 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning Through Efference Copies
Oct 17, 2022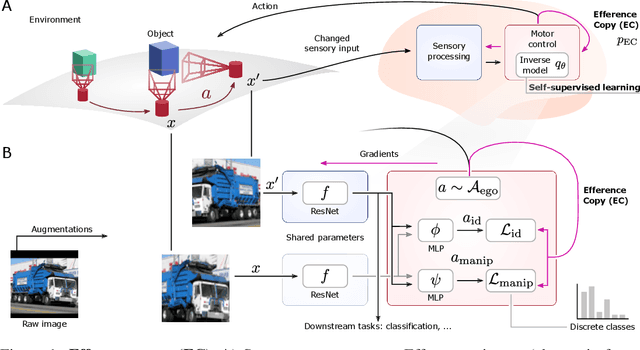
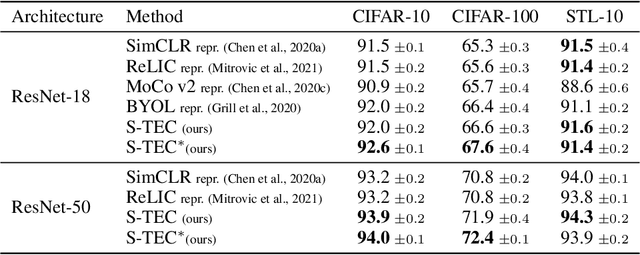
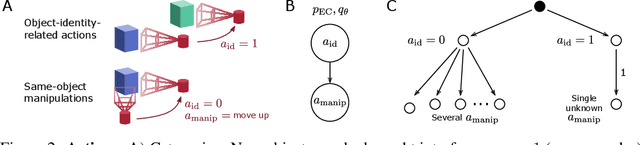

Self-supervised learning (SSL) methods aim to exploit the abundance of unlabelled data for machine learning (ML), however the underlying principles are often method-specific. An SSL framework derived from biological first principles of embodied learning could unify the various SSL methods, help elucidate learning in the brain, and possibly improve ML. SSL commonly transforms each training datapoint into a pair of views, uses the knowledge of this pairing as a positive (i.e. non-contrastive) self-supervisory sign, and potentially opposes it to unrelated, (i.e. contrastive) negative examples. Here, we show that this type of self-supervision is an incomplete implementation of a concept from neuroscience, the Efference Copy (EC). Specifically, the brain also transforms the environment through efference, i.e. motor commands, however it sends to itself an EC of the full commands, i.e. more than a mere SSL sign. In addition, its action representations are likely egocentric. From such a principled foundation we formally recover and extend SSL methods such as SimCLR, BYOL, and ReLIC under a common theoretical framework, i.e. Self-supervision Through Efference Copies (S-TEC). Empirically, S-TEC restructures meaningfully the within- and between-class representations. This manifests as improvement in recent strong SSL baselines in image classification, segmentation, object detection, and in audio. These results hypothesize a testable positive influence from the brain's motor outputs onto its sensory representations.
CCN GAC Workshop: Issues with learning in biological recurrent neural networks
May 12, 2021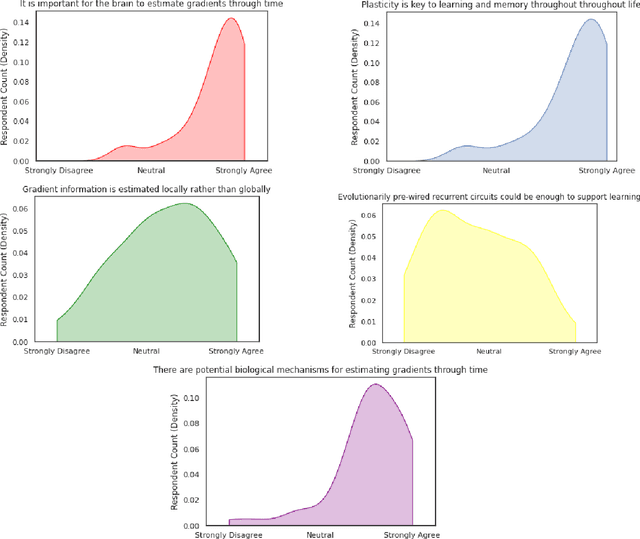
This perspective piece came about through the Generative Adversarial Collaboration (GAC) series of workshops organized by the Computational Cognitive Neuroscience (CCN) conference in 2020. We brought together a number of experts from the field of theoretical neuroscience to debate emerging issues in our understanding of how learning is implemented in biological recurrent neural networks. Here, we will give a brief review of the common assumptions about biological learning and the corresponding findings from experimental neuroscience and contrast them with the efficiency of gradient-based learning in recurrent neural networks commonly used in artificial intelligence. We will then outline the key issues discussed in the workshop: synaptic plasticity, neural circuits, theory-experiment divide, and objective functions. Finally, we conclude with recommendations for both theoretical and experimental neuroscientists when designing new studies that could help to bring clarity to these issues.
