 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Deployment of Spiking Neural Networks on SpiNNaker2 for DVS Gesture Recognition Using Neuromorphic Intermediate Representation
Apr 09, 2025Spiking Neural Networks (SNNs) are highly energy-efficient during inference, making them particularly suitable for deployment on neuromorphic hardware. Their ability to process event-driven inputs, such as data from dynamic vision sensors (DVS), further enhances their applicability to edge computing tasks. However, the resource constraints of edge hardware necessitate techniques like weight quantization, which reduce the memory footprint of SNNs while preserving accuracy. Despite its importance, existing quantization methods typically focus on synaptic weights quantization without taking account of other critical parameters, such as scaling neuron firing thresholds. To address this limitation, we present the first benchmark for the DVS gesture recognition task using SNNs optimized for the many-core neuromorphic chip SpiNNaker2. Our study evaluates two quantization pipelines for fixed-point computations. The first approach employs post training quantization (PTQ) with percentile-based threshold scaling, while the second uses quantization aware training (QAT) with adaptive threshold scaling. Both methods achieve accurate 8-bit on-chip inference, closely approximating 32-bit floating-point performance. Additionally, our baseline SNNs perform competitively against previously reported results without specialized techniques. These models are deployed on SpiNNaker2 using the neuromorphic intermediate representation (NIR). Ultimately, we achieve 94.13% classification accuracy on-chip, demonstrating the SpiNNaker2's potential for efficient, low-energy neuromorphic computing.
* 8 pages, 3 figures, 8 tables, Conference-2025 Neuro Inspired Computational Elements (NICE)
Neuromorphic hardware for sustainable AI data centers
Feb 04, 2024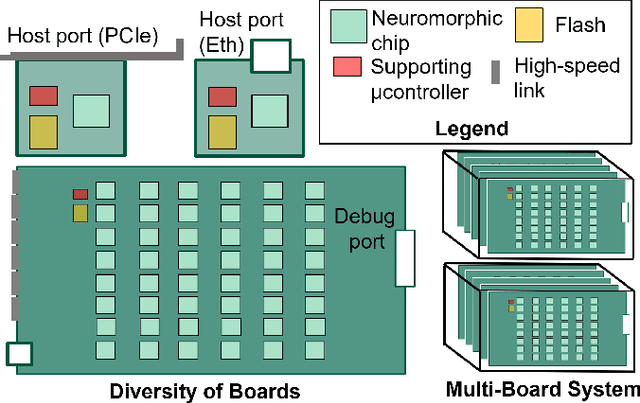
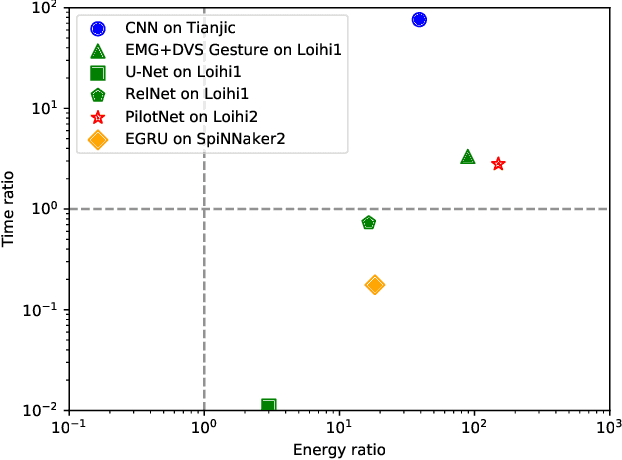
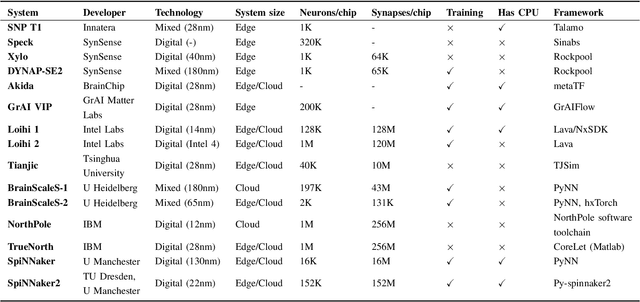

As humans advance toward a higher level of artificial intelligence, it is always at the cost of escalating computational resource consumption, which requires developing novel solutions to meet the exponential growth of AI computing demand. Neuromorphic hardware takes inspiration from how the brain processes information and promises energy-efficient computing of AI workloads. Despite its potential, neuromorphic hardware has not found its way into commercial AI data centers. In this article, we try to analyze the underlying reasons for this and derive requirements and guidelines to promote neuromorphic systems for efficient and sustainable cloud computing: We first review currently available neuromorphic hardware systems and collect examples where neuromorphic solutions excel conventional AI processing on CPUs and GPUs. Next, we identify applications, models and algorithms which are commonly deployed in AI data centers as further directions for neuromorphic algorithms research. Last, we derive requirements and best practices for the hardware and software integration of neuromorphic systems into data centers. With this article, we hope to increase awareness of the challenges of integrating neuromorphic hardware into data centers and to guide the community to enable sustainable and energy-efficient AI at scale.
