 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Deployment of Spiking Neural Networks on SpiNNaker2 for DVS Gesture Recognition Using Neuromorphic Intermediate Representation
Apr 09, 2025Spiking Neural Networks (SNNs) are highly energy-efficient during inference, making them particularly suitable for deployment on neuromorphic hardware. Their ability to process event-driven inputs, such as data from dynamic vision sensors (DVS), further enhances their applicability to edge computing tasks. However, the resource constraints of edge hardware necessitate techniques like weight quantization, which reduce the memory footprint of SNNs while preserving accuracy. Despite its importance, existing quantization methods typically focus on synaptic weights quantization without taking account of other critical parameters, such as scaling neuron firing thresholds. To address this limitation, we present the first benchmark for the DVS gesture recognition task using SNNs optimized for the many-core neuromorphic chip SpiNNaker2. Our study evaluates two quantization pipelines for fixed-point computations. The first approach employs post training quantization (PTQ) with percentile-based threshold scaling, while the second uses quantization aware training (QAT) with adaptive threshold scaling. Both methods achieve accurate 8-bit on-chip inference, closely approximating 32-bit floating-point performance. Additionally, our baseline SNNs perform competitively against previously reported results without specialized techniques. These models are deployed on SpiNNaker2 using the neuromorphic intermediate representation (NIR). Ultimately, we achieve 94.13% classification accuracy on-chip, demonstrating the SpiNNaker2's potential for efficient, low-energy neuromorphic computing.
* 8 pages, 3 figures, 8 tables, Conference-2025 Neuro Inspired Computational Elements (NICE)
68-Channel Highly-Integrated Neural Signal Processing PSoC with On-Chip Feature Extraction, Compression, and Hardware Accelerators for Neuroprosthetics in 22nm FDSOI
Jul 12, 2024



Multi-channel electrophysiology systems for recording of neuronal activity face significant data throughput limitations, hampering real-time, data-informed experiments. These limitations impact both experimental neurobiology research and next-generation neuroprosthetics. We present a novel solution that leverages the high integration density of 22nm FDSOI CMOS technology to address these challenges. The proposed highly integrated programmable System-on-Chip comprises 68-channel 0.41 \textmu W/Ch recording frontends, spike detectors, 16-channel 0.87-4.39 \textmu W/Ch action potential and 8-channel 0.32 \textmu W/Ch local field potential codecs, as well as a MAC-assisted power-efficient processor operating at 25 MHz (5.19 \textmu W/MHz). The system supports on-chip training processes for compression, training and inference for neural spike sorting. The spike sorting achieves an average accuracy of 91.48% or 94.12% depending on the utilized features. The proposed PSoC is optimized for reduced area (9 mm2) and power. On-chip processing and compression capabilities free up the data bottlenecks in data transmission (up to 91% space saving ratio), and moreover enable a fully autonomous yet flexible processor-driven operation. Combined, these design considerations overcome data-bottlenecks by allowing on-chip feature extraction and subsequent compression.
