 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromorphic Intermediate Representation: A Unified Instruction Set for Interoperable Brain-Inspired Computing
Nov 24, 2023Spiking neural networks and neuromorphic hardware platforms that emulate neural dynamics are slowly gaining momentum and entering main-stream usage. Despite a well-established mathematical foundation for neural dynamics, the implementation details vary greatly across different platforms. Correspondingly, there are a plethora of software and hardware implementations with their own unique technology stacks. Consequently, neuromorphic systems typically diverge from the expected computational model, which challenges the reproducibility and reliability across platforms. Additionally, most neuromorphic hardware is limited by its access via a single software frameworks with a limited set of training procedures. Here, we establish a common reference-frame for computations in neuromorphic systems, dubbed the Neuromorphic Intermediate Representation (NIR). NIR defines a set of computational primitives as idealized continuous-time hybrid systems that can be composed into graphs and mapped to and from various neuromorphic technology stacks. By abstracting away assumptions around discretization and hardware constraints, NIR faithfully captures the fundamental computation, while simultaneously exposing the exact differences between the evaluated implementation and the idealized mathematical formalism. We reproduce three NIR graphs across 7 neuromorphic simulators and 4 hardware platforms, demonstrating support for an unprecedented number of neuromorphic systems. With NIR, we decouple the evolution of neuromorphic hardware and software, ultimately increasing the interoperability between platforms and improving accessibility to neuromorphic technologies. We believe that NIR is an important step towards the continued study of brain-inspired hardware and bottom-up approaches aimed at an improved understanding of the computational underpinnings of nervous systems.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
Learning over time using a neuromorphic adaptive control algorithm for robotic arms
Oct 03, 2022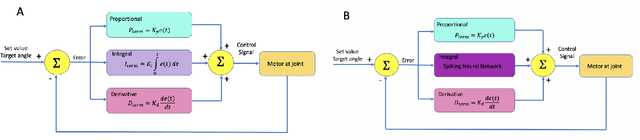

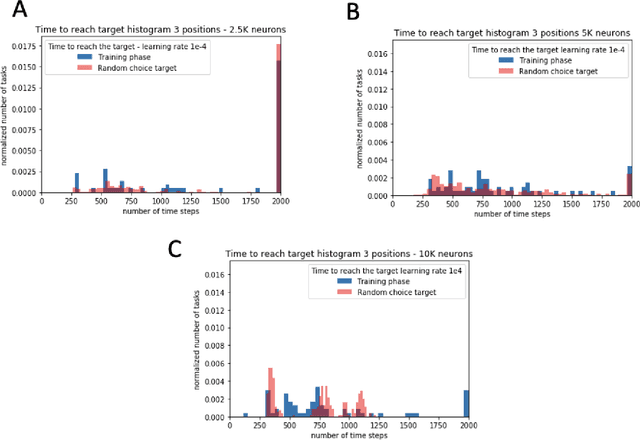
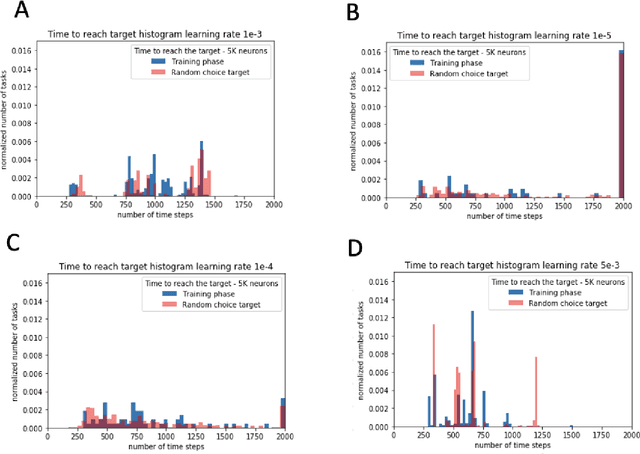
In this paper, we explore the ability of a robot arm to learn the underlying operation space defined by the positions (x, y, z) that the arm's end-effector can reach, including disturbances, by deploying and thoroughly evaluating a Spiking Neural Network SNN-based adaptive control algorithm. While traditional control algorithms for robotics have limitations in both adapting to new and dynamic environments, we show that the robot arm can learn the operational space and complete tasks faster over time. We also demonstrate that the adaptive robot control algorithm based on SNNs enables a fast response while maintaining energy efficiency. We obtained these results by performing an extensive search of the adaptive algorithm parameter space, and evaluating algorithm performance for different SNN network sizes, learning rates, dynamic robot arm trajectories, and response times. We show that the robot arm learns to complete tasks 15% faster in specific experiment scenarios such as scenarios with six or nine random target points.
