, where reaching control networks give rise to smooth and precise movements, can narrow the performance gap between human and robot control. Neuromorphic processors, which mimic the brain's computational principles, are an ideal platform to approximate the accuracy and smoothness of such controllers while maximizing their energy efficiency and robustness. However, the incompatibility of conventional control methods with neuromorphic hardware limits the computational efficiency and explainability of their existing adaptations. In contrast, the neuronal connectome underlying smooth and accurate reaching movements is effective, minimal, and inherently compatible with neuromorphic processors. In this work, we emulate these networks and propose a biologically realistic spiking neural network for motor control. Our controller incorporates adaptive feedback to provide smooth and accurate motor control while inheriting the minimal complexity of its biological counterpart that controls reaching movements, allowing for direct deployment on Intel's neuromorphic processor. Using our controller as a building block and inspired by joint coordination in human arms, we scaled up our approach to control real-world robot arms. The trajectories and smooth, minimum-jerk velocity profiles of the resulting motions resembled those of humans, verifying the biological relevance of our controller. Notably, our method achieved state-of-the-art control performance while decreasing the motion jerk by 19\% to improve motion smoothness. Our work suggests that exploiting both the computational units of the brain and their connectivity may lead to the design of effective, efficient, and explainable neuromorphic controllers, paving the way for neuromorphic solutions in fully autonomous systems.
Neuromorphic Visual Odometry with Resonator Networks
Sep 05, 2022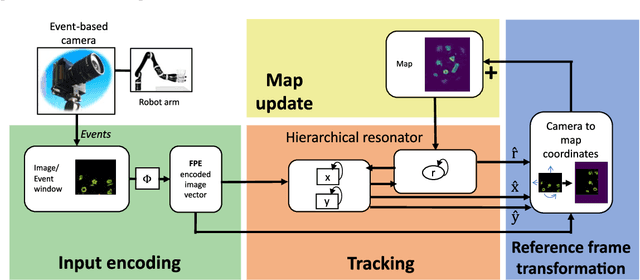
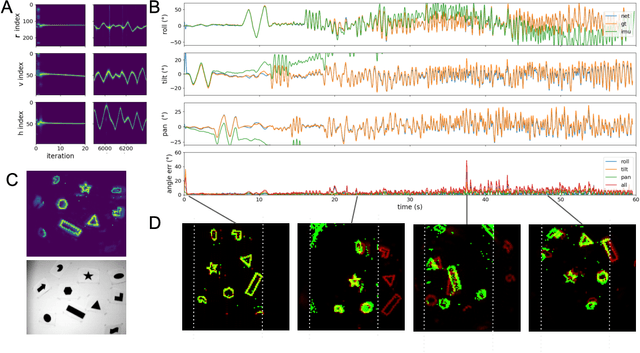
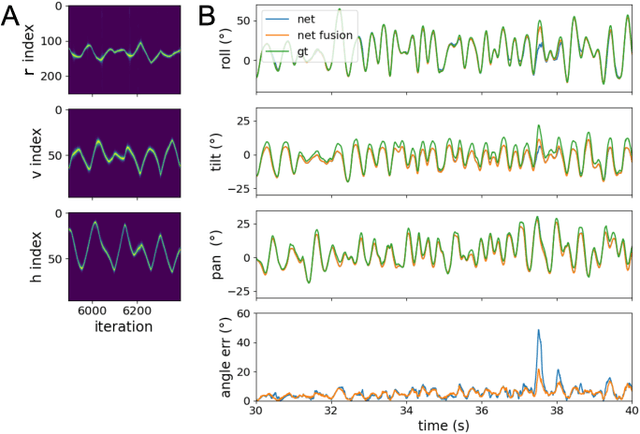
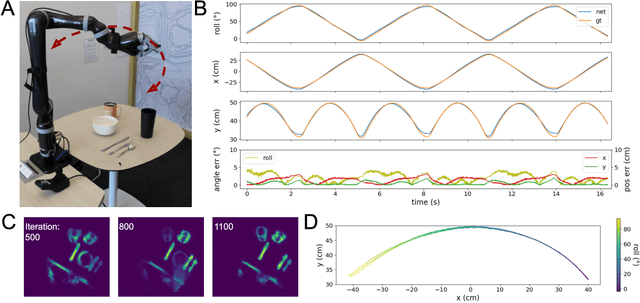
Autonomous agents require self-localization to navigate in unknown environments. They can use Visual Odometry (VO) to estimate self-motion and localize themselves using visual sensors. This motion-estimation strategy is not compromised by drift as inertial sensors or slippage as wheel encoders. However, VO with conventional cameras is computationally demanding, limiting its application in systems with strict low-latency, -memory, and -energy requirements. Using event-based cameras and neuromorphic computing hardware offers a promising low-power solution to the VO problem. However, conventional algorithms for VO are not readily convertible to neuromorphic hardware. In this work, we present a VO algorithm built entirely of neuronal