 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving Afferent Architectures: Biologically-inspired Models for Damage-Avoidance Learning
Feb 04, 2026We introduce Afferent Learning, a framework that produces Computational Afferent Traces (CATs) as adaptive, internal risk signals for damage-avoidance learning. Inspired by biological systems, the framework uses a two-level architecture: evolutionary optimization (outer loop) discovers afferent sensing architectures that enable effective policy learning, while reinforcement learning (inner loop) trains damage-avoidance policies using these signals. This formalizes afferent sensing as providing an inductive bias for efficient learning: architectures are selected based on their ability to enable effective learning (rather than directly minimizing damage). We provide theoretical convergence guarantees under smoothness and bounded-noise assumptions. We illustrate the general approach in the challenging context of biomechanical digital twins operating over long time horizons (multiple decades of the life-course). Here, we find that CAT-based evolved architectures achieve significantly higher efficiency and better age-robustness than hand-designed baselines, enabling policies that exhibit age-dependent behavioral adaptation (23% reduction in high-risk actions). Ablation studies validate CAT signals, evolution, and predictive discrepancy as essential. We release code and data for reproducibility.
DiGAN: Diffusion-Guided Attention Network for Early Alzheimer's Disease Detection
Feb 02, 2026Early diagnosis of Alzheimer's disease (AD) remains a major challenge due to the subtle and temporally irregular progression of structural brain changes in the prodromal stages. Existing deep learning approaches require large longitudinal datasets and often fail to model the temporal continuity and modality irregularities inherent in real-world clinical data. To address these limitations, we propose the Diffusion-Guided Attention Network (DiGAN), which integrates latent diffusion modelling with an attention-guided convolutional network. The diffusion model synthesizes realistic longitudinal neuroimaging trajectories from limited training data, enriching temporal context and improving robustness to unevenly spaced visits. The attention-convolutional layer then captures discriminative structural--temporal patterns that distinguish cognitively normal subjects from those with mild cognitive impairment and subjective cognitive decline. Experiments on synthetic and ADNI datasets demonstrate that DiGAN outperforms existing state-of-the-art baselines, showing its potential for early-stage AD detection.
RAG for Effective Supply Chain Security Questionnaire Automation
Dec 18, 2024



In an era where digital security is crucial, efficient processing of security-related inquiries through supply chain security questionnaires is imperative. This paper introduces a novel approach using Natural Language Processing (NLP) and Retrieval-Augmented Generation (RAG) to automate these responses. We developed QuestSecure, a system that interprets diverse document formats and generates precise responses by integrating large language models (LLMs) with an advanced retrieval system. Our experiments show that QuestSecure significantly improves response accuracy and operational efficiency. By employing advanced NLP techniques and tailored retrieval mechanisms, the system consistently produces contextually relevant and semantically rich responses, reducing cognitive load on security teams and minimizing potential errors. This research offers promising avenues for automating complex security management tasks, enhancing organizational security processes.
How can neuromorphic hardware attain brain-like functional capabilities?
Oct 25, 2023Research on neuromorphic computing is driven by the vision that we can emulate brain-like computing capability, learning capability, and energy-efficiency in novel hardware. Unfortunately, this vision has so far been pursued in a half-hearted manner. Most current neuromorphic hardware (NMHW) employs brain-like spiking neurons instead of standard artificial neurons. This is a good first step, which does improve the energy-efficiency of some computations, see \citep{rao2022long} for one of many examples. But current architectures and training methods for networks of spiking neurons in NMHW are largely copied from artificial neural networks. Hence it is not surprising that they inherit many deficiencies of artificial neural networks, rather than attaining brain-like functional capabilities. Of course, the brain is very complex, and we cannot implement all its details in NMHW. Instead, we need to focus on principles that are both easy to implement in NMHW and are likely to support brain-like functionality. The goal of this article is to highlight some of them.
