 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Length Generalization in Mamba via Image Reconstruction
Mar 12, 2026Mamba has attracted widespread interest as a general-purpose sequence model due to its low computational complexity and competitive performance relative to transformers. However, its performance can degrade when inference sequence lengths exceed those seen during training. We study this phenomenon using a controlled vision task in which Mamba reconstructs images from sequences of image patches. By analyzing reconstructions at different stages of sequence processing, we reveal that Mamba qualitatively adapts its behavior to the distribution of sequence lengths encountered during training, resulting in strategies that fail to generalize beyond this range. To support our analysis, we introduce a length-adaptive variant of Mamba that improves performance across training sequence lengths. Our results provide an intuitive perspective on length generalization in Mamba and suggest directions for improving the architecture.
Is Hierarchical Quantization Essential for Optimal Reconstruction?
Jan 29, 2026Vector-quantized variational autoencoders (VQ-VAEs) are central to models that rely on high reconstruction fidelity, from neural compression to generative pipelines. Hierarchical extensions, such as VQ-VAE2, are often credited with superior reconstruction performance because they split global and local features across multiple levels. However, since higher levels derive all their information from lower levels, they should not carry additional reconstructive content beyond what the lower-level already encodes. Combined with recent advances in training objectives and quantization mechanisms, this leads us to ask whether a single-level VQ-VAE, with matched representational budget and no codebook collapse, can equal the reconstruction fidelity of its hierarchical counterpart. Although the multi-scale structure of hierarchical models may improve perceptual quality in downstream tasks, the effect of hierarchy on reconstruction accuracy, isolated from codebook utilization and overall representational capacity, remains empirically underexamined. We revisit this question by comparing a two-level VQ-VAE and a capacity-matched single-level model on high-resolution ImageNet images. Consistent with prior observations, we confirm that inadequate codebook utilization limits single-level VQ-VAEs and that overly high-dimensional embeddings destabilize quantization and increase codebook collapse. We show that lightweight interventions such as initialization from data, periodic reset of inactive codebook vectors, and systematic tuning of codebook hyperparameters significantly reduce collapse. Our results demonstrate that when representational budgets are matched, and codebook collapse is mitigated, single-level VQ-VAEs can match the reconstruction fidelity of hierarchical variants, challenging the assumption that hierarchical quantization is inherently superior for high-quality reconstructions.
Putting the Iterative Training of Decision Trees to the Test on a Real-World Robotic Task
Dec 06, 2024



In previous research, we developed methods to train decision trees (DT) as agents for reinforcement learning tasks, based on deep reinforcement learning (DRL) networks. The samples from which the DTs are built, use the environment's state as features and the corresponding action as label. To solve the nontrivial task of selecting samples, which on one hand reflect the DRL agent's capabilities of choosing the right action but on the other hand also cover enough state space to generalize well, we developed an algorithm to iteratively train DTs. In this short paper, we apply this algorithm to a real-world implementation of a robotic task for the first time. Real-world tasks pose additional challenges compared to simulations, such as noise and delays. The task consists of a physical pendulum attached to a cart, which moves on a linear track. By movements to the left and to the right, the pendulum is to be swung in the upright position and balanced in the unstable equilibrium. Our results demonstrate the applicability of the algorithm to real-world tasks by generating a DT whose performance matches the performance of the DRL agent, while consisting of fewer parameters. This research could be a starting point for distilling DTs from DRL agents to obtain transparent, lightweight models for real-world reinforcement learning tasks.
What is the relationship between Slow Feature Analysis and the Successor Representation?
Sep 25, 2024


