 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Modeling using LMUs: 10x Better Data Efficiency or Improved Scaling Compared to Transformers
Oct 05, 2021

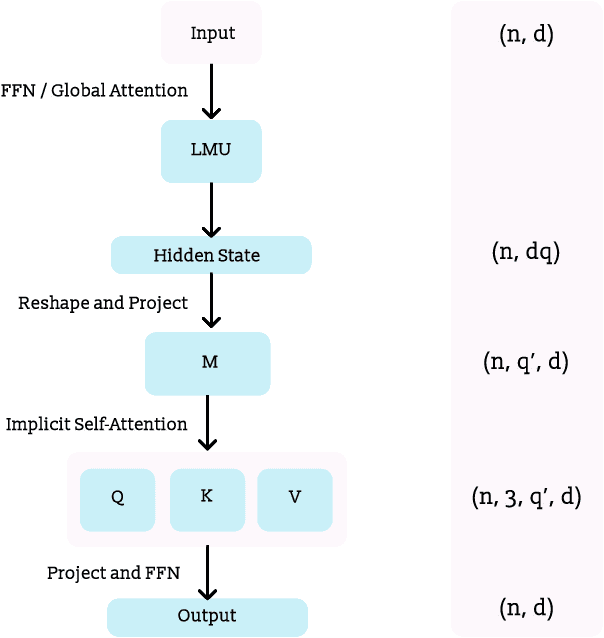

Recent studies have demonstrated that the performance of transformers on the task of language modeling obeys a power-law relationship with model size over six orders of magnitude. While transformers exhibit impressive scaling, their performance hinges on processing large amounts of data, and their computational and memory requirements grow quadratically with sequence length. Motivated by these considerations, we construct a Legendre Memory Unit based model that introduces a general prior for sequence processing and exhibits an $O(n)$ and $O(n \ln n)$ (or better) dependency for memory and computation respectively. Over three orders of magnitude, we show that our new architecture attains the same accuracy as transformers with 10x fewer tokens. We also show that for the same amount of training our model improves the loss over transformers about as much as transformers improve over LSTMs. Additionally, we demonstrate that adding global self-attention complements our architecture and the augmented model improves performance even further.
Hardware Aware Training for Efficient Keyword Spotting on General Purpose and Specialized Hardware
Sep 23, 2020
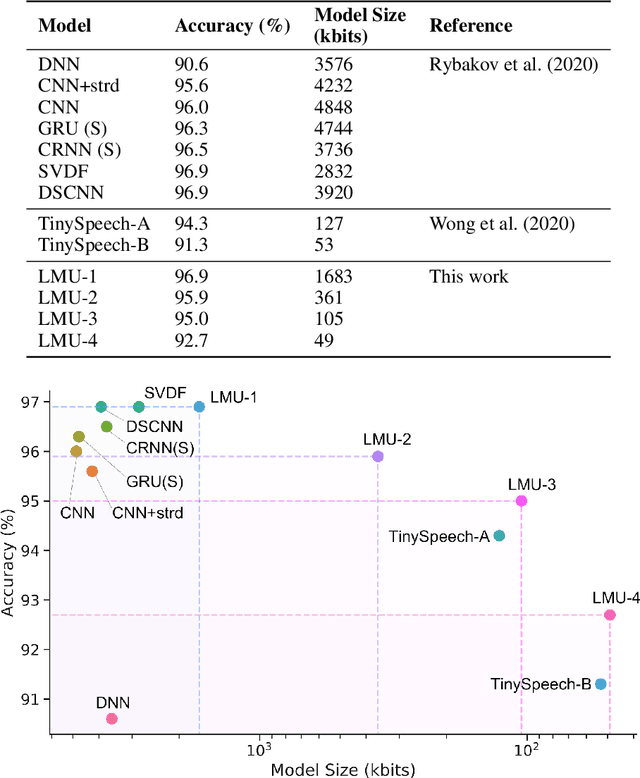

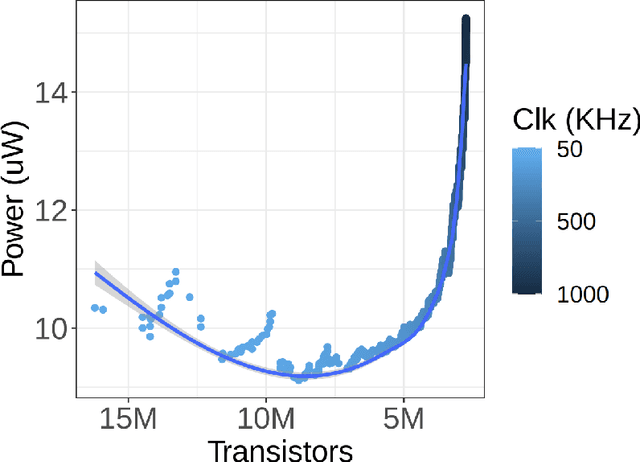
Keyword spotting (KWS) provides a critical user interface for many mobile and edge applications, including phones, wearables, and cars. As KWS systems are typically 'always on', maximizing both accuracy and power efficiency are central to their utility. In this work we use hardware aware training (HAT) to build new KWS neural networks based on the Legendre Memory Unit (LMU) that achieve state-of-the-art (SotA) accuracy and low parameter counts. This allows the neural network to run efficiently on standard hardware (212$\mu$W). We also characterize the power requirements of custom designed accelerator hardware that achieves SotA power efficiency of 8.79$\mu$W, beating general purpose low power hardware (a microcontroller) by 24x and special purpose ASICs by 16x.
FPGA based hybrid architecture for parallelizing RRT
Jul 19, 2016



Field Programmable Gate Arrays(FPGA) exceed the computing power of software based implementations by breaking the paradigm of sequential execution and accomplishing more per clock cycle by enabling hardware level parallelization at an architectural level. Introducing parallel architectures for a computationally intensive algorithm like Rapidly Exploring Random Trees(RRT) will result in an exploration that is fast, dense and uniform. Through a cost function delineated in later sections, FPGA based combinatorial architecture delivers superlative speed-up but consumes very high power while hierarchical architecture delivers relatively lower speed-up with acceptable power consumption levels. To combine the qualities of both, a hybrid architecture, that encompasses both combinatorial and hierarchical architecture, is designed. To determine the number of RRT nodes to be allotted to the combinatorial and hierarchical blocks of the hybrid architecture, a cost function, comprised of fundamentally inversely related speed-up and power parameters, is formulated. This maximization of cost function, with its associated constraints,is then mathematically solved using a modified branch and bound, that leads to optimal allocation of RRT modules to both blocks. It is observed that this hybrid architecture delivers the highest performance-per-watt out of the three architectures for differential, quad-copter and fixed wing kinematics.