 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Symbolic Algebras for the Abstraction and Reasoning Corpus
Nov 11, 2025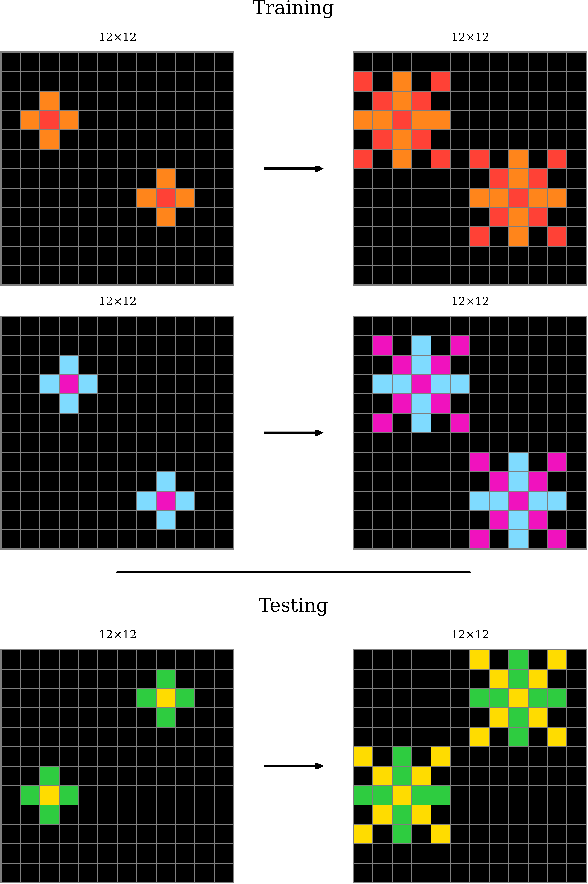
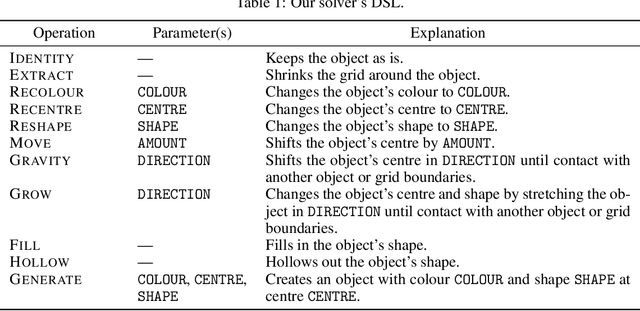
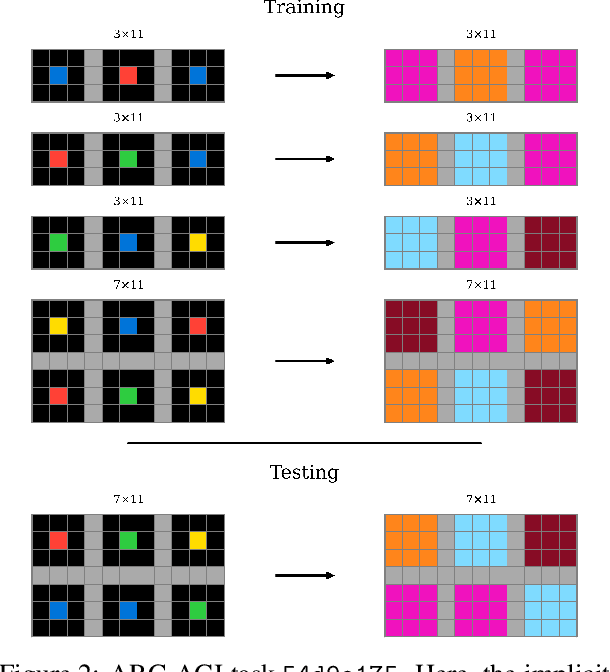

The Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI) is a generative, few-shot fluid intelligence benchmark. Although humans effortlessly solve ARC-AGI, it remains extremely difficult for even the most advanced artificial intelligence systems. Inspired by methods for modelling human intelligence spanning neuroscience to psychology, we propose a cognitively plausible ARC-AGI solver. Our solver integrates System 1 intuitions with System 2 reasoning in an efficient and interpretable process using neurosymbolic methods based on Vector Symbolic Algebras (VSAs). Our solver works by object-centric program synthesis, leveraging VSAs to represent abstract objects, guide solution search, and enable sample-efficient neural learning. Preliminary results indicate success, with our solver scoring 10.8% on ARC-AGI-1-Train and 3.0% on ARC-AGI-1-Eval. Additionally, our solver performs well on simpler benchmarks, scoring 94.5% on Sort-of-ARC and 83.1% on 1D-ARC -- the latter outperforming GPT-4 at a tiny fraction of the computational cost. Importantly, our approach is unique; we believe we are the first to apply VSAs to ARC-AGI and have developed the most cognitively plausible ARC-AGI solver yet. Our code is available at: https://github.com/ijoffe/ARC-VSA-2025.
Debugging using Orthogonal Gradient Descent
Jun 17, 2022
In this report we consider the following problem: Given a trained model that is partially faulty, can we correct its behaviour without having to train the model from scratch? In other words, can we ``debug" neural networks similar to how we address bugs in our mathematical models and standard computer code. We base our approach on the hypothesis that debugging can be treated as a two-task continual learning problem. In particular, we employ a modified version of a continual learning algorithm called Orthogonal Gradient Descent (OGD) to demonstrate, via two simple experiments on the MNIST dataset, that we can in-fact \textit{unlearn} the undesirable behaviour while retaining the general performance of the model, and we can additionally \textit{relearn} the appropriate behaviour, both without having to train the model from scratch.
Language Modeling using LMUs: 10x Better Data Efficiency or Improved Scaling Compared to Transformers
Oct 05, 2021

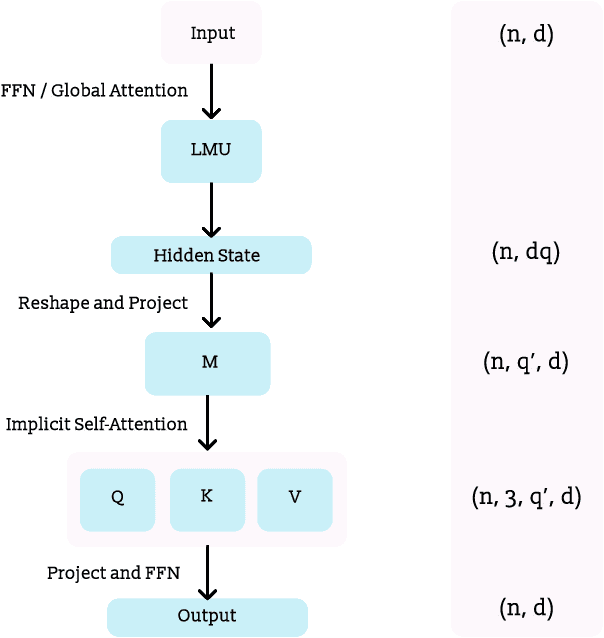

Recent studies have demonstrated that the performance of transformers on the task of language modeling obeys a power-law relationship with model size over six orders of magnitude. While transformers exhibit impressive scaling, their performance hinges on processing large amounts of data, and their computational and memory requirements grow quadratically with sequence length. Motivated by these considerations, we construct a Legendre Memory Unit based model that introduces a general prior for sequence processing and exhibits an $O(n)$ and $O(n \ln n)$ (or better) dependency for memory and computation respectively. Over three orders of magnitude, we show that our new architecture attains the same accuracy as transformers with 10x fewer tokens. We also show that for the same amount of training our model improves the loss over transformers about as much as transformers improve over LSTMs. Additionally, we demonstrate that adding global self-attention complements our architecture and the augmented model improves performance even further.
A Spiking Neural Network for Image Segmentation
Jun 16, 2021