Pairing Conceptual Modeling with Machine Learning
Jul 15, 2021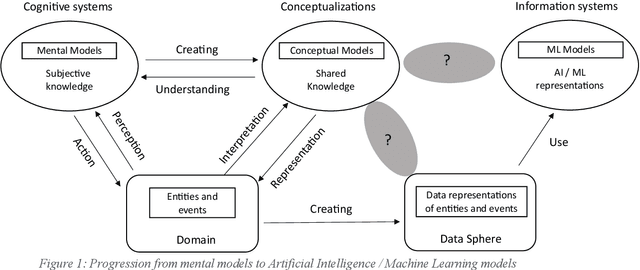
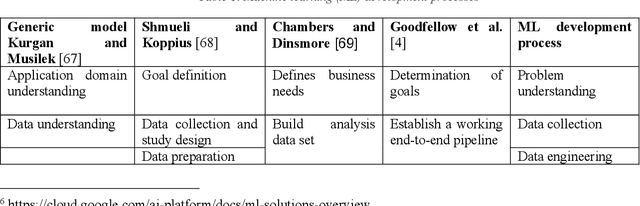
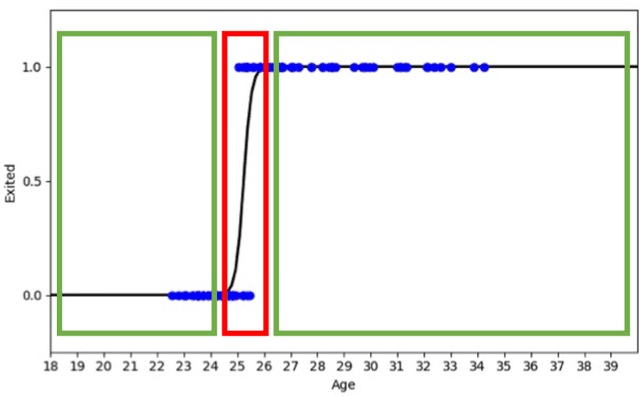

Both conceptual modeling and machine learning have long been recognized as important areas of research. With the increasing emphasis on digitizing and processing large amounts of data for business and other applications, it would be helpful to consider how these areas of research can complement each other. To understand how they can be paired, we provide an overview of machine learning foundations and development cycle. We then examine how conceptual modeling can be applied to machine learning and propose a framework for incorporating conceptual modeling into data science projects. The framework is illustrated by applying it to a healthcare application. For the inverse pairing, machine learning can impact conceptual modeling through text and rule mining, as well as knowledge graphs. The pairing of conceptual modeling and machine learning in this this way should help lay the foundations for future research.
A Long Short-Term Memory for AI Applications in Spike-based Neuromorphic Hardware
Jul 08, 2021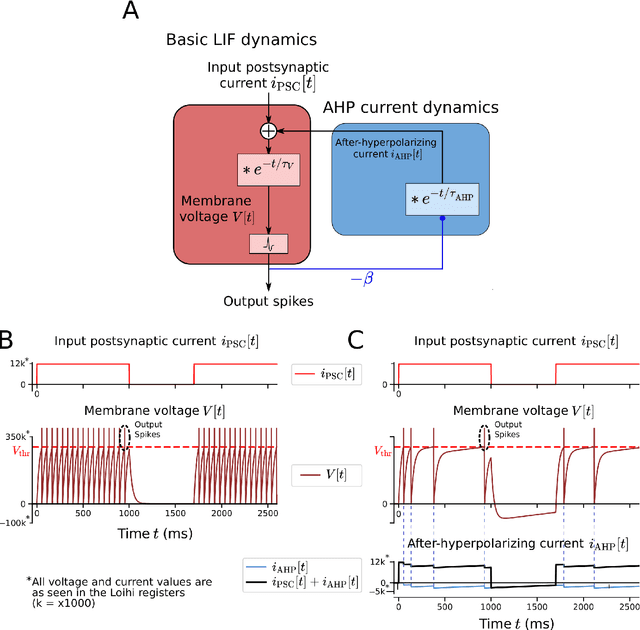
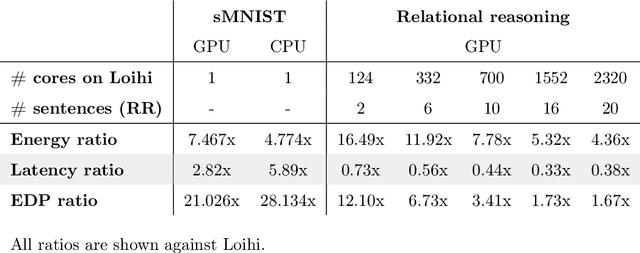
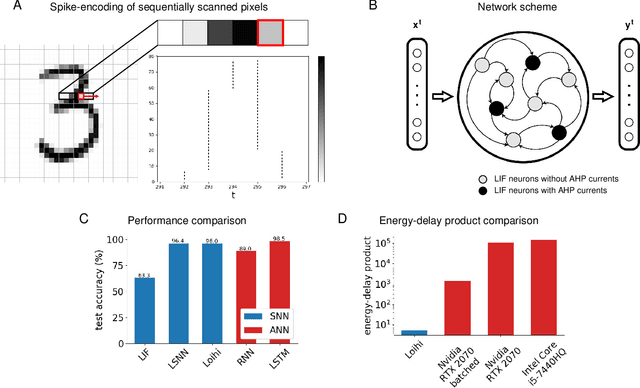
In spite of intensive efforts it has remained an open problem to what extent current Artificial Intelligence (AI) methods that employ Deep Neural Networks (DNNs) can be implemented more energy-efficiently on spike-based neuromorphic hardware. This holds in particular for AI methods that solve sequence processing tasks, a primary application target for spike-based neuromorphic hardware. One difficulty is that DNNs for such tasks typically employ Long