building blocks suitable for neuromorphic implementation. The building blocks are groups of neurons representing vectors in the computational framework of Vector Symbolic Architecture (VSA) which was proposed as an abstraction layer to program neuromorphic hardware. The VO network we propose generates and stores a working memory of the presented visual environment. It updates this working memory while at the same time estimating the changing location and orientation of the camera. We demonstrate how VSA can be leveraged as a computing paradigm for neuromorphic robotics. Moreover, our results represent an important step towards using neuromorphic computing hardware for fast and power-efficient VO and the related task of simultaneous localization and mapping (SLAM). We validate this approach experimentally in a robotic task and with an event-based dataset, demonstrating state-of-the-art performance.
Neuromorphic Visual Scene Understanding with Resonator Networks
Aug 26, 2022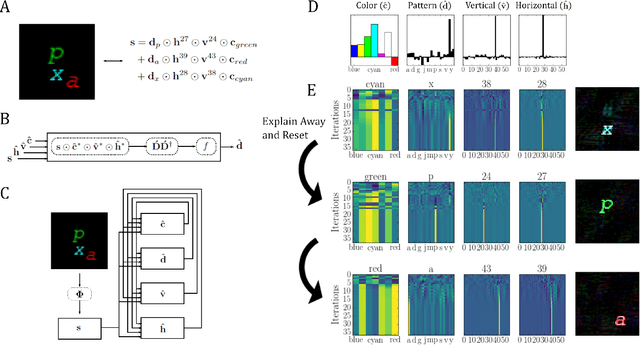
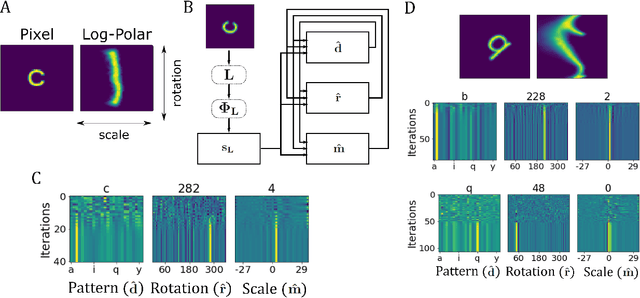
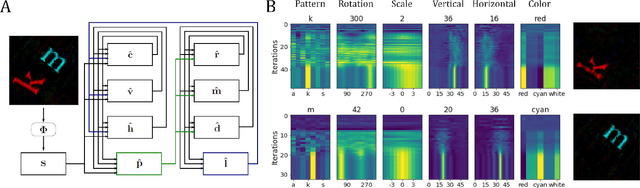
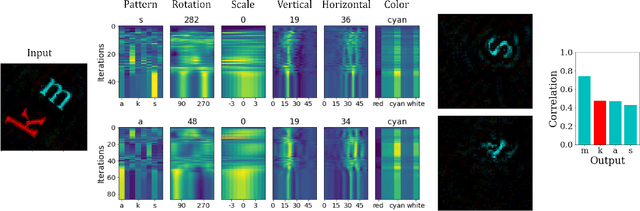
Inferring the position of objects and their rigid transformations is still an open problem in visual scene understanding. Here we propose a neuromorphic solution that utilizes an efficient factorization network which is based on three key concepts: (1) a computational framework based on Vector Symbolic Architectures (VSA) with complex-valued vectors; (2) the design of Hierarchical Resonator Networks (HRN) to deal with the non-commutative nature of translation and rotation in visual scenes, when both are used in combination; (3) the design of a multi-compartment spiking phasor neuron model for implementing complex-valued vector binding on neuromorphic hardware. The VSA framework uses vector binding operations to produce generative image models in which binding acts as the equivariant operation for geometric transformations. A scene can therefore be described as a sum of vector products, which in turn can be efficiently factorized by a resonator network to infer objects and their poses. The HRN enables the definition of a partitioned architecture in which vector binding is equivariant for horizontal and vertical translation within one partition, and for rotation and scaling within the other partition. The spiking neuron model allows to map the resonator network onto efficient and low-power neuromorphic hardware. In this work, we demonstrate our approach using synthetic scenes composed of simple 2D shapes undergoing rigid geometric transformations and color changes. A companion paper demonstrates this approach in real-world application scenarios for machine vision and robotics.