Deploying Machine Learning Models to Ahead-of-Time Runtime on Edge Using MicroTVM
Apr 14, 2023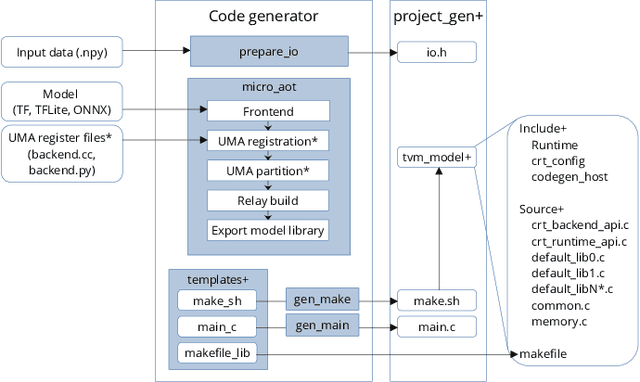

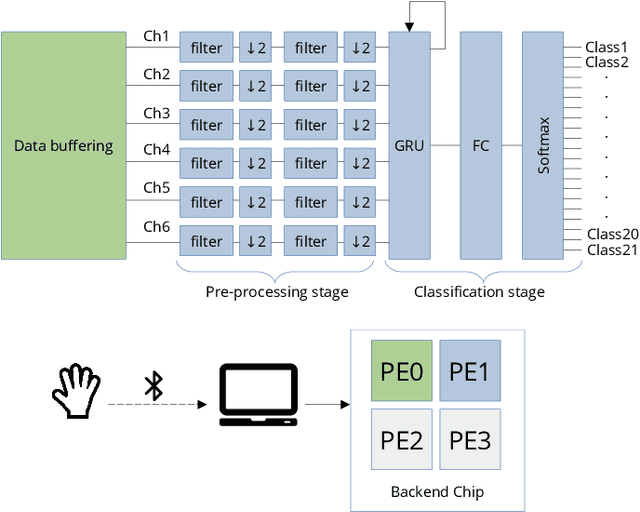
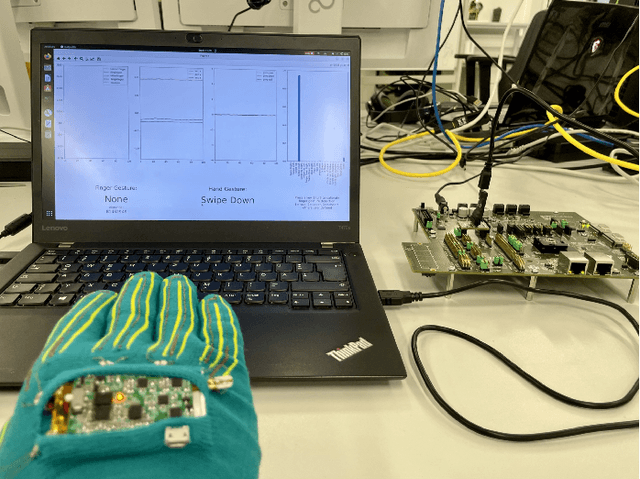
In the past few years, more and more AI applications have been applied to edge devices. However, models trained by data scientists with machine learning frameworks, such as PyTorch or TensorFlow, can not be seamlessly executed on edge. In this paper, we develop an end-to-end code generator parsing a pre-trained model to C source libraries for the backend using MicroTVM, a machine learning compiler framework extension addressing inference on bare metal devices. An analysis shows that specific compute-intensive operators can be easily offloaded to the dedicated accelerator with a Universal Modular Accelerator (UMA) interface, while others are processed in the CPU cores. By using the automatically generated ahead-of-time C runtime, we conduct a hand gesture recognition experiment on an ARM Cortex M4F core.
Low-Power Low-Latency Keyword Spotting and Adaptive Control with a SpiNNaker 2 Prototype and Comparison with Loihi
