 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Length Generalization in Mamba via Image Reconstruction
Mar 12, 2026Mamba has attracted widespread interest as a general-purpose sequence model due to its low computational complexity and competitive performance relative to transformers. However, its performance can degrade when inference sequence lengths exceed those seen during training. We study this phenomenon using a controlled vision task in which Mamba reconstructs images from sequences of image patches. By analyzing reconstructions at different stages of sequence processing, we reveal that Mamba qualitatively adapts its behavior to the distribution of sequence lengths encountered during training, resulting in strategies that fail to generalize beyond this range. To support our analysis, we introduce a length-adaptive variant of Mamba that improves performance across training sequence lengths. Our results provide an intuitive perspective on length generalization in Mamba and suggest directions for improving the architecture.
Training event-based neural networks with exact gradients via Differentiable ODE Solving in JAX
Mar 09, 2026Existing frameworks for gradient-based training of spiking neural networks face a trade-off: discrete-time methods using surrogate gradients support arbitrary neuron models but introduce gradient bias and constrain spike-time resolution, while continuous-time methods that compute exact gradients require analytical expressions for spike times and state evolution, restricting them to simple neuron types such as Leaky Integrate and Fire (LIF). We introduce the Eventax framework, which resolves this trade-off by combining differentiable numerical ODE solvers with event-based spike handling. Built in JAX, our frame-work uses Diffrax ODE-solvers to compute gradients that are exact with respect to the forward simulation for any neuron model defined by ODEs . It also provides a simple API where users can specify just the neuron dynamics, spike conditions, and reset rules. Eventax prioritises modelling flexibility, supporting a wide range of neuron models, loss functions, and network architectures, which can be easily extended. We demonstrate Eventax on multiple benchmarks, including Yin-Yang and MNIST, using diverse neuron models such as Leaky Integrate-and-fire (LIF), Quadratic Integrate-and-fire (QIF), Exponential integrate-and-fire (EIF), Izhikevich and Event-based Gated Recurrent Unit (EGRU) with both time-to-first-spike and state-based loss functions, demonstrating its utility for prototyping and testing event-based architectures trained with exact gradients. We also demonstrate the application of this framework for more complex neuron types by implementing a multi-compartment neuron that uses a model of dendritic spikes in human layer 2/3 cortical Pyramidal neurons for computation. Code available at https://github.com/efficient-scalable-machine-learning/eventax.
Utilizing dynamic sparsity on pretrained DETR
Oct 10, 2025Efficient inference with transformer-based models remains a challenge, especially in vision tasks like object detection. We analyze the inherent sparsity in the MLP layers of DETR and introduce two methods to exploit it without retraining. First, we propose Static Indicator-Based Sparsification (SIBS), a heuristic method that predicts neuron inactivity based on fixed activation patterns. While simple, SIBS offers limited gains due to the input-dependent nature of sparsity. To address this, we introduce Micro-Gated Sparsification (MGS), a lightweight gating mechanism trained on top of a pretrained DETR. MGS predicts dynamic sparsity using a small linear layer and achieves up to 85 to 95% activation sparsity. Experiments on the COCO dataset show that MGS maintains or even improves performance while significantly reducing computation. Our method offers a practical, input-adaptive approach to sparsification, enabling efficient deployment of pretrained vision transformers without full model retraining.
STREAM: A Universal State-Space Model for Sparse Geometric Data
Nov 19, 2024Handling sparse and unstructured geometric data, such as point clouds or event-based vision, is a pressing challenge in the field of machine vision. Recently, sequence models such as Transformers and state-space models entered the domain of geometric data. These methods require specialized preprocessing to create a sequential view of a set of points. Furthermore, prior works involving sequence models iterate geometric data with either uniform or learned step sizes, implicitly relying on the model to infer the underlying geometric structure. In this work, we propose to encode geometric structure explicitly into the parameterization of a state-space model. State-space models are based on linear dynamics governed by a one-dimensional variable such as time or a spatial coordinate. We exploit this dynamic variable to inject relative differences of coordinates into the step size of the state-space model. The resulting geometric operation computes interactions between all pairs of N points in O(N) steps. Our model deploys the Mamba selective state-space model with a modified CUDA kernel to efficiently map sparse geometric data to modern hardware. The resulting sequence model, which we call STREAM, achieves competitive results on a range of benchmarks from point-cloud classification to event-based vision and audio classification. STREAM demonstrates a powerful inductive bias for sparse geometric data by improving the PointMamba baseline when trained from scratch on the ModelNet40 and ScanObjectNN point cloud analysis datasets. It further achieves, for the first time, 100% test accuracy on all 11 classes of the DVS128 Gestures dataset.