Short-Term Memory (LSTM) units. Yet an efficient emulation of these units in spike-based hardware has been missing. We present a biologically inspired solution that solves this problem. This solution enables us to implement a major class of DNNs for sequence processing tasks such as time series classification and question answering with substantial energy savings on neuromorphic hardware. In fact, the Relational Network for reasoning about relations between objects that we use for question answering is the first example of a large DNN that carries out a sequence processing task with substantial energy-saving on neuromorphic hardware.
CCN GAC Workshop: Issues with learning in biological recurrent neural networks
May 12, 2021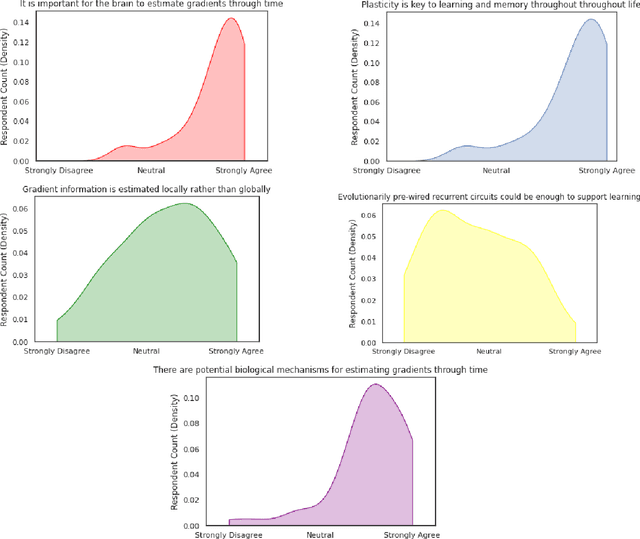
This perspective piece came about through the Generative Adversarial Collaboration (GAC) series of workshops organized by the Computational Cognitive Neuroscience (CCN) conference in 2020. We brought together a number of experts from the field of theoretical neuroscience to debate emerging issues in our understanding of how learning is implemented in biological recurrent neural networks. Here, we will give a brief review of the common assumptions about biological learning and the corresponding findings from experimental neuroscience and contrast them with the efficiency of gradient-based learning in recurrent neural networks commonly used in artificial intelligence. We will then outline the key issues discussed in the workshop: synaptic plasticity, neural circuits, theory-experiment divide, and objective functions. Finally, we conclude with recommendations for both theoretical and experimental neuroscientists when designing new studies that could help to bring clarity to these issues.