Sep 18, 2020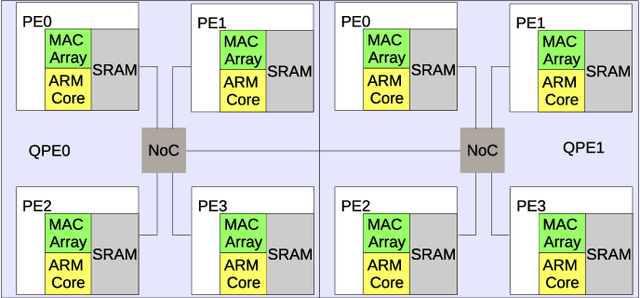
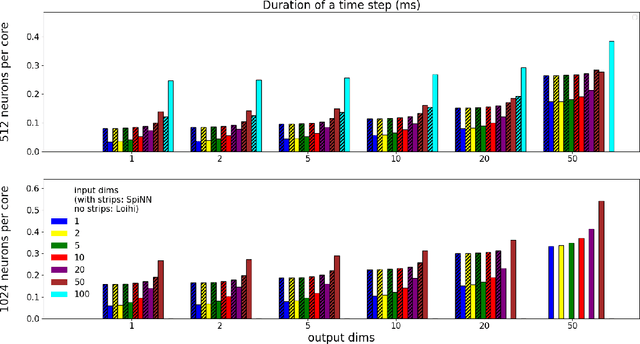
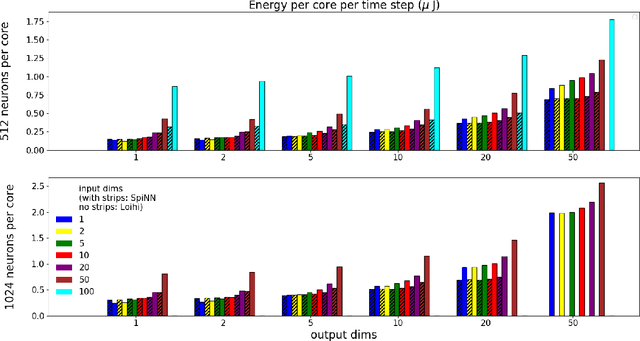
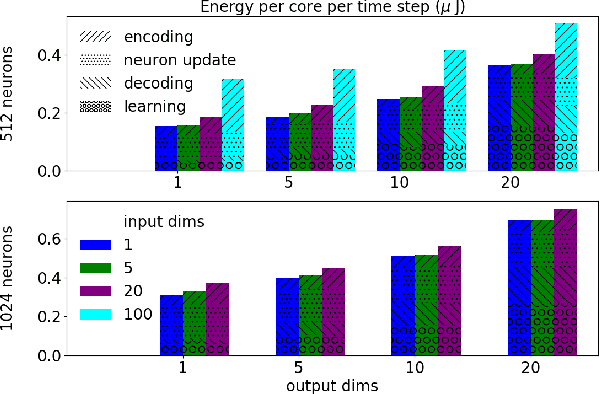
We implemented two neural network based benchmark tasks on a prototype chip of the second-generation SpiNNaker (SpiNNaker 2) neuromorphic system: keyword spotting and adaptive robotic control. Keyword spotting is commonly used in smart speakers to listen for wake words, and adaptive control is used in robotic applications to adapt to unknown dynamics in an online fashion. We highlight the benefit of a multiply accumulate (MAC) array in the SpiNNaker 2 prototype which is ordinarily used in rate-based machine learning networks when employed in a neuromorphic, spiking context. In addition, the same benchmark tasks have been implemented on the Loihi neuromorphic chip, giving a side-by-side comparison regarding power consumption and computation time. While Loihi shows better efficiency when less complicated vector-matrix multiplication is involved, with the MAC array, the SpiNNaker 2 prototype shows better efficiency when high dimensional vector-matrix multiplication is involved.
