 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiNNaker2: A Large-Scale Neuromorphic System for Event-Based and Asynchronous Machine Learning
Jan 09, 2024The joint progress of artificial neural networks (ANNs) and domain specific hardware accelerators such as GPUs and TPUs took over many domains of machine learning research. This development is accompanied by a rapid growth of the required computational demands for larger models and more data. Concurrently, emerging properties of foundation models such as in-context learning drive new opportunities for machine learning applications. However, the computational cost of such applications is a limiting factor of the technology in data centers, and more importantly in mobile devices and edge systems. To mediate the energy footprint and non-trivial latency of contemporary systems, neuromorphic computing systems deeply integrate computational principles of neurobiological systems by leveraging low-power analog and digital technologies. SpiNNaker2 is a digital neuromorphic chip developed for scalable machine learning. The event-based and asynchronous design of SpiNNaker2 allows the composition of large-scale systems involving thousands of chips. This work features the operating principles of SpiNNaker2 systems, outlining the prototype of novel machine learning applications. These applications range from ANNs over bio-inspired spiking neural networks to generalized event-based neural networks. With the successful development and deployment of SpiNNaker2, we aim to facilitate the advancement of event-based and asynchronous algorithms for future generations of machine learning systems.
Low-Power Low-Latency Keyword Spotting and Adaptive Control with a SpiNNaker 2 Prototype and Comparison with Loihi
Sep 18, 2020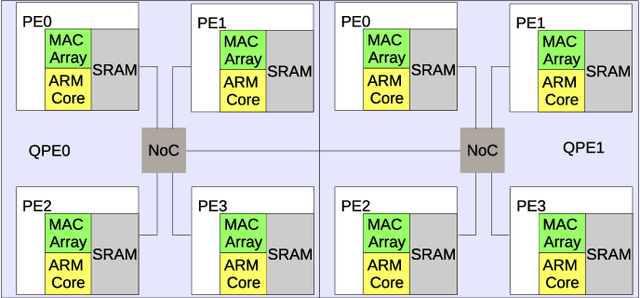
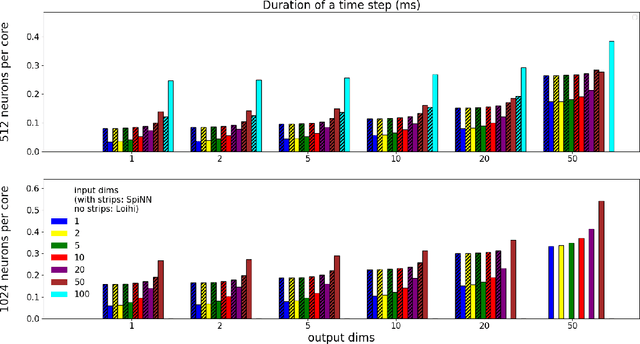
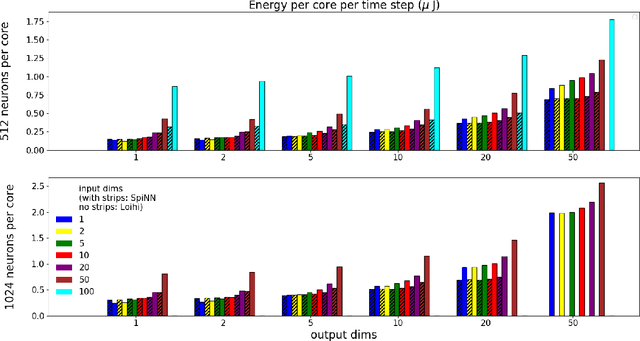
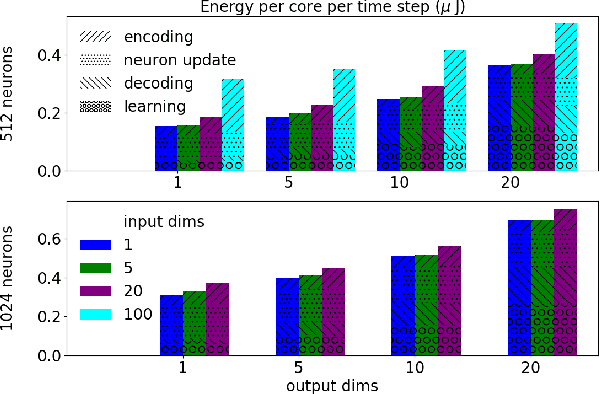
We implemented two neural network based benchmark tasks on a prototype chip of the second-generation SpiNNaker (SpiNNaker 2) neuromorphic system: keyword spotting and adaptive robotic control. Keyword spotting is commonly used in smart speakers to listen for wake words, and adaptive control is used in robotic applications to adapt to unknown dynamics in an online fashion. We highlight the benefit of a multiply accumulate (MAC) array in the SpiNNaker 2 prototype which is ordinarily used in rate-based machine learning networks when employed in a neuromorphic, spiking context. In addition, the same benchmark tasks have been implemented on the Loihi neuromorphic chip, giving a side-by-side comparison regarding power consumption and computation time. While Loihi shows better efficiency when less complicated vector-matrix multiplication is involved, with the MAC array, the SpiNNaker 2 prototype shows better efficiency when high dimensional vector-matrix multiplication is involved.