Online spatio-temporal learning in deep neural networks
Jul 24, 2020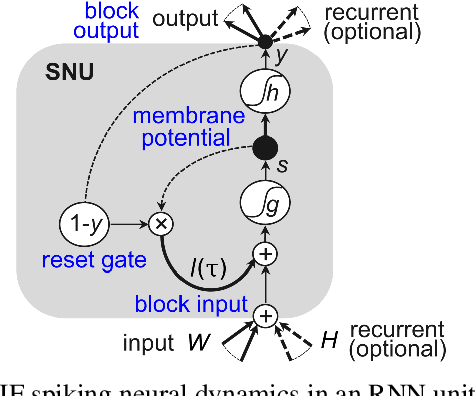
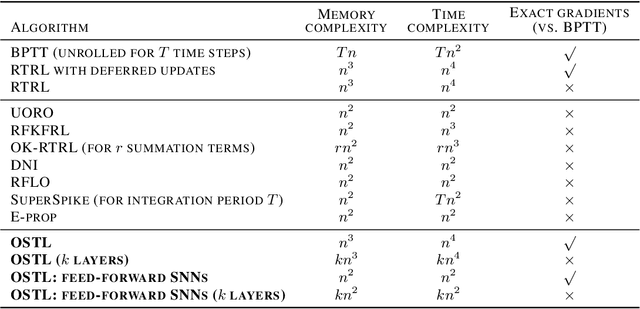
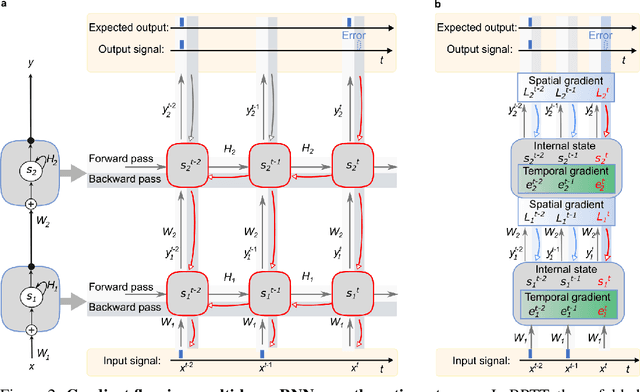
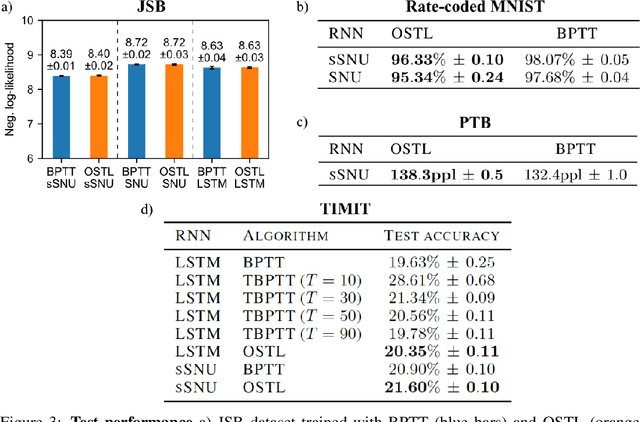
Biological neural networks are equipped with an inherent capability to continuously adapt through online learning. This aspect remains in stark contrast to learning with error backpropagation through time (BPTT) applied to recurrent neural networks (RNNs), or recently even to biologically-inspired spiking neural networks (SNNs), because the unrolling through time of BPTT leads to system-locking problems. Online learning has recently regained the attention of the research community, focusing either on approaches that approximate BPTT or on biologically-plausible schemes applied in SNNs. Here we present an alternative perspective that is based on a clear separation of spatial and temporal gradient components. Combined with insights from biology, we derive from first principles a novel online learning algorithm, called online spatio-temporal learning (OSTL), which is gradient-equivalent to BPTT for shallow networks. We apply OSTL to SNNs allowing them for the first time to be trained online with BPTT-equivalent gradients. In addition, the proposed formulation uncovers a class of SNN architectures trainable online at low complexity. Moreover, we extend OSTL to deep networks while maintaining its key characteristics. Besides SNNs, the generic form of OSTL is applicable to a wide range of network architectures, including networks comprising long short-term memory (LSTM) and gated recurrent units (GRU). We demonstrate the operation of our algorithm on various tasks from language modelling to speech recognition, and obtain results on par with the BPTT baselines. The proposed algorithm provides a framework for developing succinct and efficient online training approaches for SNNs and in general deep RNNs.