Dictionary Learning with Accumulator Neurons
May 30, 2022
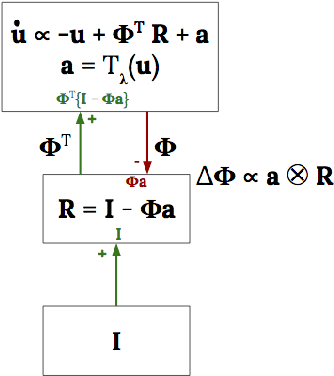
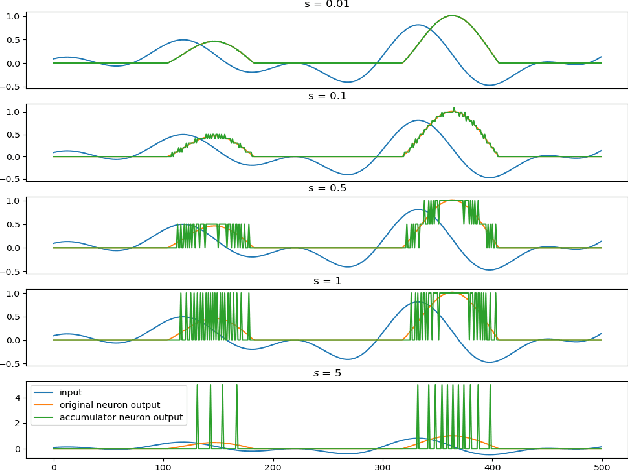

The Locally Competitive Algorithm (LCA) uses local competition between non-spiking leaky integrator neurons to infer sparse representations, allowing for potentially real-time execution on massively parallel neuromorphic architectures such as Intel's Loihi processor. Here, we focus on the problem of inferring sparse representations from streaming video using dictionaries of spatiotemporal features optimized in an unsupervised manner for sparse reconstruction. Non-spiking LCA has previously been used to achieve unsupervised learning of spatiotemporal dictionaries composed of convolutional kernels from raw, unlabeled video. We demonstrate how unsupervised dictionary learning with spiking LCA (\hbox{S-LCA}) can be efficiently implemented using accumulator neurons, which combine a conventional leaky-integrate-and-fire (\hbox{LIF}) spike generator with an additional state variable that is used to minimize the difference between the integrated input and the spiking output. We demonstrate dictionary learning across a wide range of dynamical regimes, from graded to intermittent spiking, for inferring sparse representations of both static images drawn from the CIFAR database as well as video frames captured from a DVS camera. On a classification task that requires identification of the suite from a deck of cards being rapidly flipped through as viewed by a DVS camera, we find essentially no degradation in performance as the LCA model used to infer sparse spatiotemporal representations migrates from graded to spiking. We conclude that accumulator neurons are likely to provide a powerful enabling component of future neuromorphic hardware for implementing online unsupervised learning of spatiotemporal dictionaries optimized for sparse reconstruction of streaming video from event based DVS cameras.