Reservoirs learn to learn
Sep 30, 2019


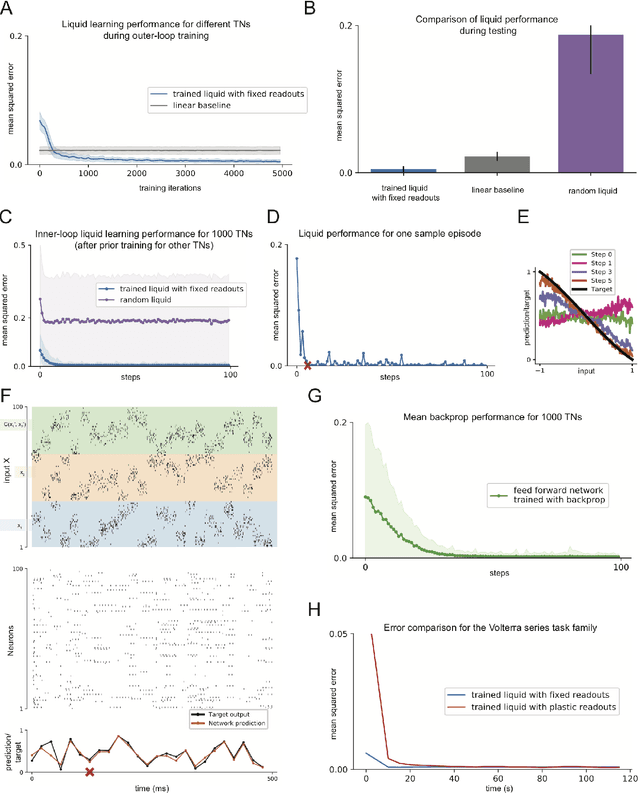
We consider reservoirs in the form of liquid state machines, i.e., recurrently connected networks of spiking neurons with randomly chosen weights. So far only the weights of a linear readout were adapted for a specific task. We wondered whether the performance of liquid state machines can be improved if the recurrent weights are chosen with a purpose, rather than randomly. After all, weights of recurrent connections in the brain are also not assumed to be randomly chosen. Rather, these weights were probably optimized during evolution, development, and prior learning experiences for specific task domains. In order to examine the benefits of choosing recurrent weights within a liquid with a purpose, we applied the Learning-to-Learn (L2L) paradigm to our model: We optimized the weights of the recurrent connections -- and hence the dynamics of the liquid state machine -- for a large family of potential learning tasks, which the network might have to learn later through modification of the weights of readout neurons. We found that this two-tiered process substantially improves the learning speed of liquid state machines for specific tasks. In fact, this learning speed increases further if one does not train the weights of linear readouts at all, and relies instead on the internal dynamics and fading memory of the network for remembering salient information that it could extract from preceding examples for the current learning task. This second type of learning has recently been proposed to underlie fast learning in the prefrontal cortex and motor cortex, and hence it is of interest to explore its performance also in models. Since liquid state machines share many properties with other types of reservoirs, our results raise the question whether L2L conveys similar benefits also to these other reservoirs.