We seek to investigate the scalability of neuromorphic computing for computer vision, with the objective of replicating non-neuromorphic performance on computer vision tasks while reducing power consumption. We convert the deep Artificial Neural Network (ANN) architecture U-Net to a Spiking Neural Network (SNN) architecture using the Nengo framework. Both rate-based and spike-based models are trained and optimized for benchmarking performance and power, using a modified version of the ISBI 2D EM Segmentation dataset consisting of microscope images of cells. We propose a partitioning method to optimize inter-chip communication to improve speed and energy efficiency when deploying multi-chip networks on the Loihi neuromorphic chip. We explore the advantages of regularizing firing rates of Loihi neurons for converting ANN to SNN with minimum accuracy loss and optimized energy consumption. We propose a percentile based regularization loss function to limit the spiking rate of the neuron between a desired range. The SNN is converted directly from the corresponding ANN, and demonstrates similar semantic segmentation as the ANN using the same number of neurons and weights. However, the neuromorphic implementation on the Intel Loihi neuromorphic chip is over 2x more energy-efficient than conventional hardware (CPU, GPU) when running online (one image at a time). These power improvements are achieved without sacrificing the task performance accuracy of the network, and when all weights (Loihi, CPU, and GPU networks) are quantized to 8 bits.
Parallelizing Legendre Memory Unit Training
Feb 22, 2021



Recently, a new recurrent neural network (RNN) named the Legendre Memory Unit (LMU) was proposed and shown to achieve state-of-the-art performance on several benchmark datasets. Here we leverage the linear time-invariant (LTI) memory component of the LMU to construct a simplified variant that can be parallelized during training (and yet executed as an RNN during inference), thus overcoming a well known limitation of training RNNs on GPUs. We show that this reformulation that aids parallelizing, which can be applied generally to any deep network whose recurrent components are linear, makes training up to 200 times faster. Second, to validate its utility, we compare its performance against the original LMU and a variety of published LSTM and transformer networks on seven benchmarks, ranging from psMNIST to sentiment analysis to machine translation. We demonstrate that our models exhibit superior performance on all datasets, often using fewer parameters. For instance, our LMU sets a new state-of-the-art result on psMNIST, and uses half the parameters while outperforming DistilBERT and LSTM models on IMDB sentiment analysis.
Hardware Aware Training for Efficient Keyword Spotting on General Purpose and Specialized Hardware
Sep 23, 2020
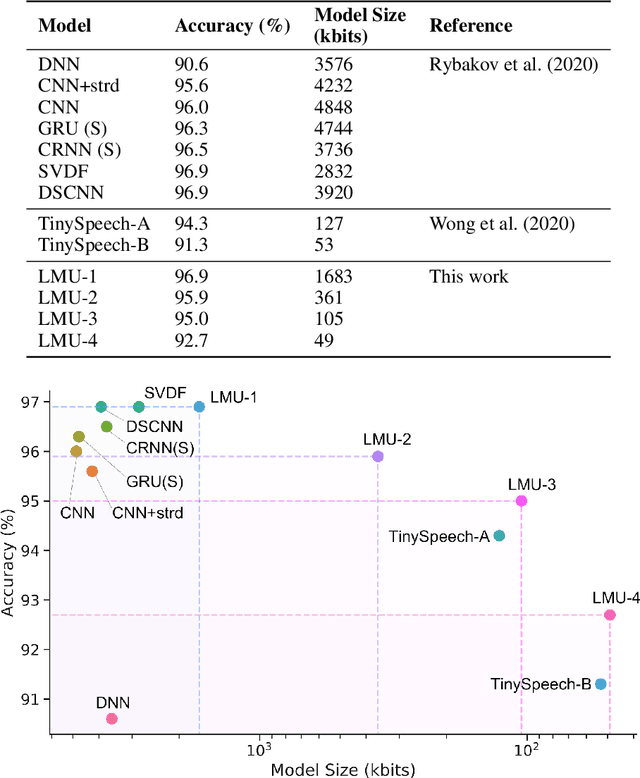