The Operating System of the Neuromorphic BrainScaleS-1 System
Mar 30, 2020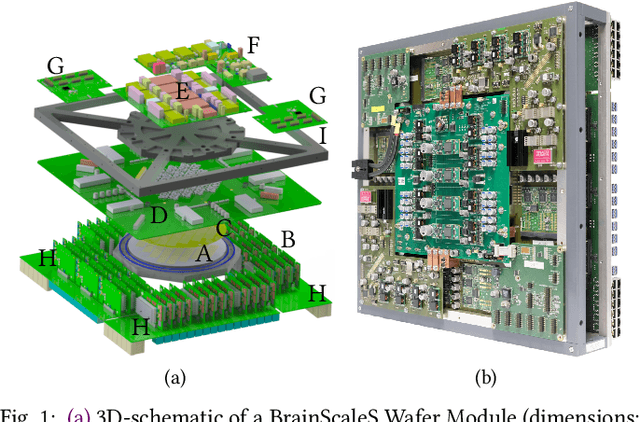
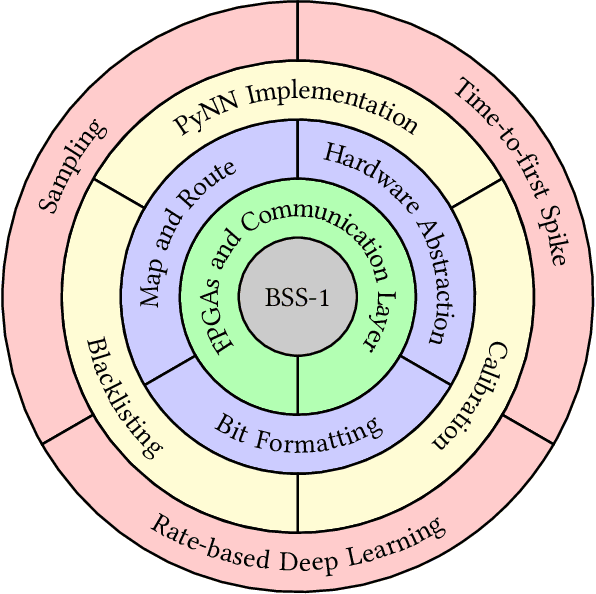
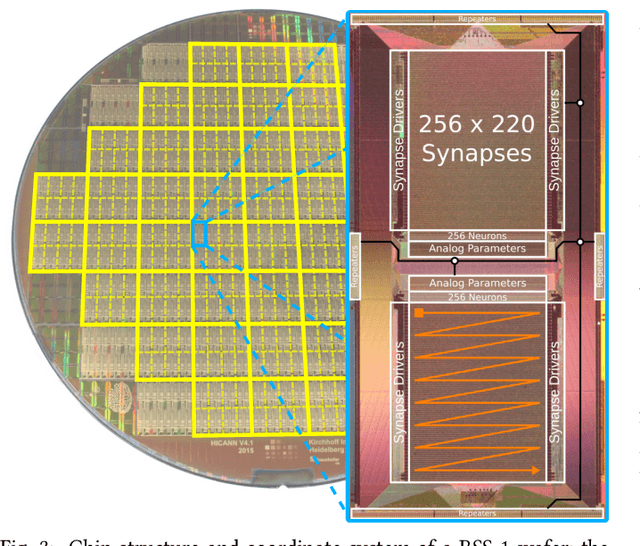
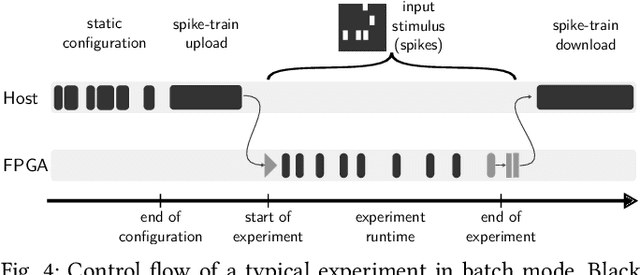
BrainScaleS-1 is a wafer-scale mixed-signal accelerated neuromorphic system targeted for research in the fields of computational neuroscience and beyond-von-Neumann computing. The BrainScaleS Operating System (BrainScaleS OS) is a software stack giving users the possibility to emulate networks described in the high-level network description language PyNN with minimal knowledge of the system. At the same time, expert usage is facilitated by allowing to hook into the system at any depth of the stack. We present operation and development methodologies implemented for the BrainScaleS-1 neuromorphic architecture and walk through the individual components of BrainScaleS OS constituting the software stack for BrainScaleS-1 platform operation.
