 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Modeling using LMUs: 10x Better Data Efficiency or Improved Scaling Compared to Transformers
Oct 05, 2021

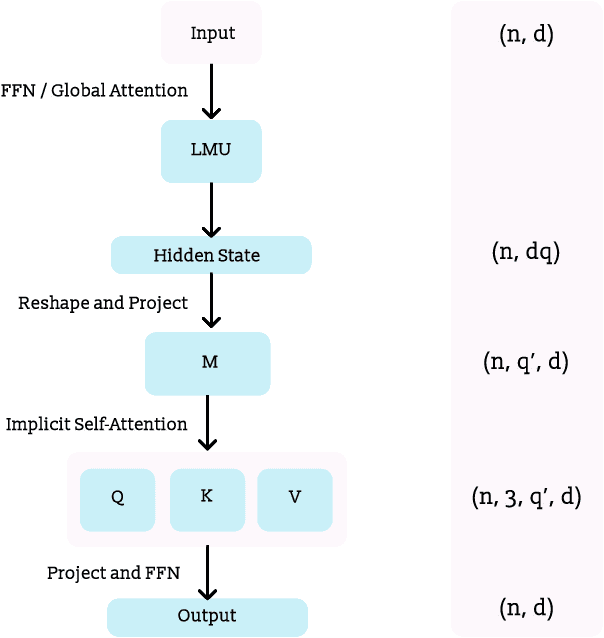

Recent studies have demonstrated that the performance of transformers on the task of language modeling obeys a power-law relationship with model size over six orders of magnitude. While transformers exhibit impressive scaling, their performance hinges on processing large amounts of data, and their computational and memory requirements grow quadratically with sequence length. Motivated by these considerations, we construct a Legendre Memory Unit based model that introduces a general prior for sequence processing and exhibits an $O(n)$ and $O(n \ln n)$ (or better) dependency for memory and computation respectively. Over three orders of magnitude, we show that our new architecture attains the same accuracy as transformers with 10x fewer tokens. We also show that for the same amount of training our model improves the loss over transformers about as much as transformers improve over LSTMs. Additionally, we demonstrate that adding global self-attention complements our architecture and the augmented model improves performance even further.
A Spiking Neural Network for Image Segmentation
Jun 16, 2021



We seek to investigate the scalability of neuromorphic computing for computer vision, with the objective of replicating non-neuromorphic performance on computer vision tasks while reducing power consumption. We convert the deep Artificial Neural Network (ANN) architecture U-Net to a Spiking Neural Network (SNN) architecture using the Nengo framework. Both rate-based and spike-based models are trained and optimized for benchmarking performance and power, using a modified version of the ISBI 2D EM Segmentation dataset consisting of microscope images of cells. We propose a partitioning method to optimize inter-chip communication to improve speed and energy efficiency when deploying multi-chip networks on the Loihi neuromorphic chip. We explore the advantages of regularizing firing rates of Loihi neurons for converting ANN to SNN with minimum accuracy loss and optimized energy consumption. We propose a percentile based regularization loss function to limit the spiking rate of the neuron between a desired range. The SNN is converted directly from the corresponding ANN, and demonstrates similar semantic segmentation as the ANN using the same number of neurons and weights. However, the neuromorphic implementation on the Intel Loihi neuromorphic chip is over 2x more energy-efficient than conventional hardware (CPU, GPU) when running online (one image at a time). These power improvements are achieved without sacrificing the task performance accuracy of the network, and when all weights (Loihi, CPU, and GPU networks) are quantized to 8 bits.
Benchmarking Keyword Spotting Efficiency on Neuromorphic Hardware
Dec 04, 2018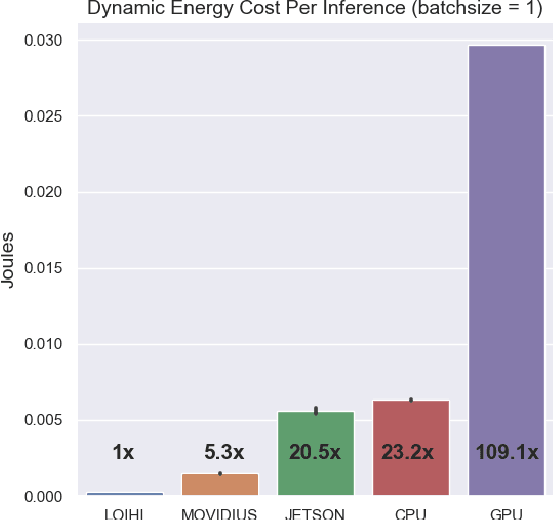
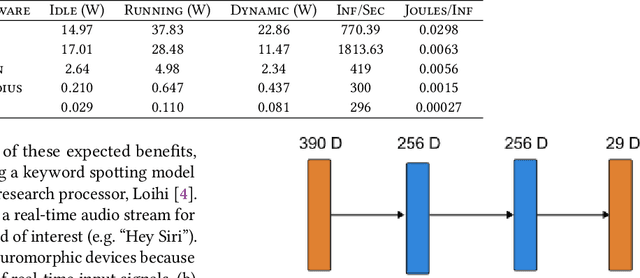