Voltage-Dependent Synaptic Plasticity (VDSP): Unsupervised probabilistic Hebbian plasticity rule based on neurons membrane potential
Apr 14, 2022
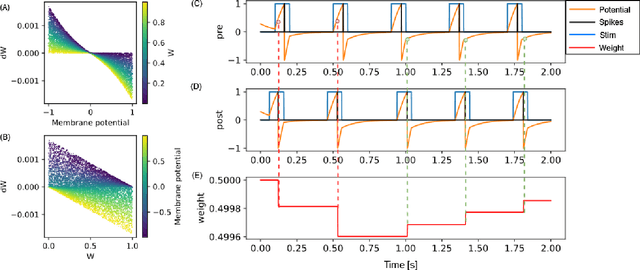
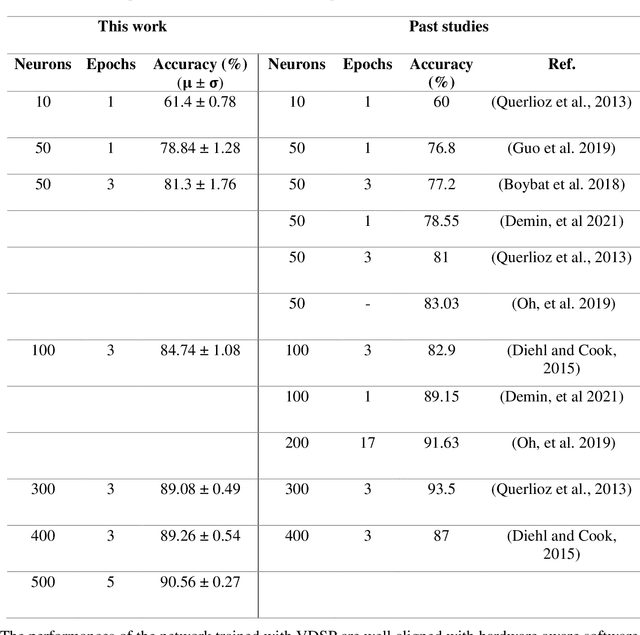
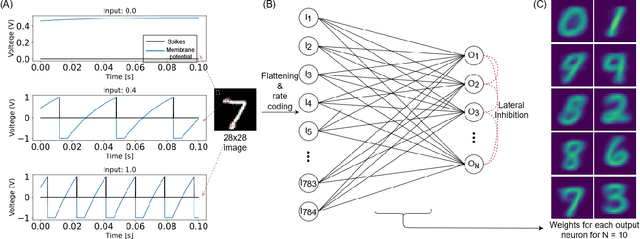
This study proposes voltage-dependent-synaptic plasticity (VDSP), a novel brain-inspired unsupervised local learning rule for the online implementation of Hebb's plasticity mechanism on neuromorphic hardware. The proposed VDSP learning rule updates the synaptic conductance on the spike of the postsynaptic neuron only, which reduces by a factor of two the number of updates with respect to standard spike-timing-dependent plasticity (STDP). This update is dependent on the membrane potential of the presynaptic neuron, which is readily available as part of neuron implementation and hence does not require additional memory for storage. Moreover, the update is also regularized on synaptic weight and prevents explosion or vanishing of weights on repeated stimulation. Rigorous mathematical analysis is performed to draw an equivalence between VDSP and STDP. To validate the system-level performance of VDSP, we train a single-layer spiking neural network (SNN) for the recognition of handwritten digits. We report 85.01 $ \pm $ 0.76% (Mean $ \pm $ S.D.) accuracy for a network of 100 output neurons on the MNIST dataset. The performance improves when scaling the network size (89.93 $ \pm $ 0.41% for 400 output neurons, 90.56 $ \pm $ 0.27 for 500 neurons), which validates the applicability of the proposed learning rule for large-scale computer vision tasks. Interestingly, the learning rule better adapts than STDP to the frequency of input signal and does not require hand-tuning of hyperparameters.
The Importance of Balanced Data Sets: Analyzing a Vehicle Trajectory Prediction Model based on Neural Networks and Distributed Representations
Sep 30, 2020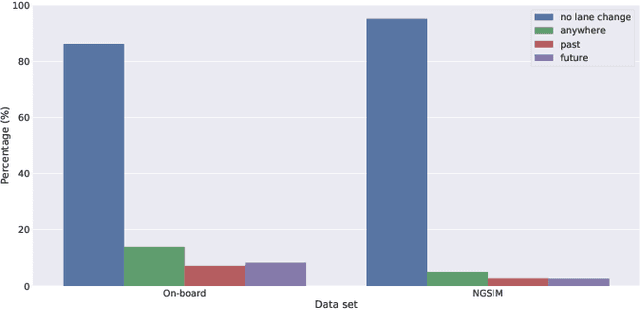


Predicting future behavior of other traffic participants is an essential task that needs to be solved by automated vehicles and human drivers alike to achieve safe and situationaware driving. Modern approaches to vehicles trajectory prediction typically rely on data-driven models like neural networks, in particular LSTMs (Long Short-Term Memorys), achieving promising results. However, the question of optimal composition of the underlying training data has received less attention. In this paper, we expand on previous work on vehicle trajectory prediction based on neural network models employing distributed representations to encode automotive scenes in a semantic vector substrate. We analyze the influence of variations in the training data on the performance of our prediction models. Thereby, we show that the models employing our semantic vector representation outperform the numerical model when trained on an adequate data set and thereby, that the composition of training data in vehicle trajectory prediction is crucial for successful training. We conduct our analysis on challenging real-world driving data.