Gesture Similarity Analysis on Event Data Using a Hybrid Guided Variational Auto Encoder
Mar 31, 2021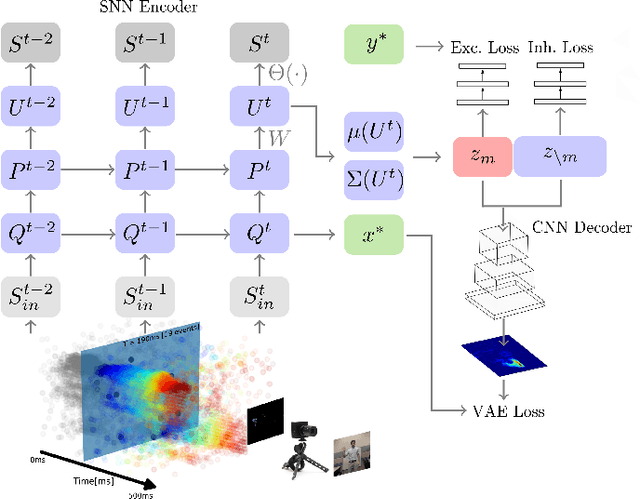
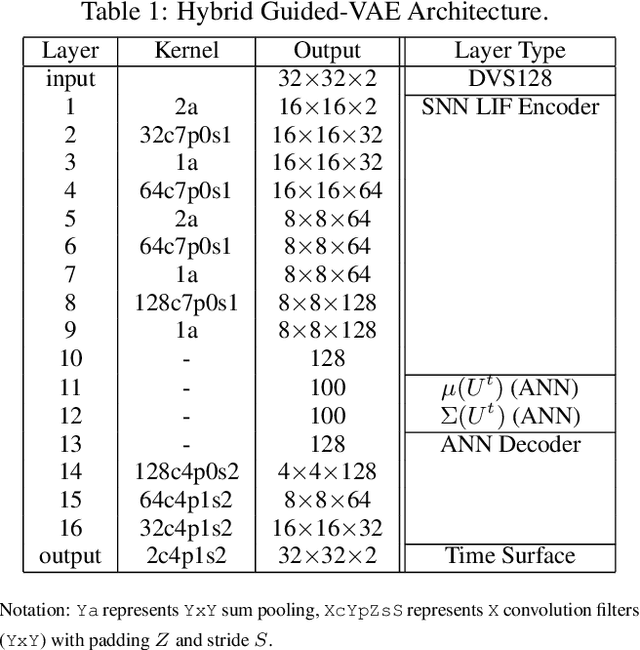
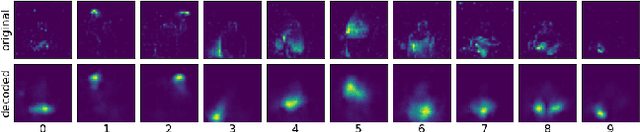

While commercial mid-air gesture recognition systems have existed for at least a decade, they have not become a widespread method of interacting with machines. This is primarily due to the fact that these systems require rigid, dramatic gestures to be performed for accurate recognition that can be fatiguing and unnatural. The global pandemic has seen a resurgence of interest in touchless interfaces, so new methods that allow for natural mid-air gestural interactions are even more important. To address the limitations of recognition systems, we propose a neuromorphic gesture analysis system which naturally declutters the background and analyzes gestures at high temporal resolution. Our novel model consists of an event-based guided Variational Autoencoder (VAE) which encodes event-based data sensed by a Dynamic Vision Sensor (DVS) into a latent space representation suitable to analyze and compute the similarity of mid-air gesture data. Our results show that the features learned by the VAE provides a similarity measure capable of clustering and pseudo labeling of new gestures. Furthermore, we argue that the resulting event-based encoder and pseudo-labeling system are suitable for implementation in neuromorphic hardware for online adaptation and learning of natural mid-air gestures.
