 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiologically inspired alternatives to backpropagation through time for learning in recurrent neural nets
Jan 25, 2019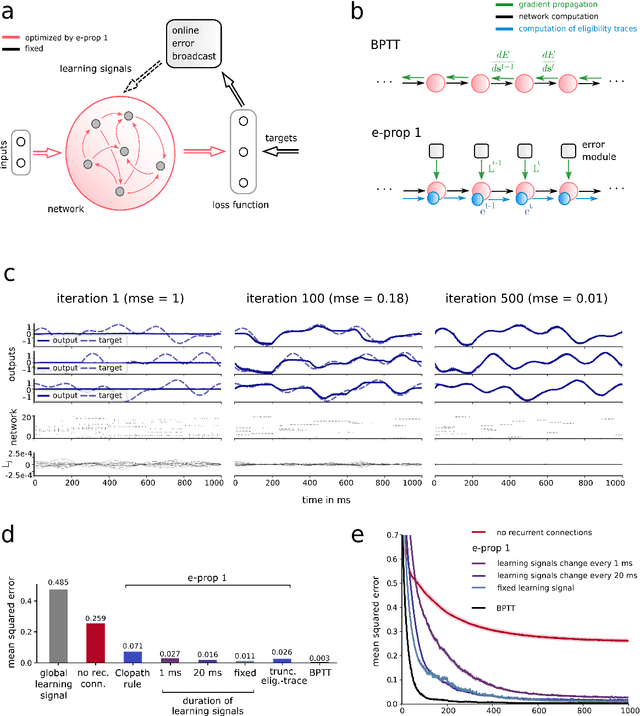
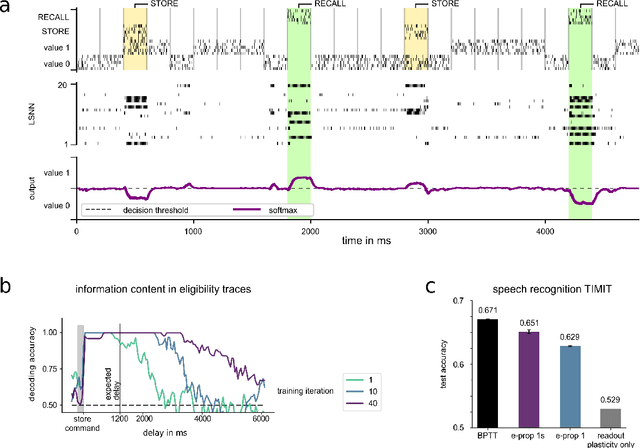
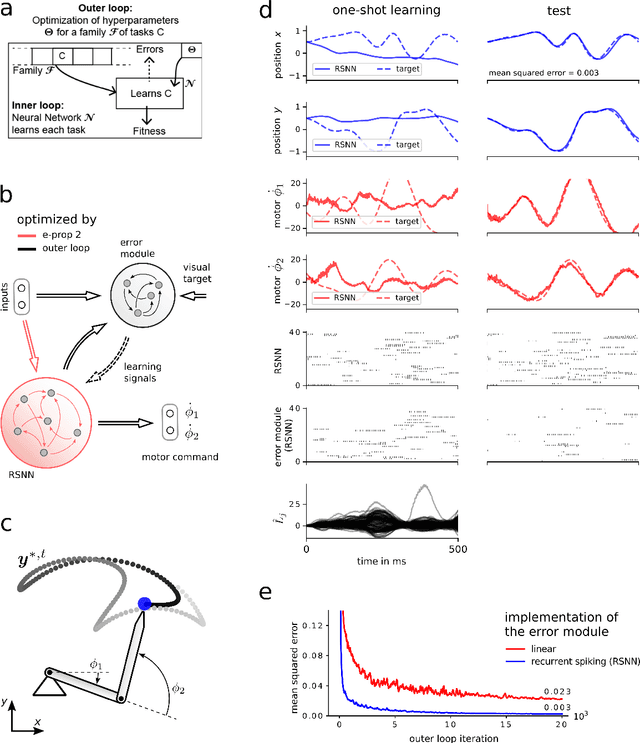
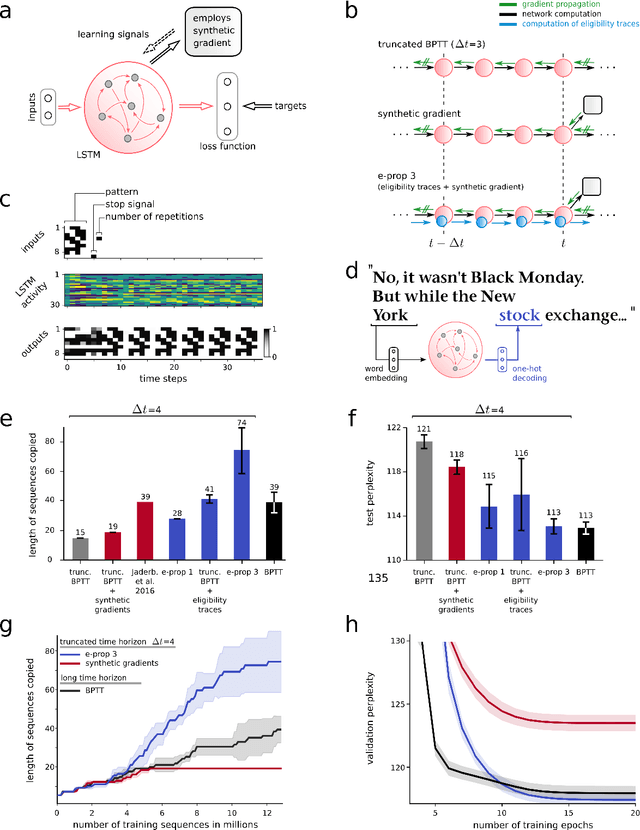
The way how recurrently connected networks of spiking neurons in the brain acquire powerful information processing capabilities through learning has remained a mystery. This lack of understanding is linked to a lack of learning algorithms for recurrent networks of spiking neurons (RSNNs) that are both functionally powerful and can be implemented by known biological mechanisms. Since RSNNs are simultaneously a primary target for implementations of brain-inspired circuits in neuromorphic hardware, this lack of algorithmic insight also hinders technological progress in that area. The gold standard for learning in recurrent neural networks in machine learning is back-propagation through time (BPTT), which implements stochastic gradient descent with regard to a given loss function. But BPTT is unrealistic from a biological perspective, since it requires a transmission of error signals backwards in time and in space, i.e., from post- to presynaptic neurons. We show that an online merging of locally available information during a computation with suitable top-down learning signals in real-time provides highly capable approximations to BPTT. For tasks where information on errors arises only late during a network computation, we enrich locally available information through feedforward eligibility traces of synapses that can easily be computed in an online manner. The resulting new generation of learning algorithms for recurrent neural networks provides a new understanding of network learning in the brain that can be tested experimentally. In addition, these algorithms provide efficient methods for on-chip training of RSNNs in neuromorphic hardware.