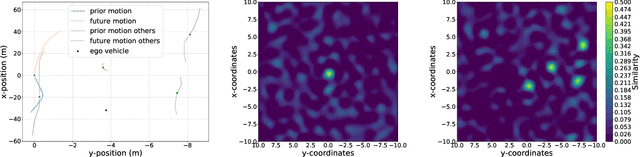
Analyzing the Capacity of Distributed Vector Representations to Encode Spatial Information
Sep 30, 2020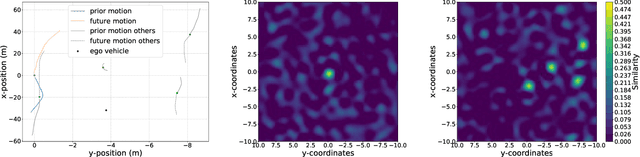
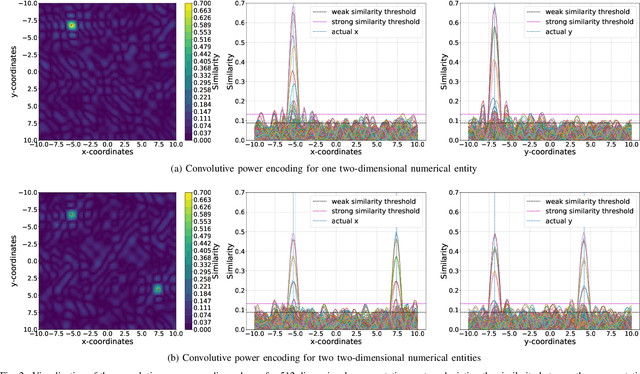
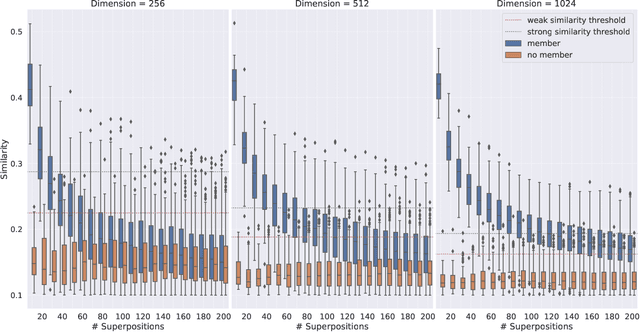
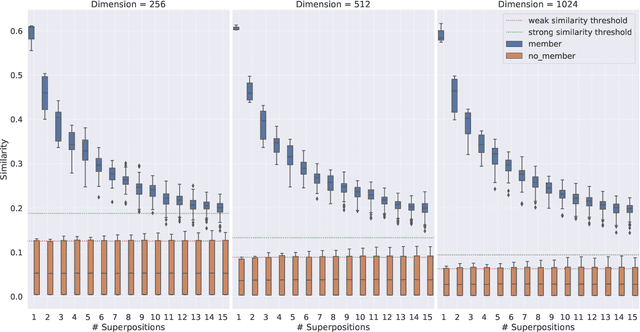
Vector Symbolic Architectures belong to a family of related cognitive modeling approaches that encode symbols and structures in high-dimensional vectors. Similar to human subjects, whose capacity to process and store information or concepts in short-term memory is subject to numerical restrictions,the capacity of information that can be encoded in such vector representations is limited and one way of modeling the numerical restrictions to cognition. In this paper, we analyze these limits regarding information capacity of distributed representations. We focus our analysis on simple superposition and more complex, structured representations involving convolutive powers to encode spatial information. In two experiments, we find upper bounds for the number of concepts that can effectively be stored in a single vector.
