 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-space models can learn in-context by gradient descent
Oct 15, 2024Deep state-space models (Deep SSMs) have shown capabilities for in-context learning on autoregressive tasks, similar to transformers. However, the architectural requirements and mechanisms enabling this in recurrent networks remain unclear. This study demonstrates that state-space model architectures can perform gradient-based learning and use it for in-context learning. We prove that a single structured state-space model layer, augmented with local self-attention, can reproduce the outputs of an implicit linear model with least squares loss after one step of gradient descent. Our key insight is that the diagonal linear recurrent layer can act as a gradient accumulator, which can be `applied' to the parameters of the implicit regression model. We validate our construction by training randomly initialized augmented SSMs on simple linear regression tasks. The empirically optimized parameters match the theoretical ones, obtained analytically from the implicit model construction. Extensions to multi-step linear and non-linear regression yield consistent results. The constructed SSM encompasses features of modern deep state-space models, with the potential for scalable training and effectiveness even in general tasks. The theoretical construction elucidates the role of local self-attention and multiplicative interactions in recurrent architectures as the key ingredients for enabling the expressive power typical of foundation models.
Scalable Event-by-event Processing of Neuromorphic Sensory Signals With Deep State-Space Models
Apr 29, 2024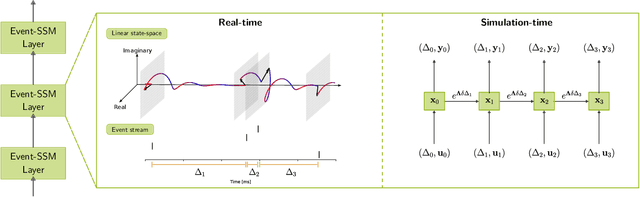
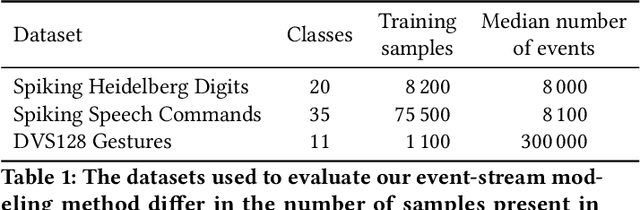
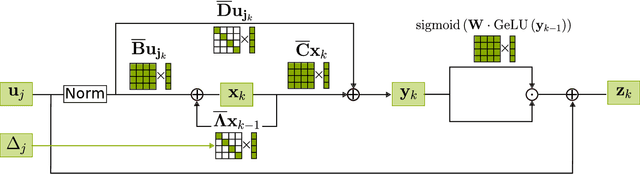

Event-based sensors are well suited for real-time processing due to their fast response times and encoding of the sensory data as successive temporal differences. These and other valuable properties, such as a high dynamic range, are suppressed when the data is converted to a frame-based format. However, most current methods either collapse events into frames or cannot scale up when processing the event data directly event-by-event. In this work, we address the key challenges of scaling up event-by-event modeling of the long event streams emitted by such sensors, which is a particularly relevant problem for neuromorphic computing. While prior methods can process up to a few thousand time steps, our model, based on modern recurrent deep state-space models, scales to event streams of millions of events for both training and inference.We leverage their stable parameterization for learning long-range dependencies, parallelizability along the sequence dimension, and their ability to integrate asynchronous events effectively to scale them up to long event streams.We further augment these with novel event-centric techniques enabling our model to match or beat the state-of-the-art performance on several event stream benchmarks. In the Spiking Speech Commands task, we improve state-of-the-art by a large margin of 6.6% to 87.1%. On the DVS128-Gestures dataset, we achieve competitive results without using frames or convolutional neural networks. Our work demonstrates, for the first time, that it is possible to use fully event-based processing with purely recurrent networks to achieve state-of-the-art task performance in several event-based benchmarks.