Neuromorphic Hardware learns to learn
Mar 18, 2019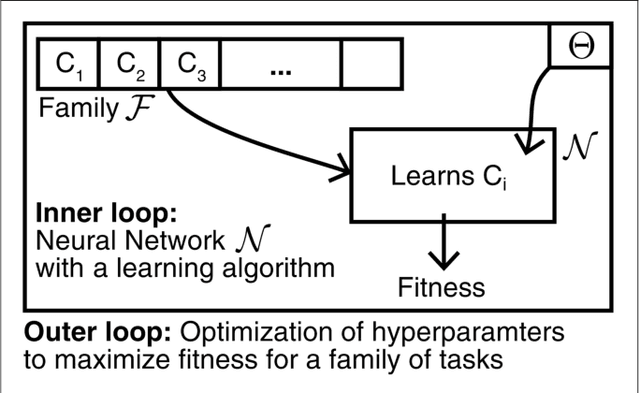
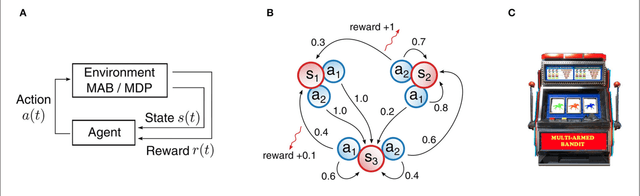

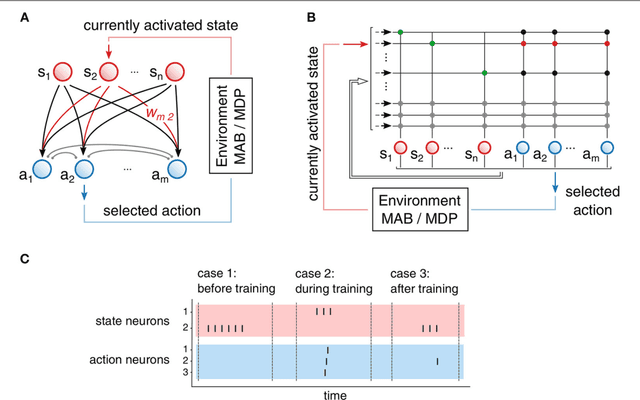
Hyperparameters and learning algorithms for neuromorphic hardware are usually chosen by hand. In contrast, the hyperparameters and learning algorithms of networks of neurons in the brain, which they aim to emulate, have been optimized through extensive evolutionary and developmental processes for specific ranges of computing and learning tasks. Occasionally this process has been emulated through genetic algorithms, but these require themselves hand-design of their details and tend to provide a limited range of improvements. We employ instead other powerful gradient-free optimization tools, such as cross-entropy methods and evolutionary strategies, in order to port the function of biological optimization processes to neuromorphic hardware. As an example, we show that this method produces neuromorphic agents that learn very efficiently from rewards. In particular, meta-plasticity, i.e., the optimization of the learning rule which they use, substantially enhances reward-based learning capability of the hardware. In addition, we demonstrate for the first time Learning-to-Learn benefits from such hardware, in particular, the capability to extract abstract knowledge from prior learning experiences that speeds up the learning of new but related tasks. Learning-to-Learn is especially suited for accelerated neuromorphic hardware, since it makes it feasible to carry out the required very large number of network computations.
Biologically inspired alternatives to backpropagation through time for learning in recurrent neural nets
Jan 25, 2019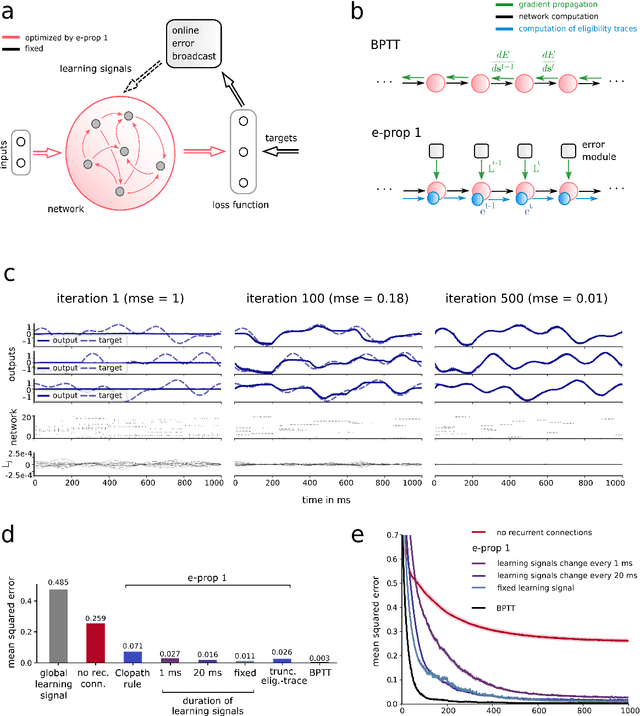