SpiNNaker2: A Large-Scale Neuromorphic System for Event-Based and Asynchronous Machine Learning
Jan 09, 2024The joint progress of artificial neural networks (ANNs) and domain specific hardware accelerators such as GPUs and TPUs took over many domains of machine learning research. This development is accompanied by a rapid growth of the required computational demands for larger models and more data. Concurrently, emerging properties of foundation models such as in-context learning drive new opportunities for machine learning applications. However, the computational cost of such applications is a limiting factor of the technology in data centers, and more importantly in mobile devices and edge systems. To mediate the energy footprint and non-trivial latency of contemporary systems, neuromorphic computing systems deeply integrate computational principles of neurobiological systems by leveraging low-power analog and digital technologies. SpiNNaker2 is a digital neuromorphic chip developed for scalable machine learning. The event-based and asynchronous design of SpiNNaker2 allows the composition of large-scale systems involving thousands of chips. This work features the operating principles of SpiNNaker2 systems, outlining the prototype of novel machine learning applications. These applications range from ANNs over bio-inspired spiking neural networks to generalized event-based neural networks. With the successful development and deployment of SpiNNaker2, we aim to facilitate the advancement of event-based and asynchronous algorithms for future generations of machine learning systems.
Neuromorphic Intermediate Representation: A Unified Instruction Set for Interoperable Brain-Inspired Computing
Nov 24, 2023Spiking neural networks and neuromorphic hardware platforms that emulate neural dynamics are slowly gaining momentum and entering main-stream usage. Despite a well-established mathematical foundation for neural dynamics, the implementation details vary greatly across different platforms. Correspondingly, there are a plethora of software and hardware implementations with their own unique technology stacks. Consequently, neuromorphic systems typically diverge from the expected computational model, which challenges the reproducibility and reliability across platforms. Additionally, most neuromorphic hardware is limited by its access via a single software frameworks with a limited set of training procedures. Here, we establish a common