Dynamic Power Management for Neuromorphic Many-Core Systems
Mar 21, 2019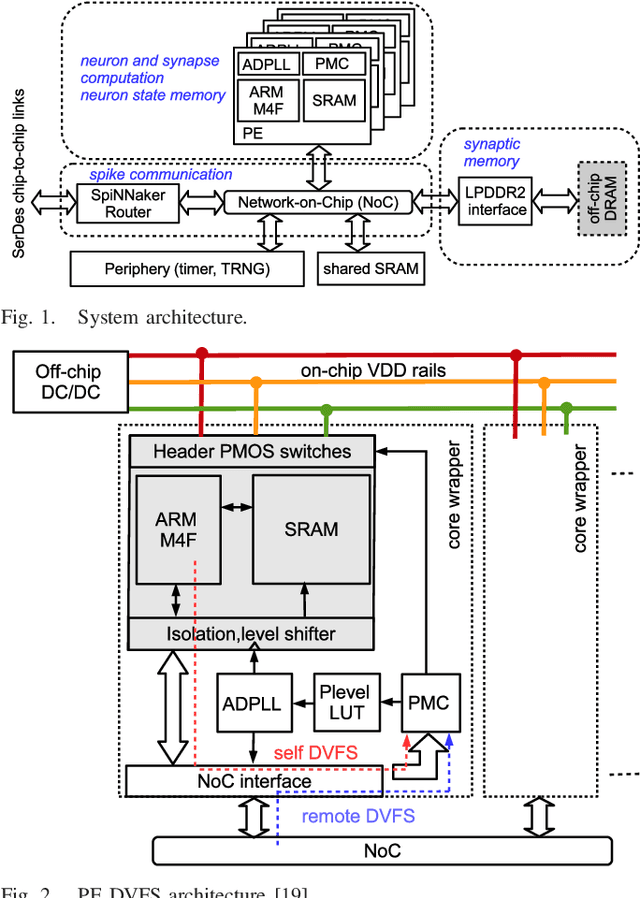

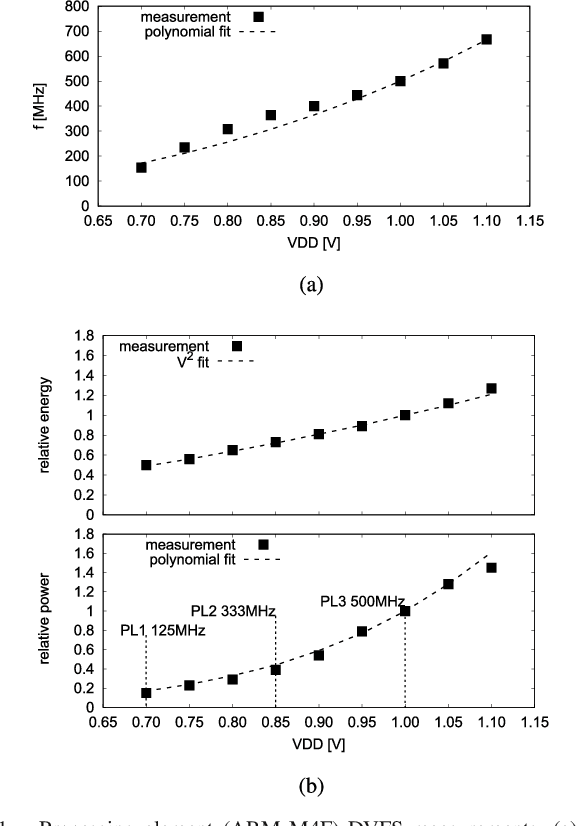
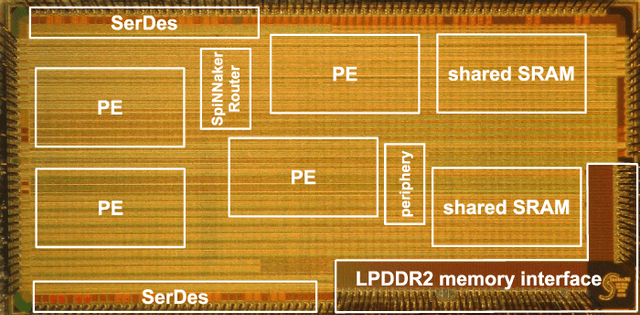
This work presents a dynamic power management architecture for neuromorphic many core systems such as SpiNNaker. A fast dynamic voltage and frequency scaling (DVFS) technique is presented which allows the processing elements (PE) to change their supply voltage and clock frequency individually and autonomously within less than 100 ns. This is employed by the neuromorphic simulation software flow, which defines the performance level (PL) of the PE based on the actual workload within each simulation cycle. A test chip in 28 nm SLP CMOS technology has been implemented. It includes 4 PEs which can be scaled from 0.7 V to 1.0 V with frequencies from 125 MHz to 500 MHz at three distinct PLs. By measurement of three neuromorphic benchmarks it is shown that the total PE power consumption can be reduced by 75%, with 80% baseline power reduction and a 50% reduction of energy per neuron and synapse computation, all while maintaining temporary peak system performance to achieve biological real-time operation of the system. A numerical model of this power management model is derived which allows DVFS architecture exploration for neuromorphics. The proposed technique is to be used for the second generation SpiNNaker neuromorphic many core system.
