 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware Aware Training for Efficient Keyword Spotting on General Purpose and Specialized Hardware
Sep 23, 2020
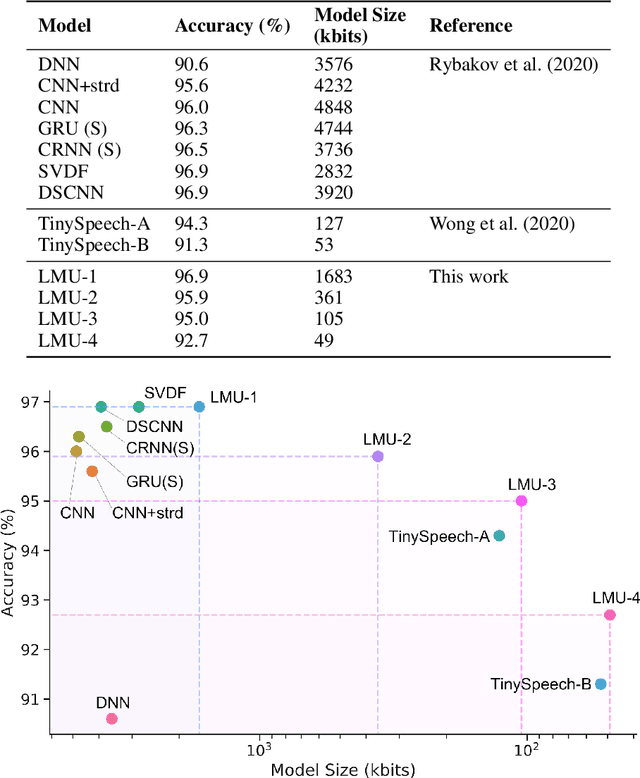

Keyword spotting (KWS) provides a critical user interface for many mobile and edge applications, including phones, wearables, and cars. As KWS systems are typically 'always on', maximizing both accuracy and power efficiency are central to their utility. In this work we use hardware aware training (HAT) to build new KWS neural networks based on the Legendre Memory Unit (LMU) that achieve state-of-the-art (SotA) accuracy and low parameter counts. This allows the neural network to run efficiently on standard hardware (212$\mu$W). We also characterize the power requirements of custom designed accelerator hardware that achieves SotA power efficiency of 8.79$\mu$W, beating general purpose low power hardware (a microcontroller) by 24x and special purpose ASICs by 16x.
A short letter on the dot product between rotated Fourier transforms
Jul 24, 2020
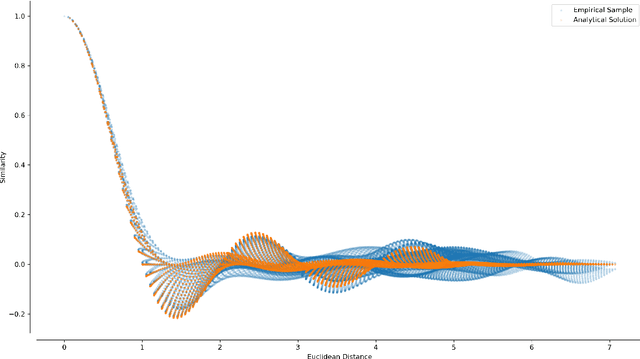

Spatial Semantic Pointers (SSPs) have recently emerged as a powerful tool for representing and transforming continuous space, with numerous applications to cognitive modelling and deep learning. Fundamental to SSPs is the notion of "similarity" between vectors representing different points in $n$-dimensional space -- typically the dot product or cosine similarity between vectors with rotated unit-length complex coefficients in the Fourier domain. The similarity measure has previously been conjectured to be a Gaussian function of Euclidean distance. Contrary to this conjecture, we derive a simple trigonometric formula relating spatial displacement to similarity, and prove that, in the case where the Fourier coefficients are uniform i.i.d., the expected similarity is a product of normalized sinc functions: $\prod_{k=1}^{n} \operatorname{sinc} \left( a_k \right)$, where $\mathbf{a} \in \mathbb{R}^n$ is the spatial displacement between the two $n$-dimensional points. This establishes a direct link between space and the similarity of SSPs, which in turn helps bolster a useful mathematical framework for architecting neural networks that manipulate spatial structures.
A Spike in Performance: Training Hybrid-Spiking Neural Networks with Quantized Activation Functions
Feb 10, 2020



The machine learning community has become increasingly interested in the energy efficiency of neural networks. The Spiking Neural Network (SNN) is a promising approach to energy-efficient computing, since its activation levels are quantized into temporally sparse, one-bit values (i.e., "spike" events), which additionally converts the sum over weight-activity products into a simple addition of weights (one weight for each spike). However, the goal of maintaining state-of-the-art (SotA) accuracy when converting a non-spiking network into an SNN has remained an elusive challenge, primarily due to spikes having only a single bit of precision. Adopting tools from signal processing, we cast neural activation functions as quantizers with temporally-diffused error, and then train networks while smoothly interpolating between the non-spiking and spiking regimes. We apply this technique to the Legendre Memory Unit (LMU) to obtain the first known example of a hybrid SNN outperforming SotA recurrent architectures---including the LSTM, GRU, and NRU---in accuracy, while reducing activities to at most 3.74 bits on average with 1.26 significant bits multiplying each weight. We discuss how these methods can significantly improve the energy efficiency of neural networks.
Point Neurons with Conductance-Based Synapses in the Neural Engineering Framework
Oct 20, 2017



The mathematical model underlying the Neural Engineering Framework (NEF) expresses neuronal input as a linear combination of synaptic currents. However, in biology, synapses are not perfect current sources and are thus nonlinear. Detailed synapse models are based on channel conductances instead of currents, which require independent handling of excitatory and inhibitory synapses. This, in particular, significantly affects the influence of inhibitory signals on the neuronal dynamics. In this technical report we first summarize the relevant portions of the NEF and conductance-based synapse models. We then discuss a na\"ive translation between populations of LIF neurons with current- and conductance-based synapses based on an estimation of an average membrane potential. Experiments show that this simple approach works relatively well for feed-forward communication channels, yet performance degrades for NEF networks describing more complex dynamics, such as integration.
Methods for applying the Neural Engineering Framework to neuromorphic hardware
Aug 27, 2017We review our current software tools and theoretical methods for applying the Neural Engineering Framework to state-of-the-art neuromorphic hardware. These methods can be used to implement linear and nonlinear dynamical systems that exploit axonal transmission time-delays, and to fully account for nonideal mixed-analog-digital synapses that exhibit higher-order dynamics with heterogeneous time-constants. This summarizes earlier versions of these methods that have been discussed in a more biological context (Voelker & Eliasmith, 2017) or regarding a specific neuromorphic architecture (Voelker et al., 2017).