State-space models can learn in-context by gradient descent
Oct 15, 2024Deep state-space models (Deep SSMs) have shown capabilities for in-context learning on autoregressive tasks, similar to transformers. However, the architectural requirements and mechanisms enabling this in recurrent networks remain unclear. This study demonstrates that state-space model architectures can perform gradient-based learning and use it for in-context learning. We prove that a single structured state-space model layer, augmented with local self-attention, can reproduce the outputs of an implicit linear model with least squares loss after one step of gradient descent. Our key insight is that the diagonal linear recurrent layer can act as a gradient accumulator, which can be `applied' to the parameters of the implicit regression model. We validate our construction by training randomly initialized augmented SSMs on simple linear regression tasks. The empirically optimized parameters match the theoretical ones, obtained analytically from the implicit model construction. Extensions to multi-step linear and non-linear regression yield consistent results. The constructed SSM encompasses features of modern deep state-space models, with the potential for scalable training and effectiveness even in general tasks. The theoretical construction elucidates the role of local self-attention and multiplicative interactions in recurrent architectures as the key ingredients for enabling the expressive power typical of foundation models.
Exploring the limits of Hierarchical World Models in Reinforcement Learning
Jun 01, 2024Hierarchical model-based reinforcement learning (HMBRL) aims to combine the benefits of better sample efficiency of model based reinforcement learning (MBRL) with the abstraction capability of hierarchical reinforcement learning (HRL) to solve complex tasks efficiently. While HMBRL has great potential, it still lacks wide adoption. In this work we describe a novel HMBRL framework and evaluate it thoroughly. To complement the multi-layered decision making idiom characteristic for HRL, we construct hierarchical world models that simulate environment dynamics at various levels of temporal abstraction. These models are used to train a stack of agents that communicate in a top-down manner by proposing goals to their subordinate agents. A significant focus of this study is the exploration of a static and environment agnostic temporal abstraction, which allows concurrent training of models and agents throughout the hierarchy. Unlike most goal-conditioned H(MB)RL approaches, it also leads