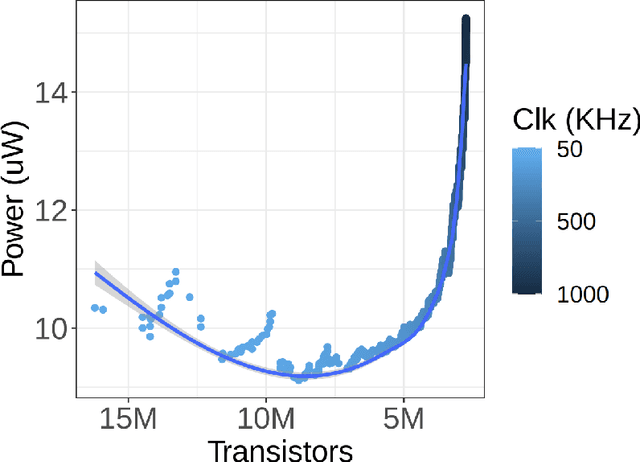
Keyword spotting (KWS) provides a critical user interface for many mobile and edge applications, including phones, wearables, and cars. As KWS systems are typically 'always on', maximizing both accuracy and power efficiency are central to their utility. In this work we use hardware aware training (HAT) to build new KWS neural networks based on the Legendre Memory Unit (LMU) that achieve state-of-the-art (SotA) accuracy and low parameter counts. This allows the neural network to run efficiently on standard hardware (212$\mu$W). We also characterize the power requirements of custom designed accelerator hardware that achieves SotA power efficiency of 8.79$\mu$W, beating general purpose low power hardware (a microcontroller) by 24x and special purpose ASICs by 16x.
Low-Power Low-Latency Keyword Spotting and Adaptive Control with a SpiNNaker 2 Prototype and Comparison with Loihi
Sep 18, 2020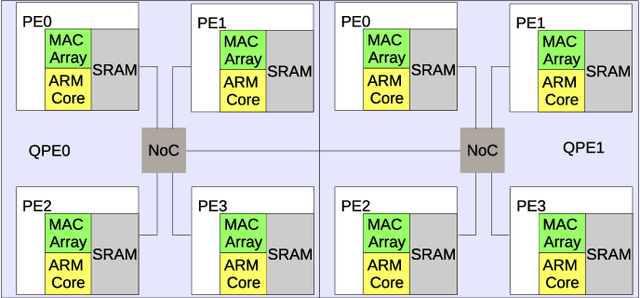
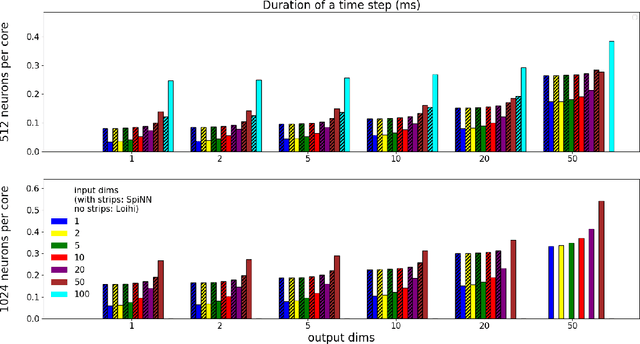
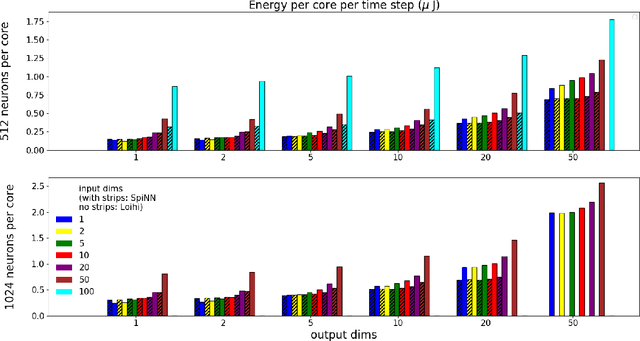
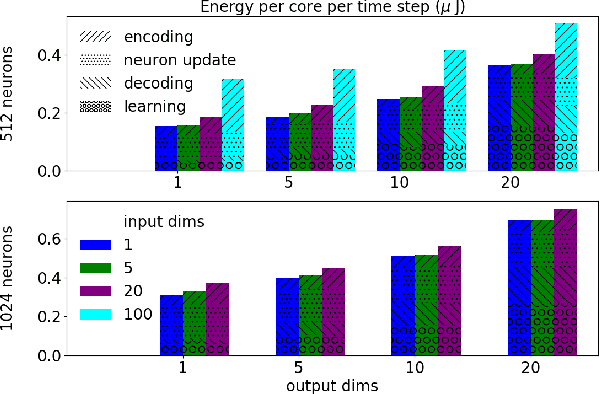
We implemented two neural network based benchmark tasks on a prototype chip of the second-generation SpiNNaker (SpiNNaker 2) neuromorphic system: keyword spotting and adaptive robotic control. Keyword spotting is commonly used in smart speakers to listen for wake words, and adaptive control is used in robotic applications to adapt to unknown dynamics in an online fashion. We highlight the benefit of a multiply accumulate (MAC) array in the SpiNNaker 2 prototype which is ordinarily used in rate-based machine learning networks when employed in a neuromorphic, spiking context. In addition, the same benchmark tasks have been implemented on the Loihi neuromorphic chip, giving a side-by-side comparison regarding power consumption and computation time. While Loihi shows better efficiency when less complicated vector-matrix multiplication is involved, with the MAC array, the SpiNNaker 2 prototype shows better efficiency when high dimensional vector-matrix multiplication is involved.
Nengo and low-power AI hardware for robust, embedded neurorobotics
Aug 29, 2020