Efficient Reward-Based Structural Plasticity on a SpiNNaker 2 Prototype
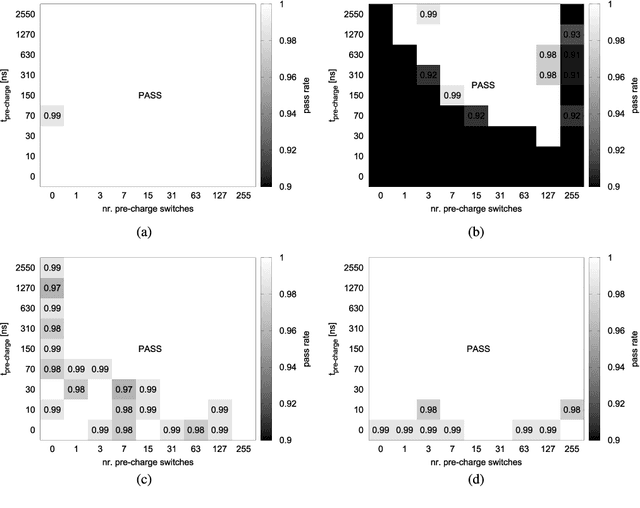
Mar 20, 2019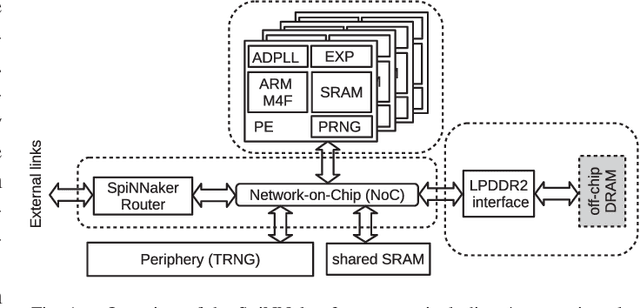
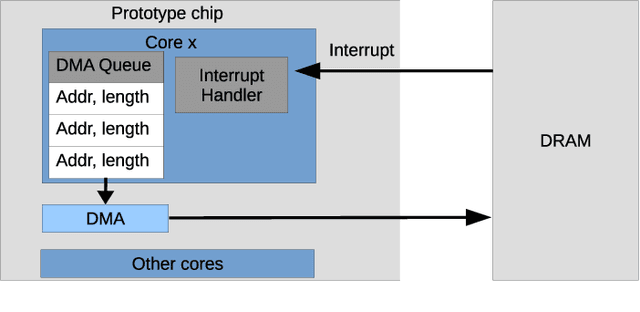
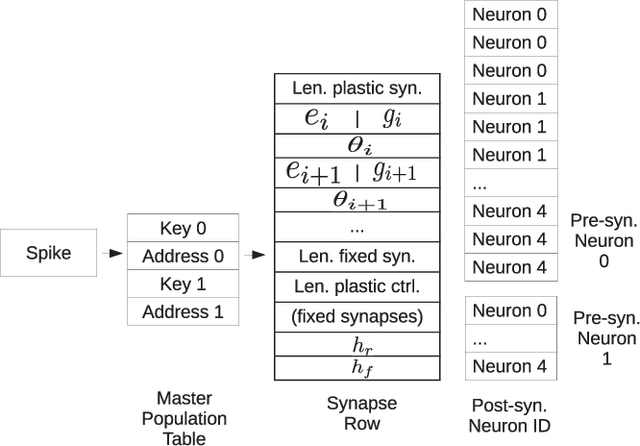
Advances in neuroscience uncover the mechanisms employed by the brain to efficiently solve complex learning tasks with very limited resources. However, the efficiency is often lost when one tries to port these findings to a silicon substrate, since brain-inspired algorithms often make extensive use of complex functions such as random number generators, that are expensive to compute on standard general purpose hardware. The prototype chip of the 2nd generation SpiNNaker system is designed to overcome this problem. Low-power ARM processors equipped with a random number generator and an exponential function accelerator enable the efficient execution of brain-inspired algorithms. We implement the recently introduced reward-based synaptic sampling model that employs structural plasticity to learn a function or task. The numerical simulation of the model requires to update the synapse variables in each time step including an explorative random term. To the best of our knowledge, this is the most complex synapse model implemented so far on the SpiNNaker system. By making efficient use of the hardware accelerators and numerical optimizations the computation time of one plasticity update is reduced by a factor of 2. This, combined with fitting the model into to the local SRAM, leads to 62% energy