reference-frame for computations in neuromorphic systems, dubbed the Neuromorphic Intermediate Representation (NIR). NIR defines a set of computational primitives as idealized continuous-time hybrid systems that can be composed into graphs and mapped to and from various neuromorphic technology stacks. By abstracting away assumptions around discretization and hardware constraints, NIR faithfully captures the fundamental computation, while simultaneously exposing the exact differences between the evaluated implementation and the idealized mathematical formalism. We reproduce three NIR graphs across 7 neuromorphic simulators and 4 hardware platforms, demonstrating support for an unprecedented number of neuromorphic systems. With NIR, we decouple the evolution of neuromorphic hardware and software, ultimately increasing the interoperability between platforms and improving accessibility to neuromorphic technologies. We believe that NIR is an important step towards the continued study of brain-inspired hardware and bottom-up approaches aimed at an improved understanding of the computational underpinnings of nervous systems.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
Time-coded Spiking Fourier Transform in Neuromorphic Hardware
Mar 31, 2022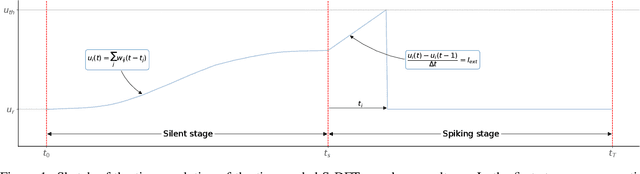

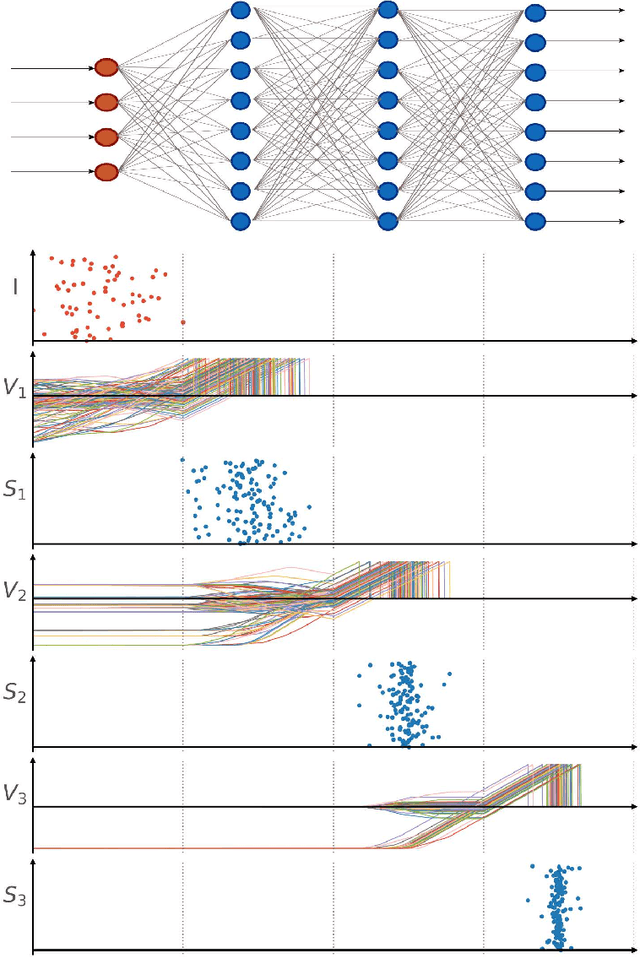
After several decades of continuously optimizing computing systems, the Moore's law is reaching itsend. However, there is an increasing demand for fast and efficient processing systems that can handlelarge streams of data while decreasing system footprints. Neuromorphic computing answers thisneed by creating decentralized architectures that communicate with binary events over time. Despiteits rapid growth in the last few years, novel algorithms are needed that can leverage the potential ofthis emerging computing paradigm and can stimulate the design of advanced neuromorphic chips.In this work, we propose a time-based spiking neural network that is mathematically equivalent tothe Fourier transform. We implemented the network in the neuromorphic chip Loihi and conductedexperiments on five different real scenarios with an automotive frequency modulated continuouswave radar. Experimental results validate the algorithm, and we hope they prompt the design of adhoc neuromorphic chips that can improve the efficiency of state-of-the-art digital signal processorsand encourage research on neuromorphic computing for signal processing.