Low-Power Low-Latency Keyword Spotting and Adaptive Control with a SpiNNaker 2 Prototype and Comparison with Loihi
Sep 18, 2020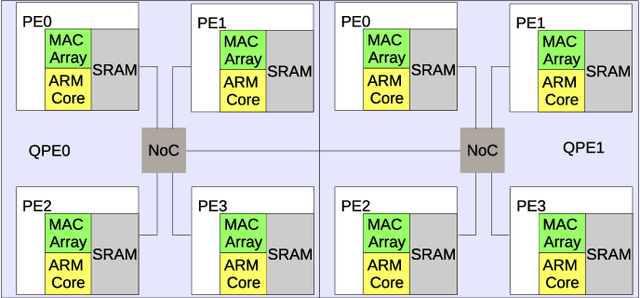
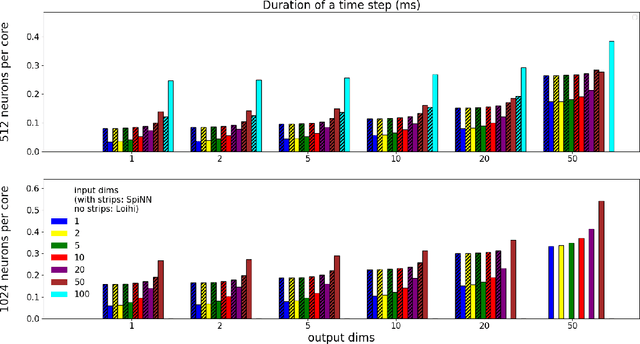
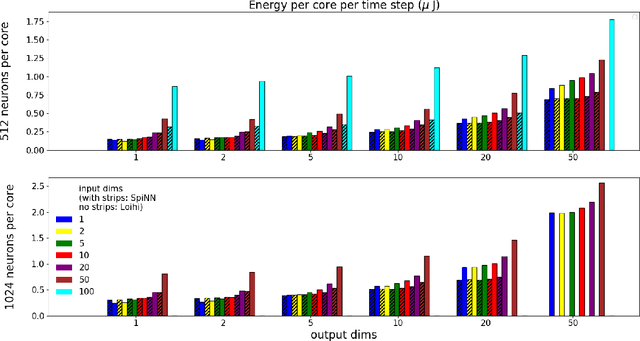
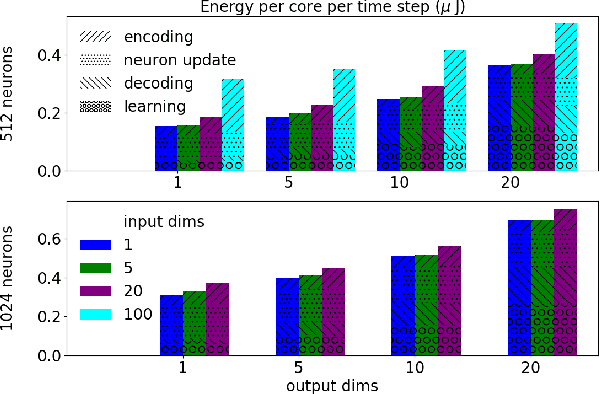
We implemented two neural network based benchmark tasks on a prototype chip of the second-generation SpiNNaker (SpiNNaker 2) neuromorphic system: keyword spotting and adaptive robotic control. Keyword spotting is commonly used in smart speakers to listen for wake words, and adaptive control is used in robotic applications to adapt to unknown dynamics in an online fashion. We highlight the benefit of a multiply accumulate (MAC) array in the SpiNNaker 2 prototype which is ordinarily used in rate-based machine learning networks when employed in a neuromorphic, spiking context. In addition, the same benchmark tasks have been implemented on the Loihi neuromorphic chip, giving a side-by-side comparison regarding power consumption and computation time. While Loihi shows better efficiency when less complicated vector-matrix multiplication is involved, with the MAC array, the SpiNNaker 2 prototype shows better efficiency when high dimensional vector-matrix multiplication is involved.
Reservoir Memory Machines as Neural Computers
Sep 14, 2020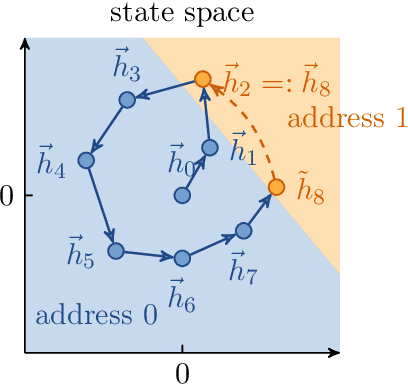

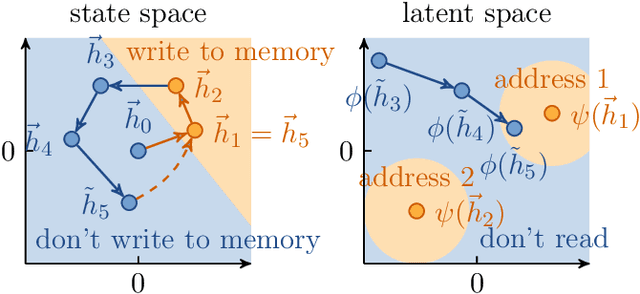

Differentiable neural computers extend artificial neural networks with an explicit memory without interference, thus enabling the model to perform classic computation tasks such as graph traversal. However, such models are difficult to train, requiring long training times and large datasets. In this work, we achieve some of the computational capabilities of differentiable neural computers with a model that can be trained extremely efficiently, namely an echo state network with an explicit memory without interference. This extension raises the computation power of echo state networks from strictly less than finite state machines to strictly more than finite state machines. Further, we demonstrate experimentally that our model performs comparably to its fully-trained deep version on several typical benchmark tasks for differentiable neural computers.