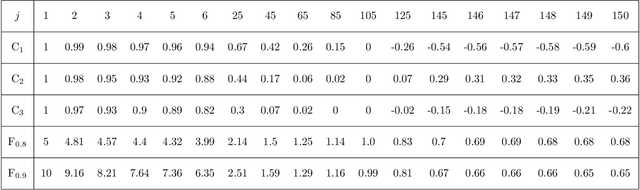
(This is a work in progress. Feedback is welcome) An analytical comparison is made between slow feature analysis (SFA) and the successor representation (SR). While SFA and the SR stem from distinct areas of machine learning, they share important properties, both in terms of their mathematics and the types of information they are sensitive to. This work studies their connection along these two axes. In particular, multiple variants of the SFA algorithm are explored analytically and then applied to the setting of an MDP, leading to a family of eigenvalue problems involving the SR and other related quantities. These resulting eigenvalue problems are then illustrated in the toy setting of a gridworld, where it is demonstrated that the place- and grid-like fields often associated to the SR can equally be generated using SFA.
Exploring the limits of Hierarchical World Models in Reinforcement Learning
Jun 01, 2024Hierarchical model-based reinforcement learning (HMBRL) aims to combine the benefits of better sample efficiency of model based reinforcement learning (MBRL) with the abstraction capability of hierarchical reinforcement learning (HRL) to solve complex tasks efficiently. While HMBRL has great potential, it still lacks wide adoption. In this work we describe a novel HMBRL framework and evaluate it thoroughly. To complement the multi-layered decision making idiom characteristic for HRL, we construct hierarchical world models that simulate environment dynamics at various levels of temporal abstraction. These models are used to train a stack of agents that communicate in a top-down manner by proposing goals to their subordinate agents. A significant focus of this study is the exploration of a static and environment agnostic temporal abstraction, which allows concurrent training of models and agents throughout the hierarchy. Unlike most goal-conditioned H(MB)RL approaches, it also leads to comparatively low dimensional abstract actions. Although our HMBRL approach did not outperform traditional methods in terms of final episode returns, it successfully facilitated decision making across two levels of abstraction using compact, low dimensional abstract actions. A central challenge in enhancing our method's performance, as uncovered through comprehensive experimentation, is model exploitation on the abstract level of our world model stack. We provide an in depth examination of this issue, discussing its implications for the field and suggesting directions for future research to overcome this challenge. By sharing these findings, we aim to contribute to the broader discourse on refining HMBRL methodologies and to assist in the development of more effective autonomous learning systems for complex decision-making environments.
ProtoP-OD: Explainable Object Detection with Prototypical Parts
Feb 29, 2024


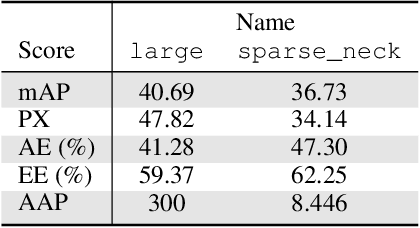
Interpretation and visualization of the behavior of detection transformers tends to highlight the locations in the image that the model attends to, but it provides limited insight into the \emph{semantics} that the model is focusing on. This paper introduces an extension to detection transformers that constructs prototypical local features and uses them in object detection. These custom features, which we call prototypical parts, are designed to be mutually exclusive and align with the classifications of the model. The proposed extension consists of a bottleneck module, the prototype neck, that computes a discretized representation of prototype activations and a new loss term that matches prototypes to object classes. This setup leads to interpretable representations in the prototype neck, allowing visual inspection of the image content perceived by the model and a better understanding of the model's reliability. We show experimentally that our method incurs only a limited performance penalty, and we provide examples that demonstrate the quality of the explanations provided by our method, which we argue outweighs the performance penalty.
Interpretable Brain-Inspired Representations Improve RL Performance on Visual Navigation Tasks
Feb 19, 2024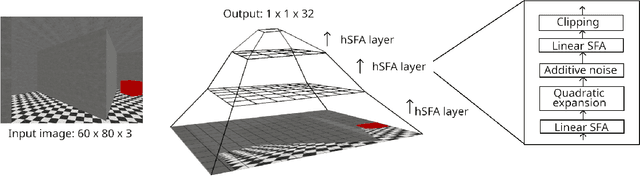