Low-Power Low-Latency Keyword Spotting and Adaptive Control with a SpiNNaker 2 Prototype and Comparison with Loihi
Sep 18, 2020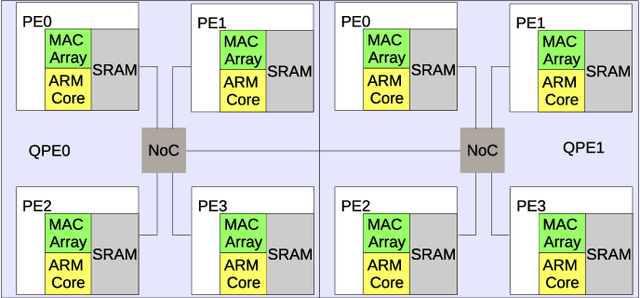
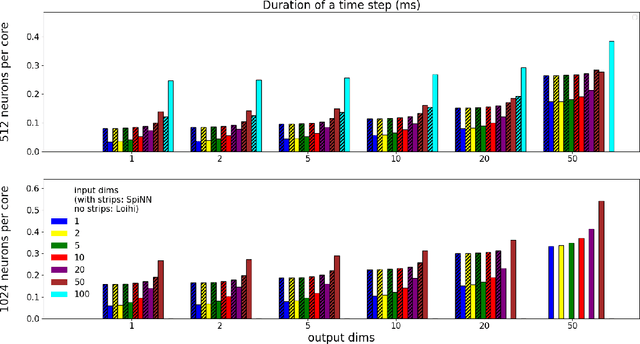
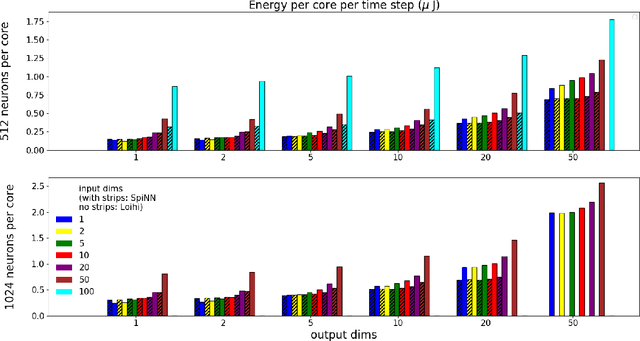
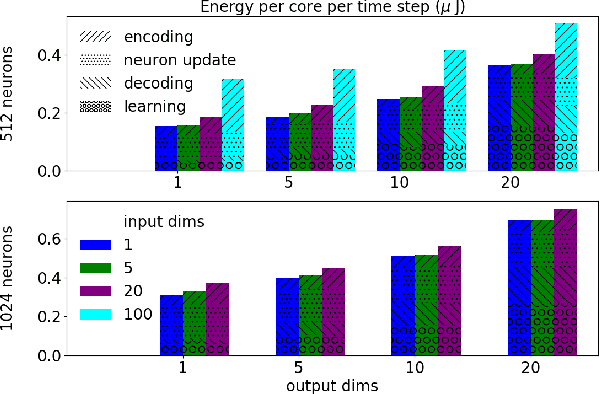
We implemented two neural network based benchmark tasks on a prototype chip of the second-generation SpiNNaker (SpiNNaker 2) neuromorphic system: keyword spotting and adaptive robotic control. Keyword spotting is commonly used in smart speakers to listen for wake words, and adaptive control is used in robotic applications to adapt to unknown dynamics in an online fashion. We highlight the benefit of a multiply accumulate (MAC) array in the SpiNNaker 2 prototype which is ordinarily used in rate-based machine learning networks when employed in a neuromorphic, spiking context. In addition, the same benchmark tasks have been implemented on the Loihi neuromorphic chip, giving a side-by-side comparison regarding power consumption and computation time. While Loihi shows better efficiency when less complicated vector-matrix multiplication is involved, with the MAC array, the SpiNNaker 2 prototype shows better efficiency when high dimensional vector-matrix multiplication is involved.