Dynamic Power Management for Neuromorphic Many-Core Systems
Mar 21, 2019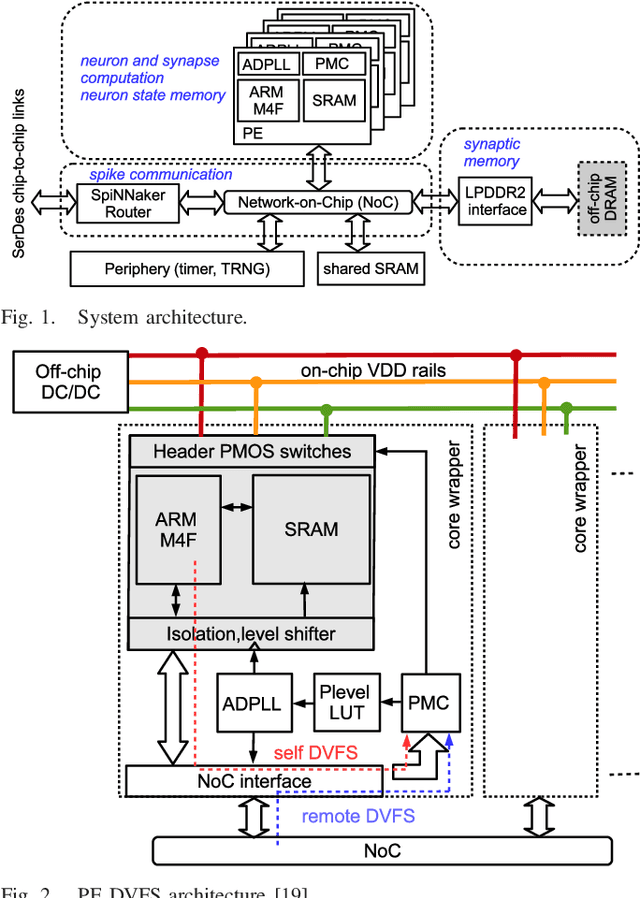

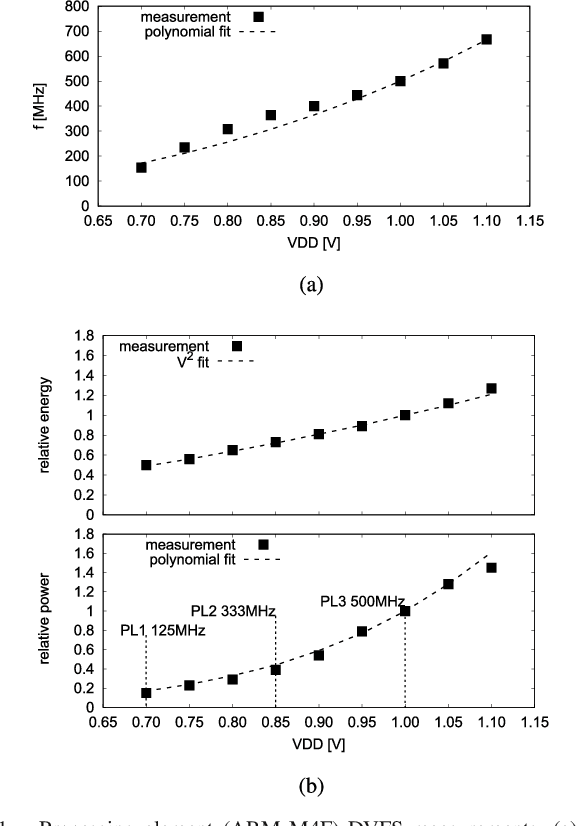
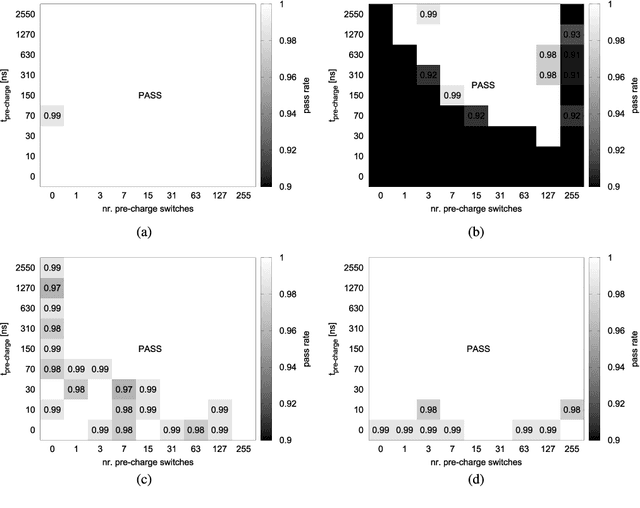
This work presents a dynamic power management architecture for neuromorphic many core systems such as SpiNNaker. A fast dynamic voltage and frequency scaling (DVFS) technique is presented which allows the processing elements (PE) to change their supply voltage and clock frequency individually and autonomously within less than 100 ns. This is employed by the neuromorphic simulation software flow, which defines the performance level (PL) of the PE based on the actual workload within each simulation cycle. A test chip in 28 nm SLP CMOS technology has been implemented. It includes 4 PEs which can be scaled from 0.7 V to 1.0 V with frequencies from 125 MHz to 500 MHz at three distinct PLs. By measurement of three neuromorphic benchmarks it is shown that the total PE power consumption can be reduced by 75%, with 80% baseline power reduction and a 50% reduction of energy per neuron and synapse computation, all while maintaining temporary peak system performance to achieve biological real-time operation of the system. A numerical model of this power management model is derived which allows DVFS architecture exploration for neuromorphics. The proposed technique is to be used for the second generation SpiNNaker neuromorphic many core system.