Long short-term memory and learning-to-learn in networks of spiking neurons
Nov 02, 2018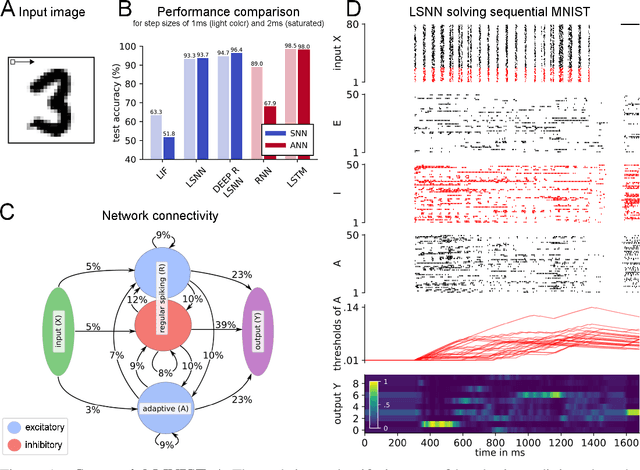
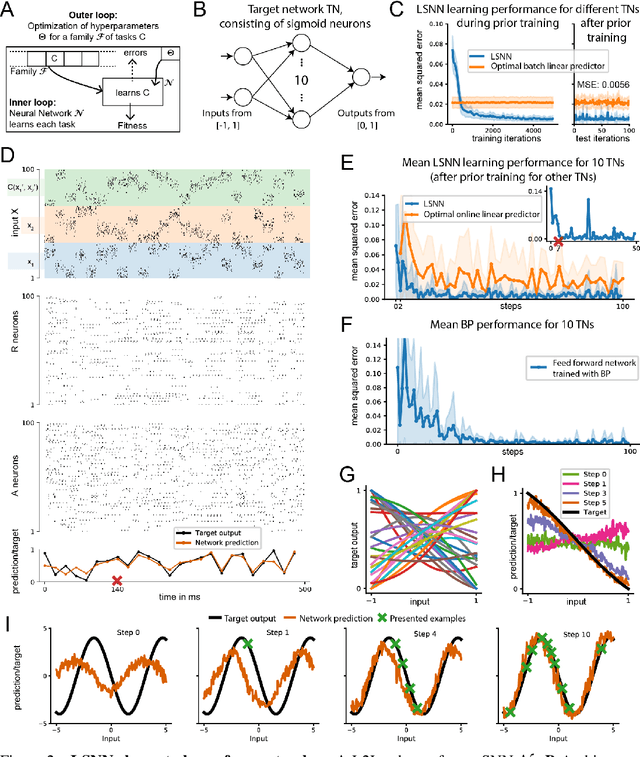
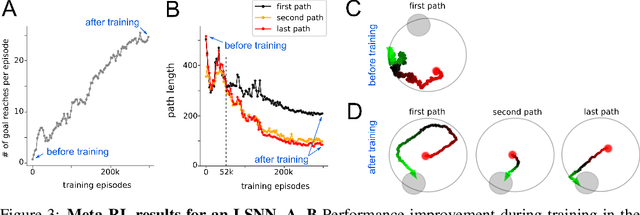
Recurrent networks of spiking neurons (RSNNs) underlie the astounding computing and learning capabilities of the brain. But computing and learning capabilities of RSNN models have remained poor, at least in comparison with ANNs. We address two possible reasons for that. One is that RSNNs in the brain are not randomly connected or designed according to simple rules, and they do not start learning as a tabula rasa network. Rather, RSNNs in the brain were optimized for their tasks through evolution, development, and prior experience. Details of these optimization processes are largely unknown. But their functional contribution can be approximated through powerful optimization methods, such as backpropagation through time (BPTT). A second major mismatch between RSNNs in the brain and models is that the latter only show a small fraction of the dynamics of neurons and synapses in the brain. We include neurons in our RSNN model that reproduce one prominent dynamical process of biological neurons that takes place at the behaviourally relevant time scale of seconds: neuronal adaptation. We denote these networks as LSNNs because of their Long short-term memory. The inclusion of adapting neurons drastically increases the computing and learning capability of RSNNs if they are trained and configured by deep learning (BPTT combined with a rewiring algorithm that optimizes the network architecture). In fact, the computational performance of these RSNNs approaches for the first time that of LSTM networks. In addition RSNNs with adapting neurons can acquire abstract knowledge from prior learning in a Learning-to-Learn (L2L) scheme, and transfer that knowledge in order to learn new but related tasks from very few examples. We demonstrate this for supervised learning and reinforcement learning.