to comparatively low dimensional abstract actions. Although our HMBRL approach did not outperform traditional methods in terms of final episode returns, it successfully facilitated decision making across two levels of abstraction using compact, low dimensional abstract actions. A central challenge in enhancing our method's performance, as uncovered through comprehensive experimentation, is model exploitation on the abstract level of our world model stack. We provide an in depth examination of this issue, discussing its implications for the field and suggesting directions for future research to overcome this challenge. By sharing these findings, we aim to contribute to the broader discourse on refining HMBRL methodologies and to assist in the development of more effective autonomous learning systems for complex decision-making environments.
Weight Sparsity Complements Activity Sparsity in Neuromorphic Language Models
May 01, 2024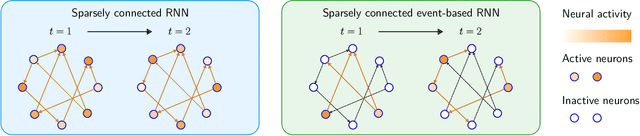
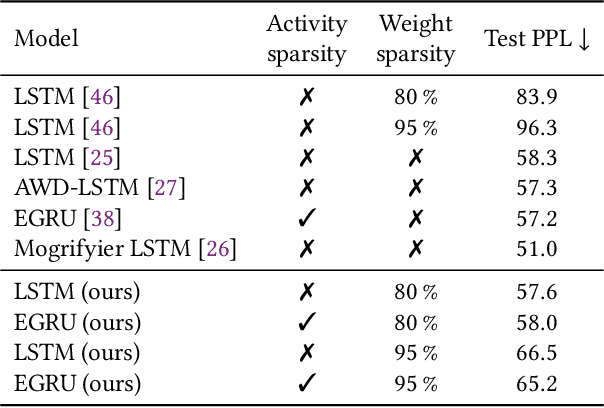
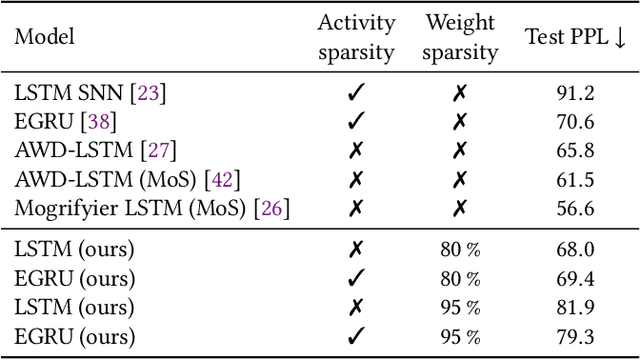
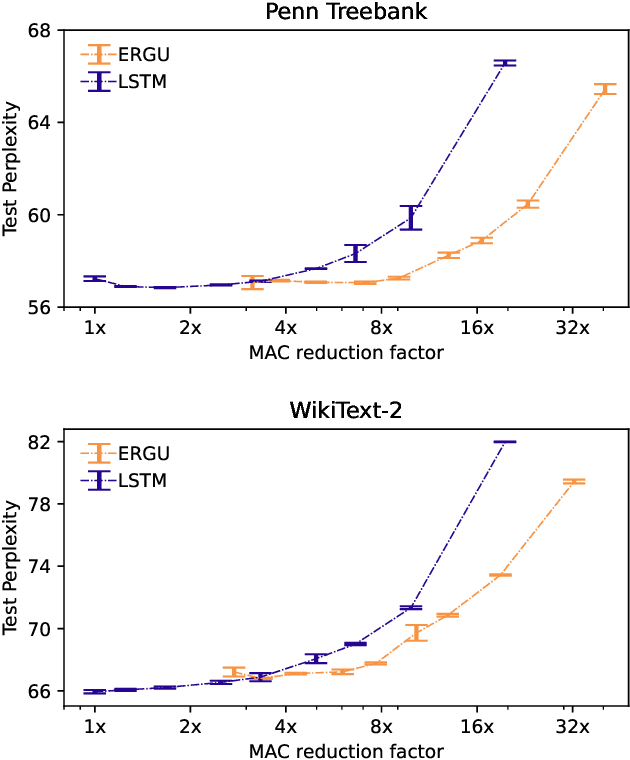
Activity and parameter sparsity are two standard methods of making neural networks computationally more efficient. Event-based architectures such as spiking neural networks (SNNs) naturally exhibit activity sparsity, and many methods exist to sparsify their connectivity by pruning weights. While the effect of weight pruning on feed-forward SNNs has been previously studied for computer vision tasks, the effects of pruning for complex sequence tasks like language modeling are less well studied since SNNs have traditionally struggled to achieve meaningful performance on these tasks. Using a recently published SNN-like architecture that works well on small-scale language modeling, we study the effects of weight pruning when combined with activity sparsity. Specifically, we study the trade-off between the multiplicative efficiency gains the combination affords and its effect on task performance for language modeling. To dissect the effects of the two sparsities, we conduct a comparative analysis between densely activated models and sparsely activated event-based models across varying degrees of connectivity sparsity. We demonstrate that sparse activity and sparse connectivity complement each other without a proportional drop in task performance for an event-based neural network trained on the Penn Treebank and WikiText-2 language modeling datasets. Our results suggest sparsely connected event-based neural networks are promising candidates for effective and efficient sequence modeling.