The Operating System of the Neuromorphic BrainScaleS-1 System
Mar 30, 2020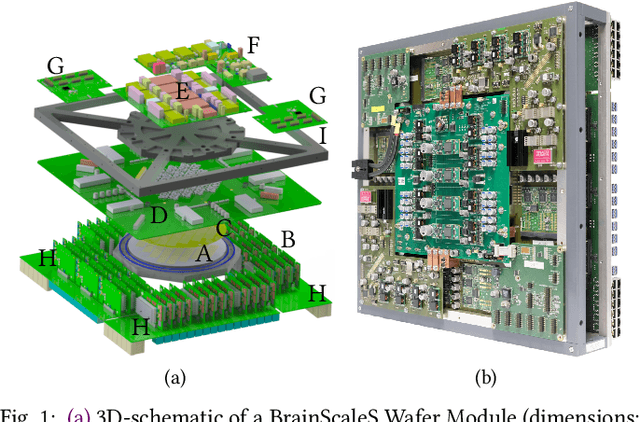
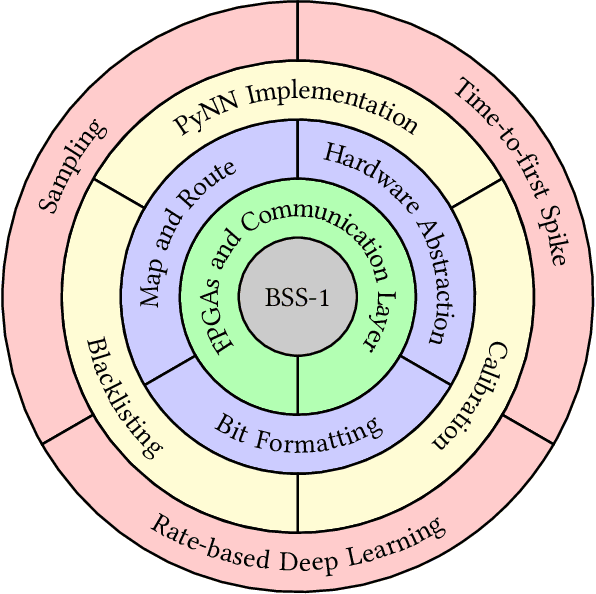
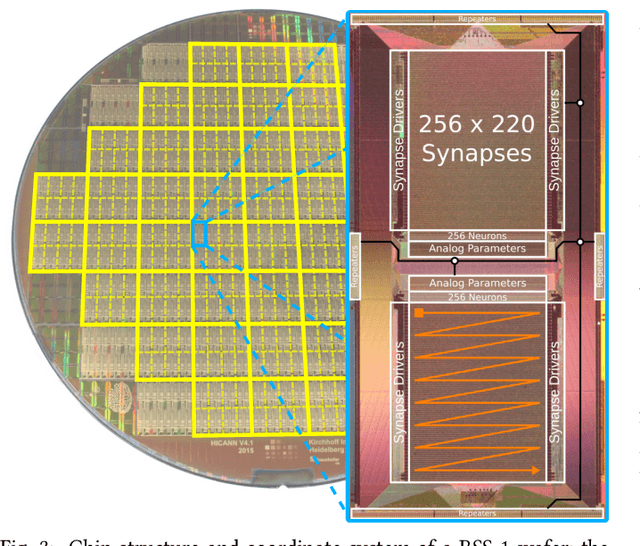
BrainScaleS-1 is a wafer-scale mixed-signal accelerated neuromorphic system targeted for research in the fields of computational neuroscience and beyond-von-Neumann computing. The BrainScaleS Operating System (BrainScaleS OS) is a software stack giving users the possibility to emulate networks described in the high-level network description language PyNN with minimal knowledge of the system. At the same time, expert usage is facilitated by allowing to hook into the system at any depth of the stack. We present operation and development methodologies implemented for the BrainScaleS-1 neuromorphic architecture and walk through the individual components of BrainScaleS OS constituting the software stack for BrainScaleS-1 platform operation.
Dynamic Power Management for Neuromorphic Many-Core Systems
Mar 21, 2019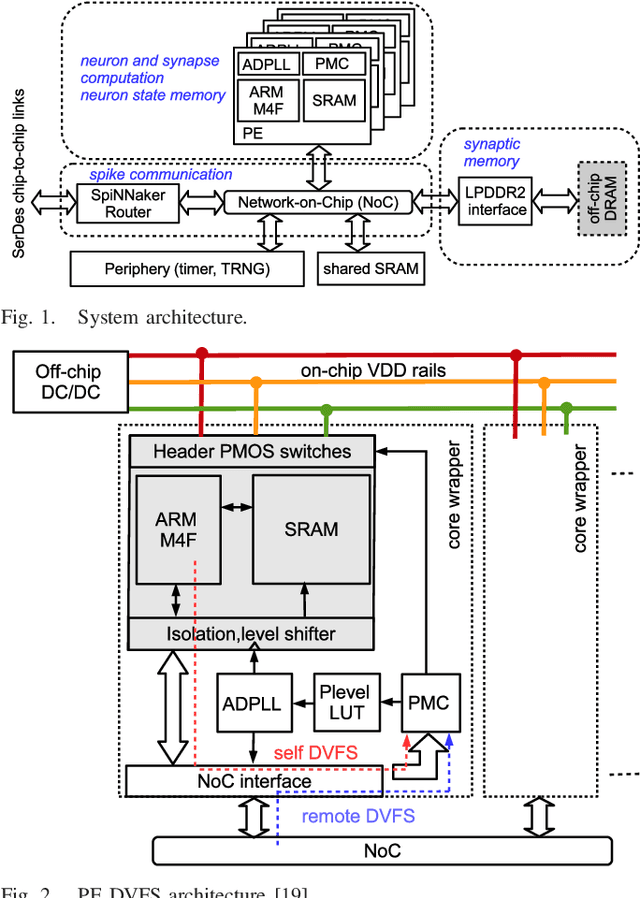

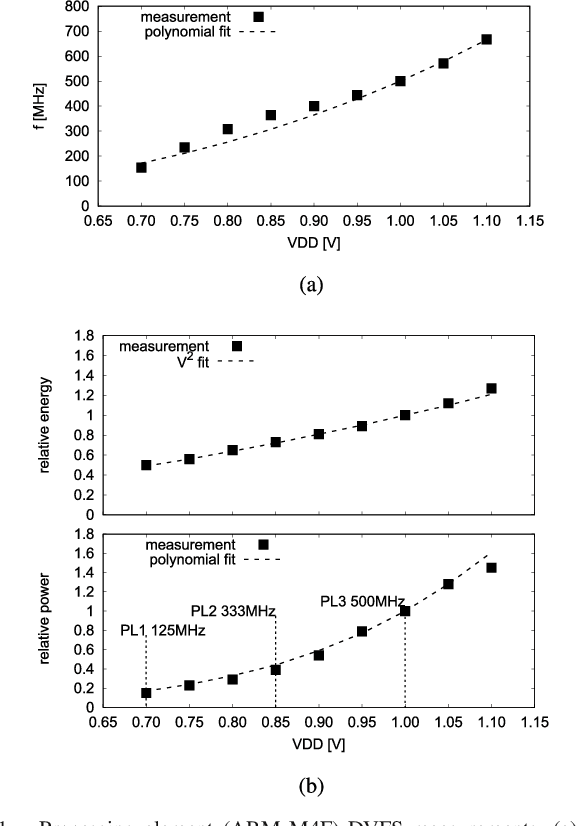
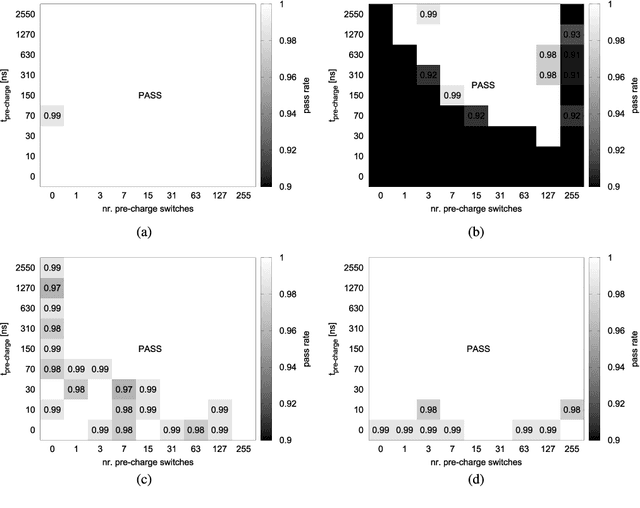
This work presents a dynamic power management architecture for neuromorphic many core systems such as SpiNNaker. A fast dynamic voltage and frequency scaling (DVFS) technique is presented which allows the processing elements (PE) to change their supply voltage and clock frequency individually and autonomously within less than 100 ns. This is employed by the neuromorphic simulation software flow, which defines the performance level (PL) of the PE based on the actual workload within each simulation cycle. A test chip in 28 nm SLP CMOS technology has been implemented. It includes 4 PEs which can be scaled from 0.7 V to 1.0 V with frequencies from 125 MHz to 500 MHz at three distinct PLs. By measurement of three neuromorphic benchmarks it is shown that the total PE power consumption can be reduced by 75%, with 80% baseline power reduction and a 50% reduction of energy per neuron and synapse computation, all while maintaining temporary peak system performance to achieve biological real-time operation of the system. A numerical model of this power management model is derived which allows DVFS architecture exploration for neuromorphics. The proposed technique is to be used for the second generation SpiNNaker neuromorphic many core system.