reduction compared to the case without accelerators and the use of external DRAM. The model implementation is integrated into the SpiNNaker software framework allowing for scalability onto larger systems. The hardware-software system presented in this work paves the way for power-efficient mobile and biomedical applications with biologically plausible brain-inspired algorithms.
Pattern representation and recognition with accelerated analog neuromorphic systems
Jul 03, 2017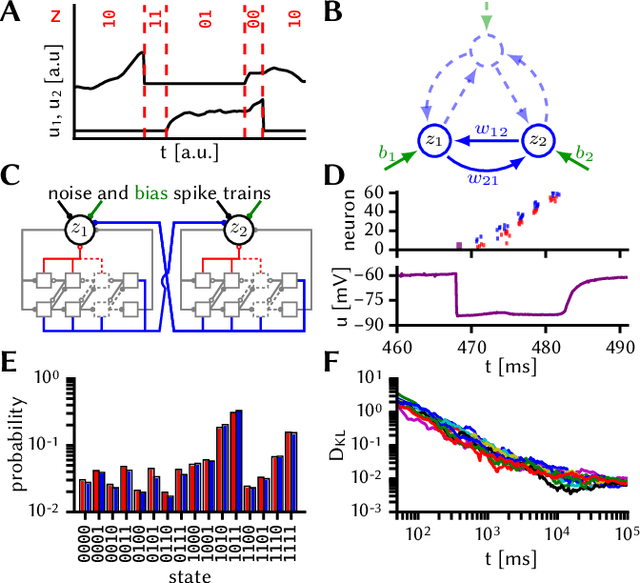

Despite being originally inspired by the central nervous system, artificial neural networks have diverged from their biological archetypes as they have been remodeled to fit particular tasks. In this paper, we review several possibilites to reverse map these architectures to biologically more realistic spiking networks with the aim of emulating them on fast, low-power neuromorphic hardware. Since many of these devices employ analog components, which cannot be perfectly controlled, finding ways to compensate for the resulting effects represents a key challenge. Here, we discuss three different strategies to address this problem: the addition of auxiliary network components for stabilizing activity, the utilization of inherently robust architectures and a training method for hardware-emulated networks that functions without perfect knowledge of the system's dynamics and parameters. For all three scenarios, we corroborate our theoretical considerations with experimental results on accelerated analog neuromorphic platforms.