Embodied Synaptic Plasticity with Online Reinforcement learning
Mar 03, 2020



The endeavor to understand the brain involves multiple collaborating research fields. Classically, synaptic plasticity rules derived by theoretical neuroscientists are evaluated in isolation on pattern classification tasks. This contrasts with the biological brain which purpose is to control a body in closed-loop. This paper contributes to bringing the fields of computational neuroscience and robotics closer together by integrating open-source software components from these two fields. The resulting framework allows to evaluate the validity of biologically-plausibe plasticity models in closed-loop robotics environments. We demonstrate this framework to evaluate Synaptic Plasticity with Online REinforcement learning (SPORE), a reward-learning rule based on synaptic sampling, on two visuomotor tasks: reaching and lane following. We show that SPORE is capable of learning to perform policies within the course of simulated hours for both tasks. Provisional parameter explorations indicate that the learning rate and the temperature driving the stochastic processes that govern synaptic learning dynamics need to be regulated for performance improvements to be retained. We conclude by discussing the recent deep reinforcement learning techniques which would be beneficial to increase the functionality of SPORE on visuomotor tasks.
* 18 pages, 5 figures, published in frontiers in neurorobotics
Classifying Images with Few Spikes per Neuron
Jan 31, 2020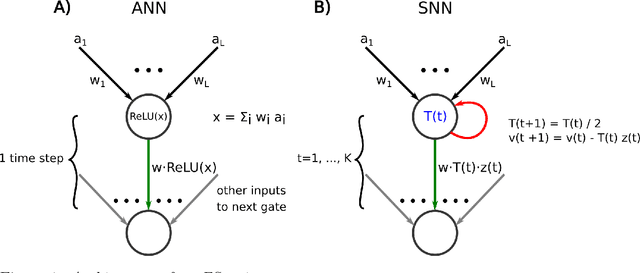

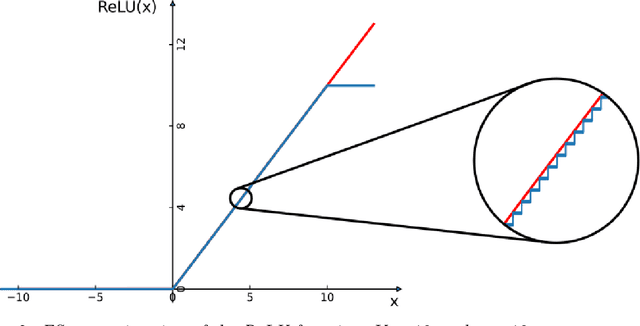

Spiking neural networks (SNNs) promise to provide AI implementations with a drastically reduced energy budget in comparison with standard artificial neural networks (ANNs). Besides recurrent SNN modules that can be efficiently trained on-chip, many AI applications require the use of feedforward convolutional neural networks (CNNs) as preprocessors for visual or other sensory inputs. The standard solution has been to train a CNN consisting of non-spiking neurons, typically using the rectified linear ReLU function as activation function, and then to translate these CNNs with ReLU neurons via rate coding into SNNs. However this produces SNNs with long latency and small throughput, since the number of spikes that a neuron has to emit is on the order of the number N of output values of the corresponding CNN gate which subsequent layers need to be able to distinguish. We introduce a new ANN-SNN conversion - called FS-conversion - that needs only log N many time steps for that, which is optimal from the perspective of information theory. This can be achieved with a simple variation of the spiking neuron model that has no membrane leak but an exponentially decreasing firing threshold. We show that for the classification of images from ImageNet and CIFAR10 this new conversion reduces latency and drastically increases the throughput compared with rate-based conversion, while achieving almost the same classification performance as the ANN.