Efficient Reward-Based Structural Plasticity on a SpiNNaker 2 Prototype
Mar 20, 2019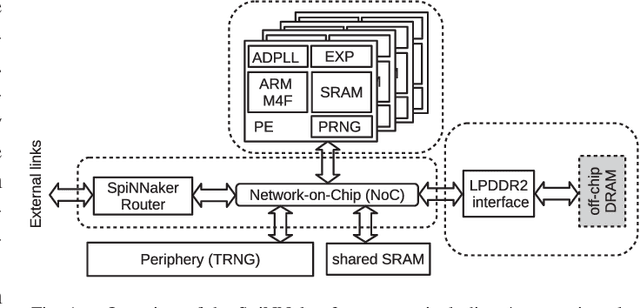
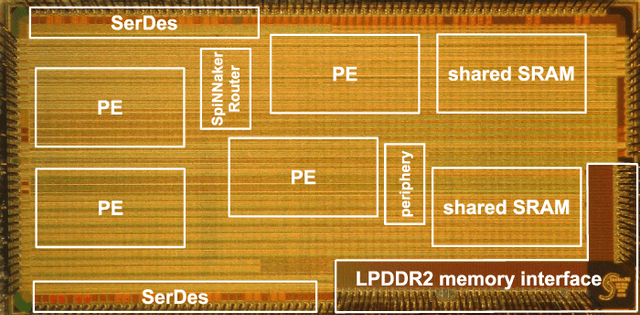
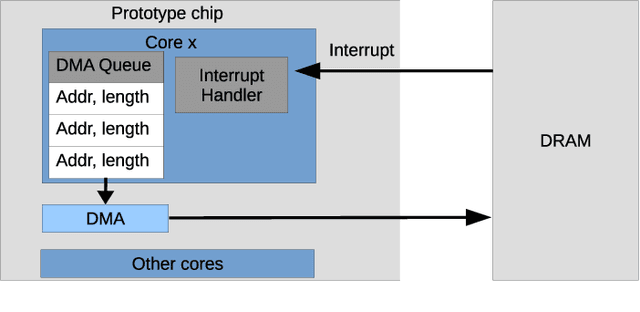
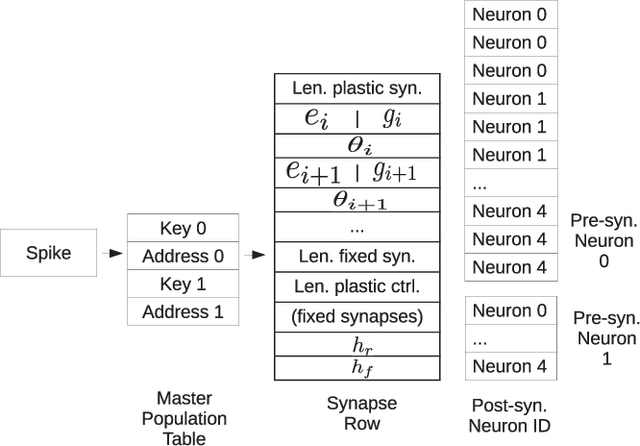
Advances in neuroscience uncover the mechanisms employed by the brain to efficiently solve complex learning tasks with very limited resources. However, the efficiency is often lost when one tries to port these findings to a silicon substrate, since brain-inspired algorithms often make extensive use of complex functions such as random number generators, that are expensive to compute on standard general purpose hardware. The prototype chip of the 2nd generation SpiNNaker system is designed to overcome this problem. Low-power ARM processors equipped with a random number generator and an exponential function accelerator enable the efficient execution of brain-inspired algorithms. We implement the recently introduced reward-based synaptic sampling model that employs structural plasticity to learn a function or task. The numerical simulation of the model requires to update the synapse variables in each time step including an explorative random term. To the best of our knowledge, this is the most complex synapse model implemented so far on the SpiNNaker system. By making efficient use of the hardware accelerators and numerical optimizations the computation time of one plasticity update is reduced by a factor of 2. This, combined with fitting the model into to the local SRAM, leads to 62% energy reduction compared to the case without accelerators and the use of external DRAM. The model implementation is integrated into the SpiNNaker software framework allowing for scalability onto larger systems. The hardware-software system presented in this work paves the way for power-efficient mobile and biomedical applications with biologically plausible brain-inspired algorithms.