* accepted at ISCAS 2017
Neuromorphic Hardware In The Loop: Training a Deep Spiking Network on the BrainScaleS Wafer-Scale System
Mar 06, 2017
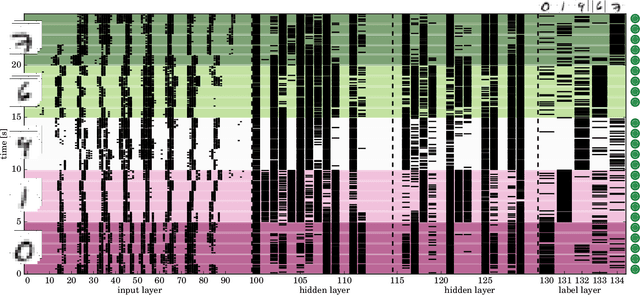
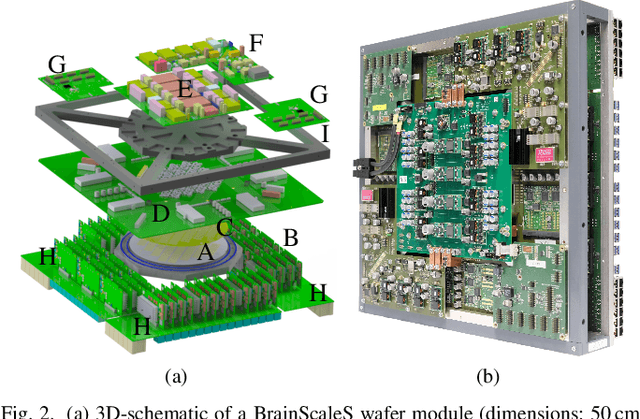
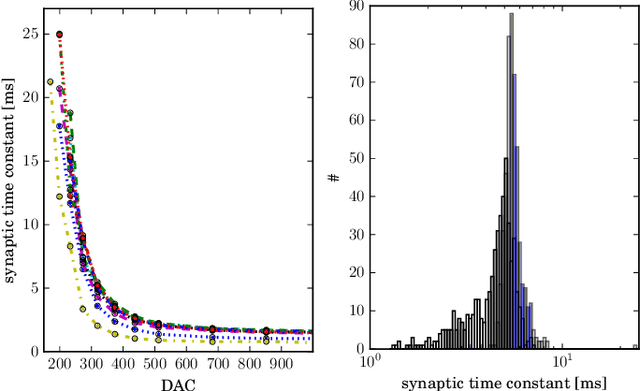
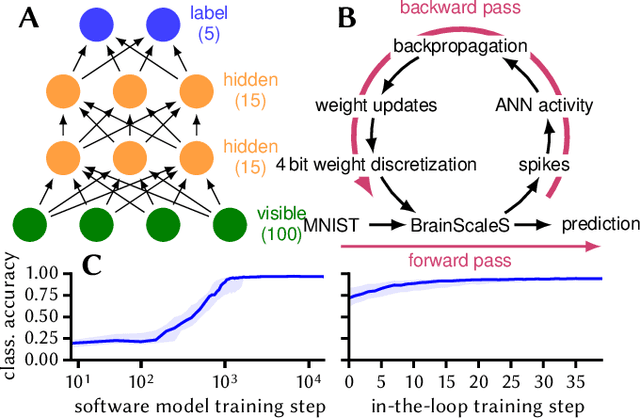
Emulating spiking neural networks on analog neuromorphic hardware offers several advantages over simulating them on conventional computers, particularly in terms of speed and energy consumption. However, this usually comes at the cost of reduced control over the dynamics of the emulated networks. In this paper, we demonstrate how iterative training of a hardware-emulated network can compensate for anomalies induced by the analog substrate. We first convert a deep neural network trained in software to a spiking network on the BrainScaleS wafer-scale neuromorphic system, thereby enabling an acceleration factor of 10 000 compared to the biological time domain. This mapping is followed by the in-the-loop training, where in each training step, the network activity is first recorded in hardware and then used to compute the parameter updates in software via backpropagation. An essential finding is that the parameter updates do not have to be precise, but only need to approximately follow the correct gradient, which simplifies the computation of updates. Using this approach, after only several tens of iterations, the spiking network shows an accuracy close to the ideal software-emulated prototype. The presented techniques show that deep spiking networks emulated on analog neuromorphic devices can attain good computational performance despite the inherent variations of the analog substrate.