Scalable Event-by-event Processing of Neuromorphic Sensory Signals With Deep State-Space Models
Apr 29, 2024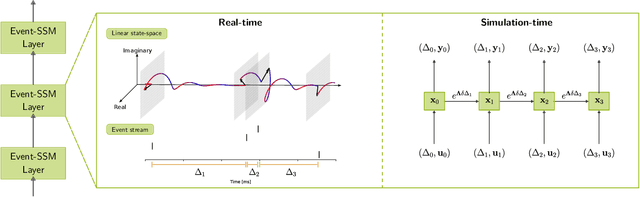
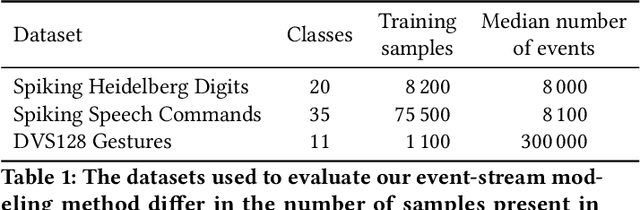
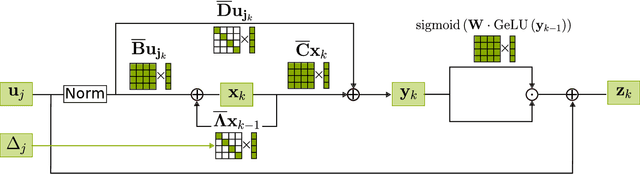

Event-based sensors are well suited for real-time processing due to their fast response times and encoding of the sensory data as successive temporal differences. These and other valuable properties, such as a high dynamic range, are suppressed when the data is converted to a frame-based format. However, most current methods either collapse events into frames or cannot scale up when processing the event data directly event-by-event. In this work, we address the key challenges of scaling up event-by-event modeling of the long event streams emitted by such sensors, which is a particularly relevant problem for neuromorphic computing. While prior methods can process up to a few thousand time steps, our model, based on modern recurrent deep state-space models, scales to event streams of millions of events for both training and inference.We leverage their stable parameterization for learning long-range dependencies, parallelizability along the sequence dimension, and their ability to integrate asynchronous events effectively to scale them up to long event streams.We further augment these with novel event-centric techniques enabling our model to match or beat the state-of-the-art performance on several event stream benchmarks. In the Spiking Speech Commands task, we improve state-of-the-art by a large margin of 6.6% to 87.1%. On the DVS128-Gestures dataset, we achieve competitive results without using frames or convolutional neural networks. Our work demonstrates, for the first time, that it is possible to use fully event-based processing with purely recurrent networks to achieve state-of-the-art task performance in several event-based benchmarks.
Language Modeling on a SpiNNaker 2 Neuromorphic Chip
Dec 14, 2023



As large language models continue to scale in size rapidly, so too does the computational power required to run them. Event-based networks on neuromorphic devices offer a potential way to reduce energy consumption for inference significantly. However, to date, most event-based networks that can run on neuromorphic hardware, including spiking neural networks (SNNs), have not achieved task performance even on par with LSTM models for language modeling. As a result, language modeling on neuromorphic devices has seemed a distant prospect. In this work, we demonstrate the first-ever implementation of a language model on a neuromorphic device - specifically the SpiNNaker 2 chip - based on a recently published event-based architecture called the EGRU. SpiNNaker 2 is a many-core neuromorphic chip designed for large-scale asynchronous processing, while the EGRU is architected to leverage such hardware efficiently while maintaining competitive task performance. This implementation marks the first time a neuromorphic language model matches LSTMs, setting the stage for taking task performance to the level of large language models. We also demonstrate results on a gesture recognition task based on inputs from a DVS camera. Overall, our results showcase the feasibility of this neuro-inspired neural network in hardware, highlighting significant gains versus conventional hardware in energy efficiency for the common use case of single batch inference.
Activity Sparsity Complements Weight Sparsity for Efficient RNN Inference
Nov 13, 2023Artificial neural networks open up unprecedented machine learning capabilities at the cost of ever growing computational requirements. Sparsifying the parameters, often achieved through weight pruning, has been identified as a powerful technique to compress the number of model parameters and reduce the computational operations of neural networks. Yet, sparse activations, while omnipresent in both biological neural networks and deep learning systems, have not been fully utilized as a compression technique in deep learning. Moreover, the interaction between sparse activations and weight pruning is not fully understood. In this work, we demonstrate that activity sparsity can compose multiplicatively with parameter sparsity in a recurrent neural network model based on the GRU that is designed to be activity sparse. We achieve up to $20\times$ reduction of computation while maintaining perplexities below $60$ on the Penn Treebank language modeling task. This magnitude of reduction has not been achieved previously with solely sparsely connected LSTMs, and the language modeling performance of our model has not been achieved previously with any sparsely activated recurrent neural networks or spiking neural networks. Neuromorphic computing devices are especially good at taking advantage of the dynamic activity sparsity, and our results provide strong evidence that making deep learning models activity sparse and porting them to neuromorphic devices can be a viable strategy that does not compromise on task performance. Our results also drive further convergence of methods from deep learning and neuromorphic computing for efficient machine learning.