Efficient Reward-Based Structural Plasticity on a SpiNNaker 2 Prototype
Mar 20, 2019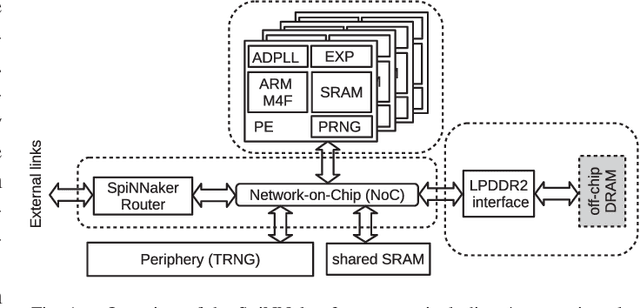
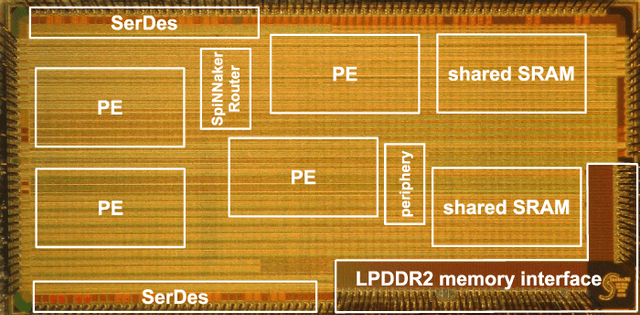
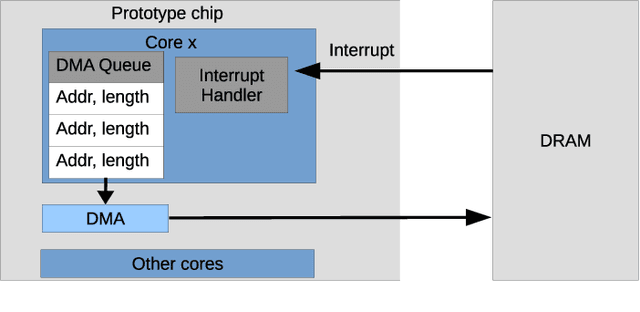
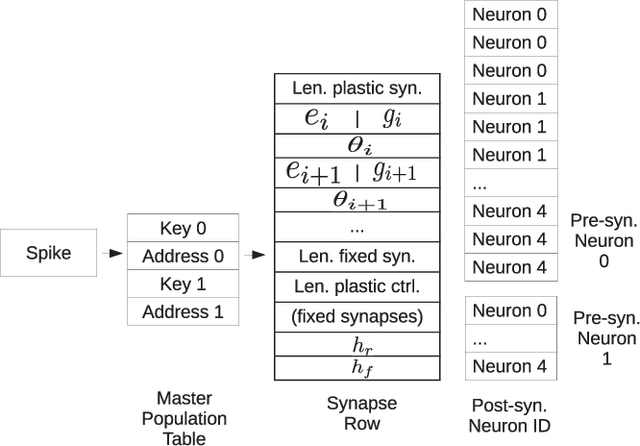
Advances in neuroscience uncover the mechanisms employed by the brain to efficiently solve complex learning tasks with very limited resources. However, the efficiency is often lost when one tries to port these findings to a silicon substrate, since brain-inspired algorithms often make extensive use of complex functions such as random number generators, that are expensive to compute on standard general purpose hardware. The prototype chip of the 2nd generation SpiNNaker system is designed to overcome this problem. Low-power ARM processors equipped with a random number generator and an exponential function accelerator enable the efficient execution of brain-inspired algorithms. We implement the recently introduced reward-based synaptic sampling model that employs structural plasticity to learn a function or task. The numerical simulation of the model requires to update the synapse variables in each time step including an explorative random term. To the best of our knowledge, this is the most complex synapse model implemented so far on the SpiNNaker system. By making efficient use of the hardware accelerators and numerical optimizations the computation time of one plasticity update is reduced by a factor of 2. This, combined with fitting the model into to the local SRAM, leads to 62% energy reduction compared to the case without accelerators and the use of external DRAM. The model implementation is integrated into the SpiNNaker software framework allowing for scalability onto larger systems. The hardware-software system presented in this work paves the way for power-efficient mobile and biomedical applications with biologically plausible brain-inspired algorithms.