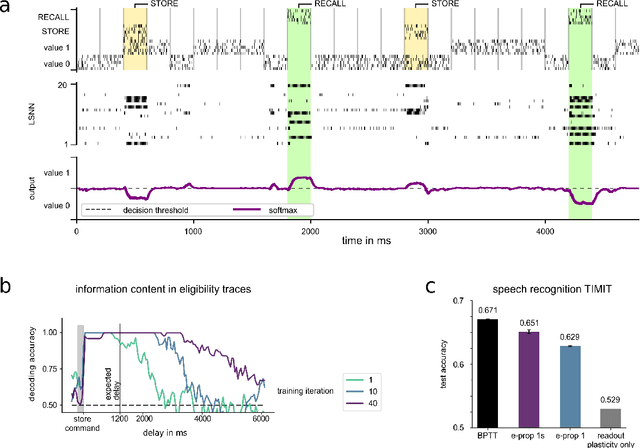
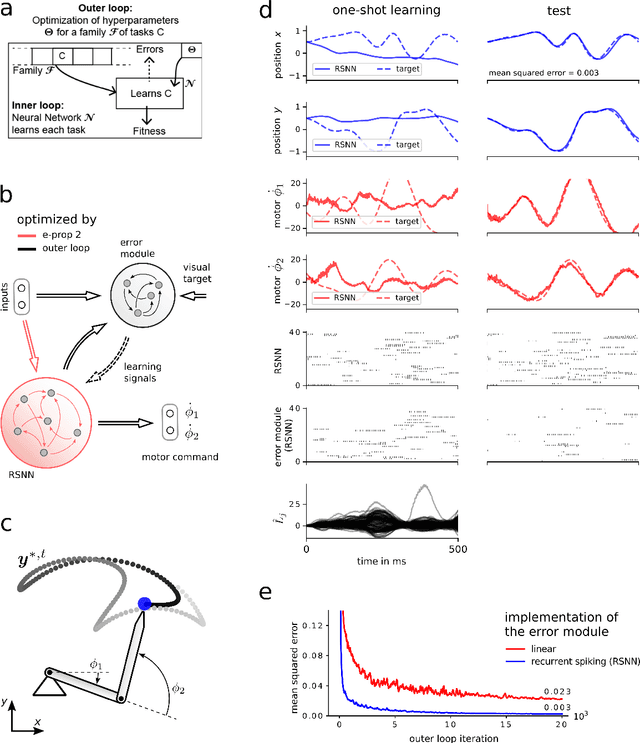
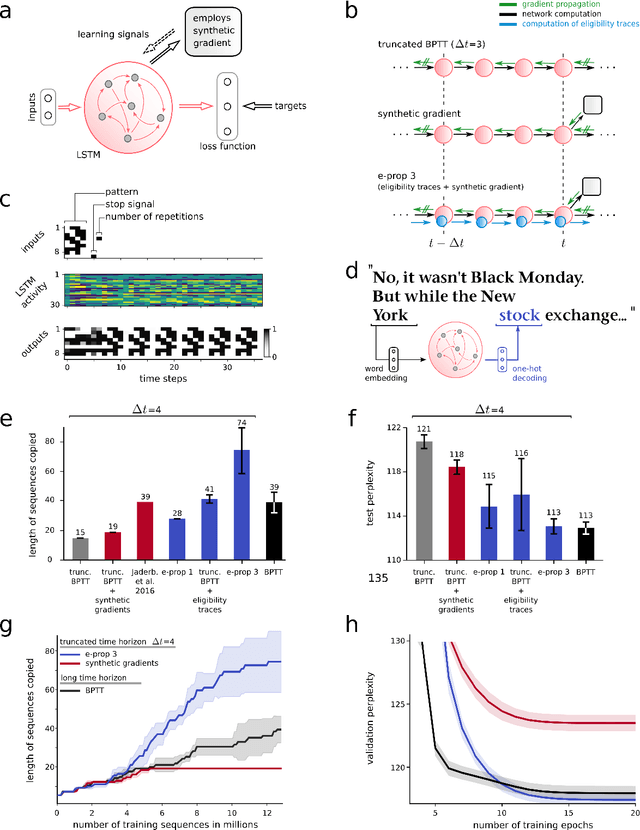
The way how recurrently connected networks of spiking neurons in the brain acquire powerful information processing capabilities through learning has remained a mystery. This lack of understanding is linked to a lack of learning algorithms for recurrent networks of spiking neurons (RSNNs) that are both functionally powerful and can be implemented by known biological mechanisms. Since RSNNs are simultaneously a primary target for implementations of brain-inspired circuits in neuromorphic hardware, this lack of algorithmic insight also hinders technological progress in that area. The gold standard for learning in recurrent neural networks in machine learning is back-propagation through time (BPTT), which implements stochastic gradient descent with regard to a given loss function. But BPTT is unrealistic from a biological perspective, since it requires a transmission of error signals backwards in time and in space, i.e., from post- to presynaptic neurons. We show that an online merging of locally available information during a computation with suitable top-down learning signals in real-time provides highly capable approximations to BPTT. For tasks where information on errors arises only late during a network computation, we enrich locally available information through feedforward eligibility traces of synapses that can easily be computed in an online manner. The resulting new generation of learning algorithms for recurrent neural networks provides a new understanding of network learning in the brain that can be tested experimentally. In addition, these algorithms provide efficient methods for on-chip training of RSNNs in neuromorphic hardware.