In this paper we demonstrate how the Nengo neural modeling and simulation libraries enable users to quickly develop robotic perception and action neural networks for simulation on neuromorphic hardware using familiar tools, such as Keras and Python. We identify four primary challenges in building robust, embedded neurorobotic systems: 1) developing infrastructure for interfacing with the environment and sensors; 2) processing task specific sensory signals; 3) generating robust, explainable control signals; and 4) compiling neural networks to run on target hardware. Nengo helps to address these challenges by: 1) providing the NengoInterfaces library, which defines a simple but powerful API for users to interact with simulations and hardware; 2) providing the NengoDL library, which lets users use the Keras and TensorFlow API to develop Nengo models; 3) implementing the Neural Engineering Framework, which provides white-box methods for implementing known functions and circuits; and 4) providing multiple backend libraries, such as NengoLoihi, that enable users to compile the same model to different hardware. We present two examples using Nengo to develop neural networks that run on CPUs, GPUs, and Intel's neuromorphic chip, Loihi, to demonstrate this workflow. The first example is an end-to-end spiking neural network that controls a rover simulated in Mujoco. The network integrates a deep convolutional network that processes visual input from mounted cameras to track a target, and a control system implementing steering and drive functions to guide the rover to the target. The second example augments a force-based operational space controller with neural adaptive control to improve performance during a reaching task using a real-world Kinova Jaco2 robotic arm. Code and details are provided with the intent of enabling other researchers to build their own neurorobotic systems.
A Spike in Performance: Training Hybrid-Spiking Neural Networks with Quantized Activation Functions
Feb 10, 2020



The machine learning community has become increasingly interested in the energy efficiency of neural networks. The Spiking Neural Network (SNN) is a promising approach to energy-efficient computing, since its activation levels are quantized into temporally sparse, one-bit values (i.e., "spike" events), which additionally converts the sum over weight-activity products into a simple addition of weights (one weight for each spike). However, the goal of maintaining state-of-the-art (SotA) accuracy when converting a non-spiking network into an SNN has remained an elusive challenge, primarily due to spikes having only a single bit of precision. Adopting tools from signal processing, we cast neural activation functions as quantizers with temporally-diffused error, and then train networks while smoothly interpolating between the non-spiking and spiking regimes. We apply this technique to the Legendre Memory Unit (LMU) to obtain the first known example of a hybrid SNN outperforming SotA recurrent architectures---including the LSTM, GRU, and NRU---in accuracy, while reducing activities to at most 3.74 bits on average with 1.26 significant bits multiplying each weight. We discuss how these methods can significantly improve the energy efficiency of neural networks.
Passive nonlinear dendritic interactions as a general computational resource in functional spiking neural networks
Apr 26, 2019



Nonlinear interactions in the dendritic tree play a key role in neural computation. Nevertheless, modeling frameworks aimed at the construction of large-scale, functional spiking neural networks tend to assume linear, current-based superposition of post-synaptic currents. We extend the theory underlying the Neural Engineering Framework to systematically exploit nonlinear interactions between the local membrane potential and conductance-based synaptic channels as a computational resource. In particular, we demonstrate that even a single passive distal dendritic compartment with AMPA and GABA-A synapses connected to a leaky integrate-and-fire neuron supports the computation of a wide variety of multivariate, bandlimited functions, including the Euclidean norm, controlled shunting, and non-negative multiplication. Our results demonstrate that, for certain operations, the accuracy of dendritic computation is on a par with or even surpasses the accuracy of an additional layer of neurons in the network. These findings allow modelers to construct large-scale models of neurobiological systems that closer approximate network topologies and computational resources available in biology. Our results may inform neuromorphic hardware design and could lead to a better utilization of resources on existing neuromorphic hardware platforms.