 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromorphic Visual Scene Understanding with Resonator Networks
Paper and Code
Aug 26, 2022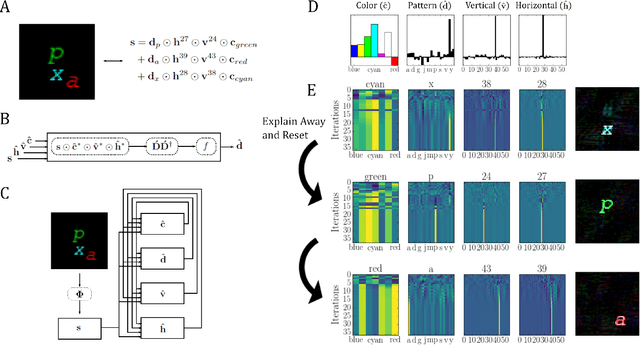
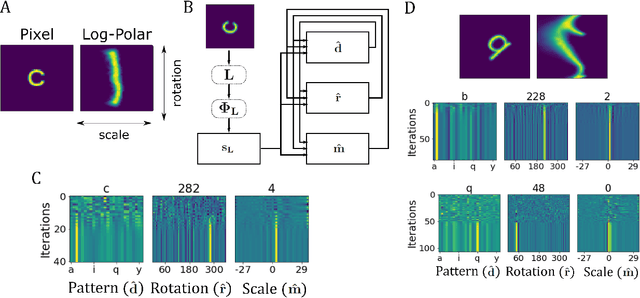
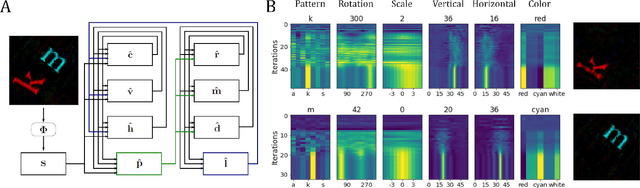
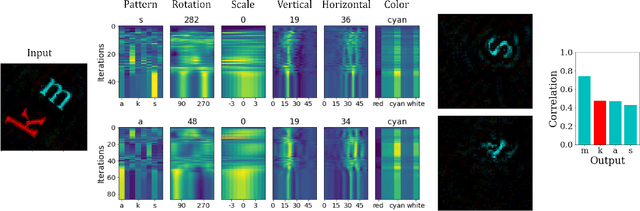
Inferring the position of objects and their rigid transformations is still an open problem in visual scene understanding. Here we propose a neuromorphic solution that utilizes an efficient factorization network which is based on three key concepts: (1) a computational framework based on Vector Symbolic Architectures (VSA) with complex-valued vectors; (2) the design of Hierarchical Resonator Networks (HRN) to deal with the non-commutative nature of translation and rotation in visual scenes, when both are used in combination; (3) the design of a multi-compartment spiking phasor neuron model for implementing complex-valued vector binding on neuromorphic hardware. The VSA framework uses vector binding operations to produce generative image models in which binding acts as the equivariant operation for geometric transformations. A scene can therefore be described as a sum of vector products, which in turn can be efficiently factorized by a resonator network to infer objects and their poses. The HRN enables the definition of a partitioned architecture in which vector binding is equivariant for horizontal and vertical translation within one partition, and for rotation and scaling within the other partition. The spiking neuron model allows to map the resonator network onto efficient and low-power neuromorphic hardware. In this work, we demonstrate our approach using synthetic scenes composed of simple 2D shapes undergoing rigid geometric transformations and color changes. A companion paper demonstrates this approach in real-world application scenarios for machine vision and robotics.