Tuning Algorithms and Generators for Efficient Edge Inference
Jul 31, 2019


A surge in artificial intelligence and autonomous technologies have increased the demand toward enhanced edge-processing capabilities. Computational complexity and size of state-of-the-art Deep Neural Networks (DNNs) are rising exponentially with diverse network models and larger datasets. This growth limits the performance scaling and energy-efficiency of both distributed and embedded inference platforms. Embedded designs at the edge are constrained by energy and speed limitations of available processor substrates and processor to memory communication required to fetch the model coefficients. While many hardware accelerator and network deployment frameworks have been in development, a framework is needed to allow the variety of existing architectures, and those in development, to be expressed in critical parts of the flow that perform various optimization steps. Moreover, premature architecture-blind network selection and optimization diminish the effectiveness of schedule optimizations and hardware-specific mappings. In this paper, we address these issues by creating a cross-layer software-hardware design framework that encompasses network training and model compression that is aware of and tuned to the underlying hardware architecture. This approach leverages the available degrees of DNN structure and sparsity to create a converged network that can be partitioned and efficiently scheduled on the target hardware platform, minimizing data movement, and improving the overall throughput and energy. To further streamline the design, we leverage the high-level, flexible SoC generator platform based on RISC-V ROCC framework. This integration allows seamless extensions of the RISC-V instruction set and Chisel-based rapid generator design. Utilizing this approach, we implemented a silicon prototype in a 16 nm TSMC process node achieving record processing efficiency of up to 18 TOPS/W.
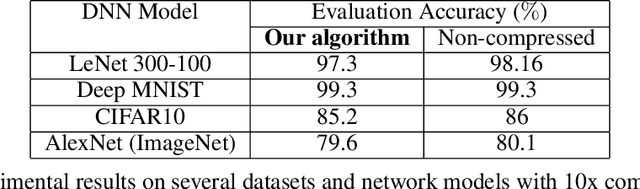
MPDCompress - Matrix Permutation Decomposition Algorithm for Deep Neural Network Compression
May 30, 2018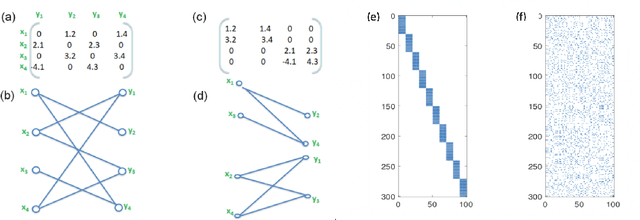
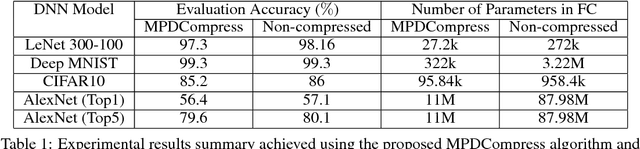
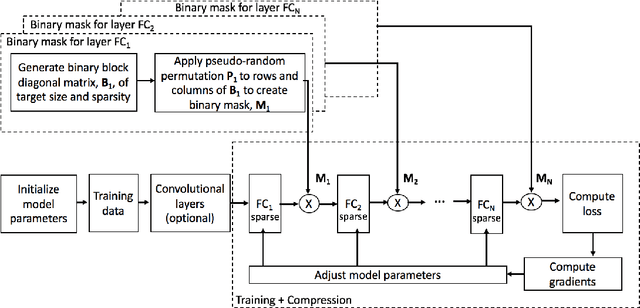

Deep neural networks (DNNs) have become the state-of-the-art technique for machine learning tasks in various applications. However, due to their size and the computational complexity, large DNNs are not readily deployable on edge devices in real-time. To manage complexity and accelerate computation, network compression techniques based on pruning and quantization have been proposed and shown to be effective in reducing network size. However, such network compression can result in irregular matrix structures that are mismatched with modern hardware-accelerated platforms, such as graphics processing units (GPUs) designed to perform the DNN matrix multiplications in a structured (block-based) way. We propose MPDCompress, a DNN compression algorithm based on matrix permutation decomposition via random mask generation. In-training application of the masks molds the synaptic weight connection matrix to a sub-graph separation format. Aided by the random permutations, a hardware-desirable block matrix is generated, allowing for a more efficient implementation and compression of the network. To show versatility, we empirically verify MPDCompress on several network models, compression rates, and image datasets. On the LeNet 300-100 model (MNIST dataset), Deep MNIST, and CIFAR10, we achieve 10 X network compression with less than 1% accuracy loss compared to non-compressed accuracy performance. On AlexNet for the full ImageNet ILSVRC-2012 dataset, we achieve 8 X network compression with less than 1% accuracy loss, with top-5 and top-1 accuracies of 79.6% and 56.4%, respectively. Finally, we observe that the algorithm can offer inference speedups across various hardware platforms, with 4 X faster operation achieved on several mobile GPUs.