Velocity Regulation of 3D Bipedal Walking Robots with Uncertain Dynamics Through Adaptive Neural Network Controller
Aug 02, 2020
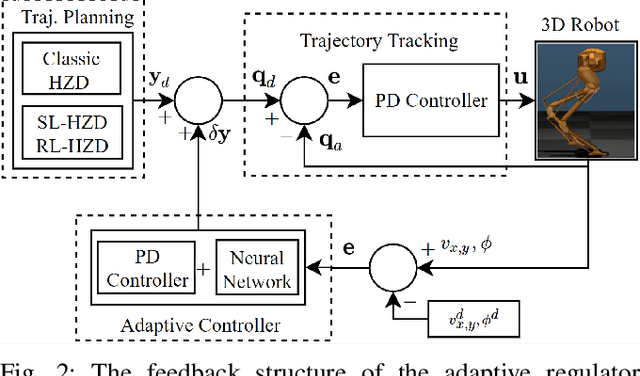
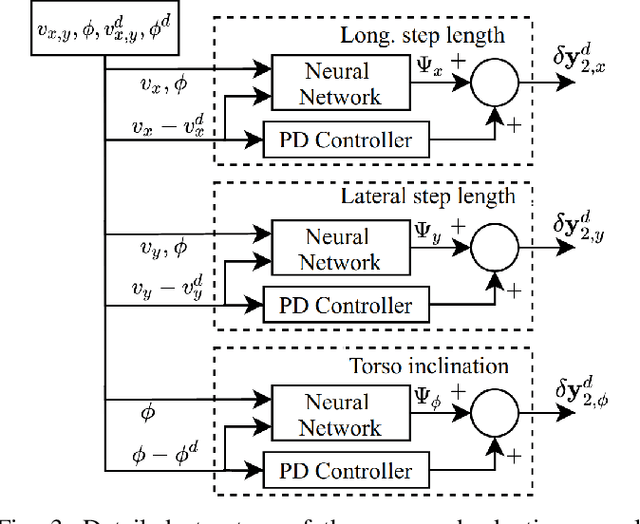
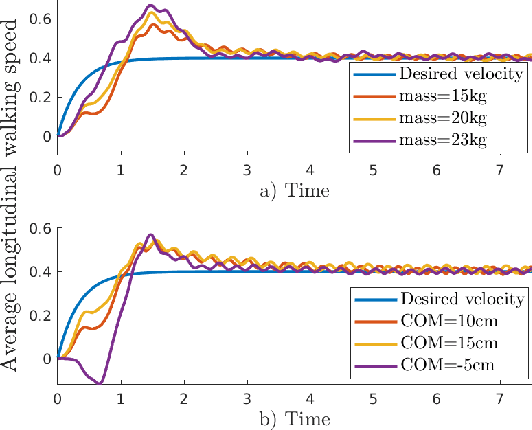
This paper presents a neural-network based adaptive feedback control structure to regulate the velocity of 3D bipedal robots under dynamics uncertainties. Existing Hybrid Zero Dynamics (HZD)-based controllers regulate velocity through the implementation of heuristic regulators that do not consider model and environmental uncertainties, which may significantly affect the tracking performance of the controllers. In this paper, we address the uncertainties in the robot dynamics from the perspective of the reduced dimensional representation of virtual constraints and propose the integration of an adaptive neural network-based controller to regulate the robot velocity in the presence of model parameter uncertainties. The proposed approach yields improved tracking performance under dynamics uncertainties. The shallow adaptive neural network used in this paper does not require training a priori and has the potential to be implemented on the real-time robotic controller. A comparative simulation study of a 3D Cassie robot is presented to illustrate the performance of the proposed approach under various scenarios.