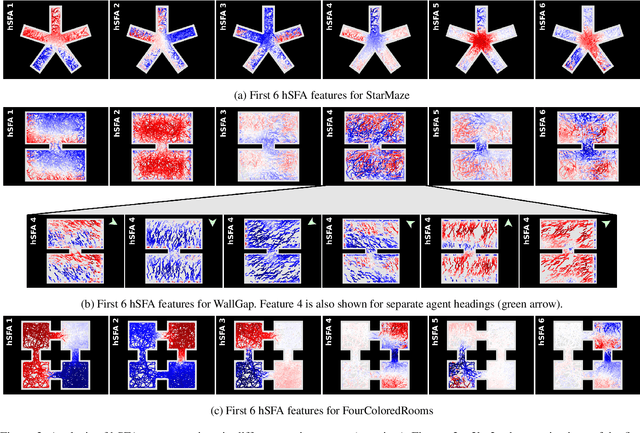
Visual navigation requires a whole range of capabilities. A crucial one of these is the ability of an agent to determine its own location and heading in an environment. Prior works commonly assume this information as given, or use methods which lack a suitable inductive bias and accumulate error over time. In this work, we show how the method of slow feature analysis (SFA), inspired by neuroscience research, overcomes both limitations by generating interpretable representations of visual data that encode location and heading of an agent. We employ SFA in a modern reinforcement learning context, analyse and compare representations and illustrate where hierarchical SFA can outperform other feature extractors on navigation tasks.
Classification and Reconstruction Processes in Deep Predictive Coding Networks: Antagonists or Allies?
Jan 17, 2024Predictive coding-inspired deep networks for visual computing integrate classification and reconstruction processes in shared intermediate layers. Although synergy between these processes is commonly assumed, it has yet to be convincingly demonstrated. In this study, we take a critical look at how classifying and reconstructing interact in deep learning architectures. Our approach utilizes a purposefully designed family of model architectures reminiscent of autoencoders, each equipped with an encoder, a decoder, and a classification head featuring varying modules and complexities. We meticulously analyze the extent to which classification- and reconstruction-driven information can seamlessly coexist within the shared latent layer of the model architectures. Our findings underscore a significant challenge: Classification-driven information diminishes reconstruction-driven information in intermediate layers' shared representations and vice versa. While expanding the shared representation's dimensions or increasing the network's complexity can alleviate this trade-off effect, our results challenge prevailing assumptions in predictive coding and offer guidance for future iterations of predictive coding concepts in deep networks.
Improving Reinforcement Learning Efficiency with Auxiliary Tasks in Non-Visual Environments: A Comparison
Oct 09, 2023Real-world reinforcement learning (RL) environments, whether in robotics or industrial settings, often involve non-visual observations and require not only efficient but also reliable and thus interpretable and flexible RL approaches. To improve efficiency, agents that perform state representation learning with auxiliary tasks have been widely studied in visual observation contexts. However, for real-world problems, dedicated representation learning modules that are decoupled from RL agents are more suited to meet requirements. This study compares common auxiliary tasks based on, to the best of our knowledge, the only decoupled representation learning method for low-dimensional non-visual observations. We evaluate potential improvements in sample efficiency and returns for environments ranging from a simple pendulum to a complex simulated robotics task. Our findings show that representation learning with auxiliary tasks only provides performance gains in sufficiently complex environments and that learning environment dynamics is preferable to predicting rewards. These insights can inform future development of interpretable representation learning approaches for non-visual observations and advance the use of RL solutions in real-world scenarios.
A Tutorial on the Spectral Theory of Markov Chains
Jul 05, 2022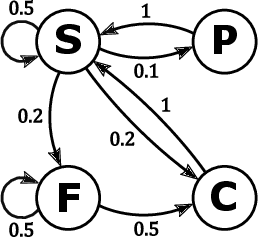

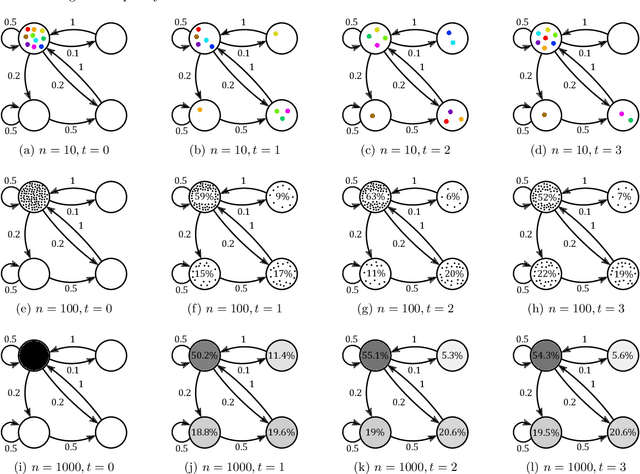

Markov chains are a class of probabilistic models that have achieved widespread application in the quantitative sciences. This is in part due to their versatility, but is compounded by the ease with which they can be probed analytically. This tutorial provides an in-depth introduction to Markov chains, and explores their connection to graphs and random walks. We utilize tools from linear algebra and graph theory to describe the transition matrices of different types of Markov chains, with a particular focus on exploring properties of the eigenvalues and eigenvectors corresponding to these matrices. The results presented are relevant to a number of methods in machine learning and data mining, which we describe at various stages. Rather than being a novel academic study in its own right, this text presents a collection of known results, together with some new concepts. Moreover, the tutorial focuses on offering intuition to readers rather than formal understanding, and only assumes basic exposure to concepts from linear algebra and probability theory. It is therefore accessible to students and researchers from a wide variety of disciplines.