Structured Deep Neural Network Pruning via Matrix Pivoting
Dec 01, 2017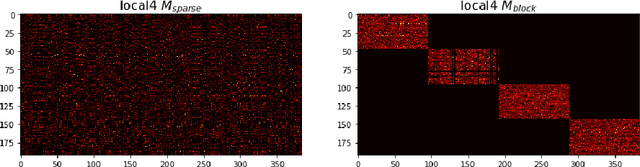
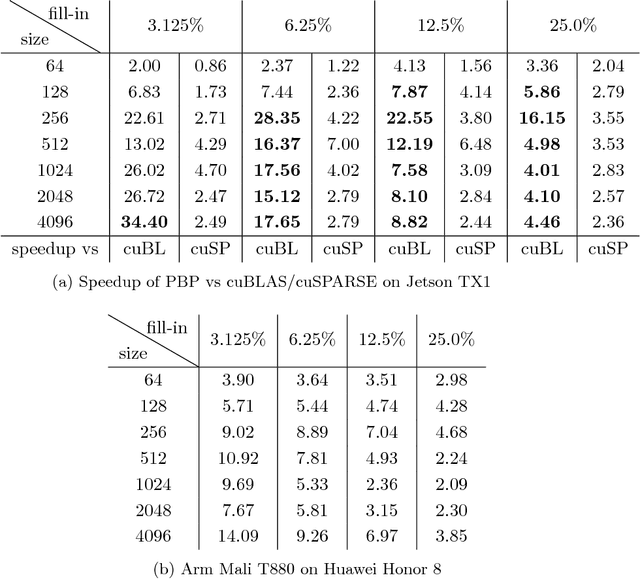
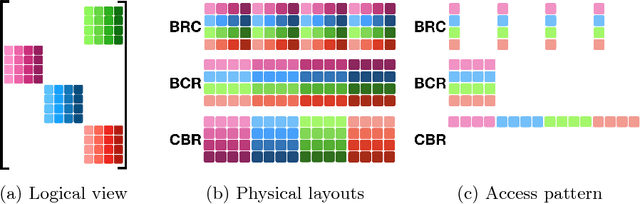
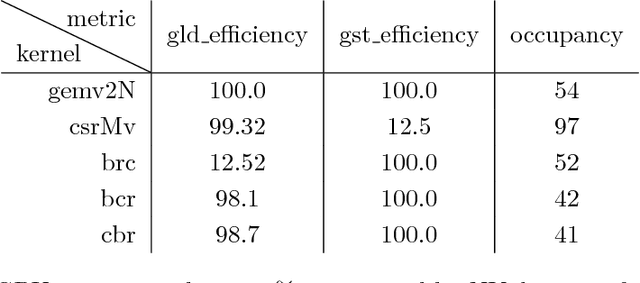
Deep Neural Networks (DNNs) are the key to the state-of-the-art machine vision, sensor fusion and audio/video signal processing. Unfortunately, their computation complexity and tight resource constraints on the Edge make them hard to leverage on mobile, embedded and IoT devices. Due to great diversity of Edge devices, DNN designers have to take into account the hardware platform and application requirements during network training. In this work we introduce pruning via matrix pivoting as a way to improve network pruning by compromising between the design flexibility of architecture-oblivious and performance efficiency of architecture-aware pruning, the two dominant techniques for obtaining resource-efficient DNNs. We also describe local and global network optimization techniques for efficient implementation of the resulting pruned networks. In combination, the proposed pruning and implementation result in close to linear speed up with the reduction of network coefficients during pruning.