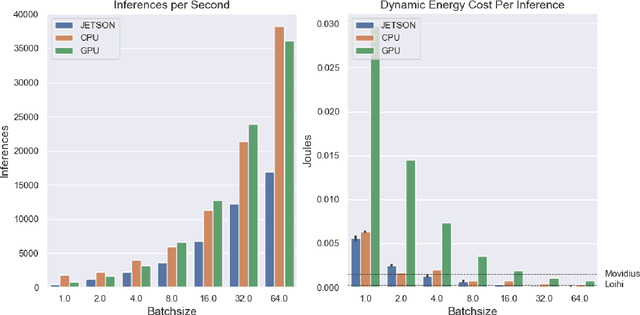
Using Intel's Loihi neuromorphic research chip and ABR's Nengo Deep Learning toolkit, we analyze the inference speed, dynamic power consumption, and energy cost per inference of a two-layer neural network keyword spotter trained to recognize a single phrase. We perform comparative analyses of this keyword spotter running on more conventional hardware devices including a CPU, a GPU, Nvidia's Jetson TX1, and the Movidius Neural Compute Stick. Our results indicate that for this inference application, Loihi outperforms all of these alternatives on an energy cost per inference basis while maintaining near-equivalent inference accuracy. Furthermore, an analysis of tradeoffs between network size, inference speed, and energy cost indicates that Loihi's comparative advantage over other low-power computing devices improves for larger networks.
Training Spiking Deep Networks for Neuromorphic Hardware
Nov 16, 2016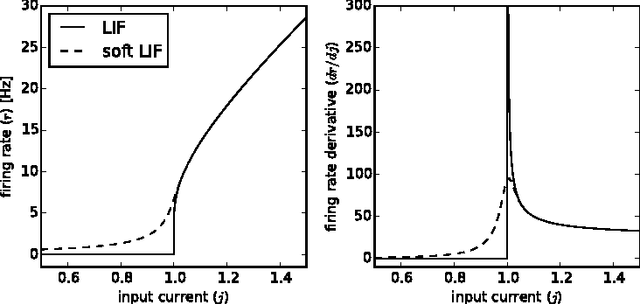
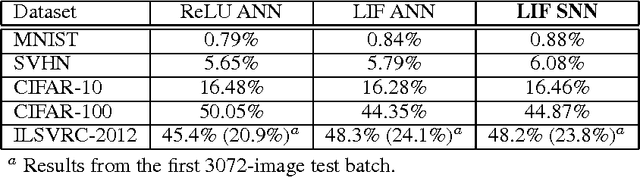

We describe a method to train spiking deep networks that can be run using leaky integrate-and-fire (LIF) neurons, achieving state-of-the-art results for spiking LIF networks on five datasets, including the large ImageNet ILSVRC-2012 benchmark. Our method for transforming deep artificial neural networks into spiking networks is scalable and works with a wide range of neural nonlinearities. We achieve these results by softening the neural response function, such that its derivative remains bounded, and by training the network with noise to provide robustness against the variability introduced by spikes. Our analysis shows that implementations of these networks on neuromorphic hardware will be many times more power-efficient than the equivalent non-spiking networks on traditional hardware.
Spiking Deep Networks with LIF Neurons
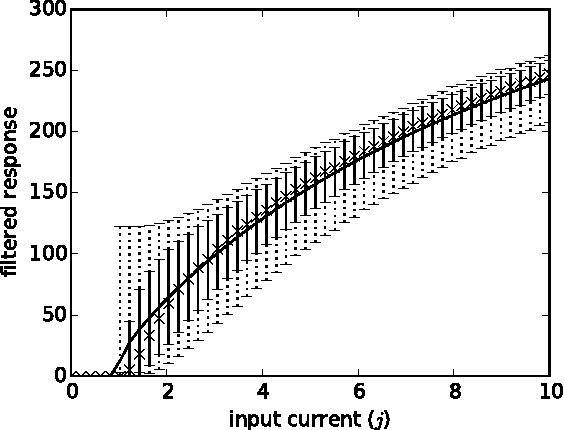
Oct 29, 2015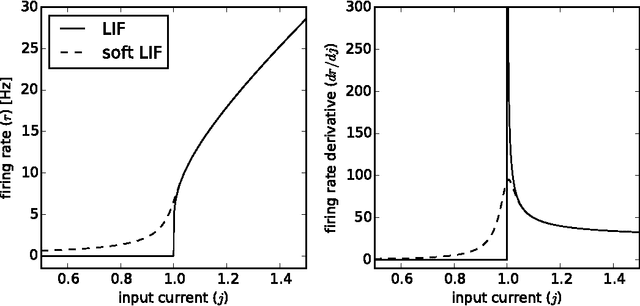



We train spiking deep networks using leaky integrate-and-fire (LIF) neurons, and achieve state-of-the-art results for spiking networks on the CIFAR-10 and MNIST datasets. This demonstrates that biologically-plausible spiking LIF neurons can be integrated into deep networks can perform as well as other spiking models (e.g. integrate-and-fire). We achieved this result by softening the LIF response function, such that its derivative remains bounded, and by training the network with noise to provide robustness against the variability introduced by spikes. Our method is general and could be applied to other neuron types, including those used on modern neuromorphic hardware. Our work brings more biological realism into modern image classification models, with the hope that these models can inform how the brain performs this difficult task. It also provides new methods for training deep networks to run on neuromorphic hardware, with the aim of fast, power-efficient image classification for robotics applications.