 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePutting the Iterative Training of Decision Trees to the Test on a Real-World Robotic Task
Dec 06, 2024



In previous research, we developed methods to train decision trees (DT) as agents for reinforcement learning tasks, based on deep reinforcement learning (DRL) networks. The samples from which the DTs are built, use the environment's state as features and the corresponding action as label. To solve the nontrivial task of selecting samples, which on one hand reflect the DRL agent's capabilities of choosing the right action but on the other hand also cover enough state space to generalize well, we developed an algorithm to iteratively train DTs. In this short paper, we apply this algorithm to a real-world implementation of a robotic task for the first time. Real-world tasks pose additional challenges compared to simulations, such as noise and delays. The task consists of a physical pendulum attached to a cart, which moves on a linear track. By movements to the left and to the right, the pendulum is to be swung in the upright position and balanced in the unstable equilibrium. Our results demonstrate the applicability of the algorithm to real-world tasks by generating a DT whose performance matches the performance of the DRL agent, while consisting of fewer parameters. This research could be a starting point for distilling DTs from DRL agents to obtain transparent, lightweight models for real-world reinforcement learning tasks.
Interpretable Brain-Inspired Representations Improve RL Performance on Visual Navigation Tasks
Feb 19, 2024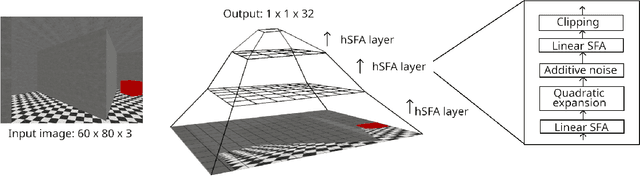

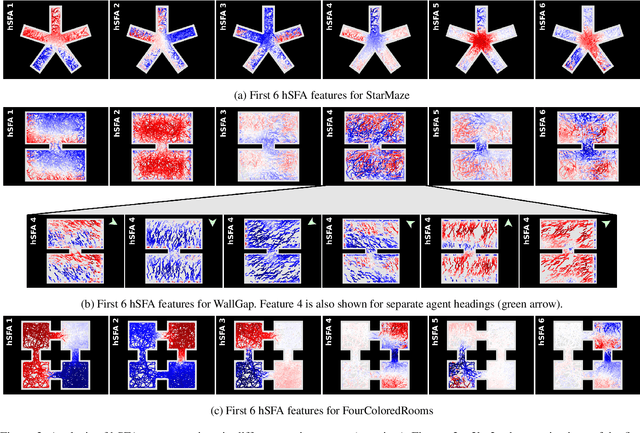
Visual navigation requires a whole range of capabilities. A crucial one of these is the ability of an agent to determine its own location and heading in an environment. Prior works commonly assume this information as given, or use methods which lack a suitable inductive bias and accumulate error over time. In this work, we show how the method of slow feature analysis (SFA), inspired by neuroscience research, overcomes both limitations by generating interpretable representations of visual data that encode location and heading of an agent. We employ SFA in a modern reinforcement learning context, analyse and compare representations and illustrate where hierarchical SFA can outperform other feature extractors on navigation tasks.
Benchmarks for Physical Reasoning AI
Dec 17, 2023



Physical reasoning is a crucial aspect in the development of general AI systems, given that human learning starts with interacting with the physical world before progressing to more complex concepts. Although researchers have studied and assessed the physical reasoning of AI approaches through various specific benchmarks, there is no comprehensive approach to evaluating and measuring progress. Therefore, we aim to offer an overview of existing benchmarks and their solution approaches and propose a unified perspective for measuring the physical reasoning capacity of AI systems. We select benchmarks that are designed to test algorithmic performance in physical reasoning tasks. While each of the selected benchmarks poses a unique challenge, their ensemble provides a comprehensive proving ground for an AI generalist agent with a measurable skill level for various physical reasoning concepts. This gives an advantage to such an ensemble of benchmarks over other holistic benchmarks that aim to simulate the real world by intertwining its complexity and many concepts. We group the presented set of physical reasoning benchmarks into subcategories so that more narrow generalist AI agents can be tested first on these groups.
Improving Reinforcement Learning Efficiency with Auxiliary Tasks in Non-Visual Environments: A Comparison
Oct 09, 2023Real-world reinforcement learning (RL) environments, whether in robotics or industrial settings, often involve non-visual observations and require not only efficient but also reliable and thus interpretable and flexible RL approaches. To improve efficiency, agents that perform state representation learning with auxiliary tasks have been widely studied in visual observation contexts. However, for real-world problems, dedicated representation learning modules that are decoupled from RL agents are more suited to meet requirements. This study compares common auxiliary tasks based on, to the best of our knowledge, the only decoupled representation learning method for low-dimensional non-visual observations. We evaluate potential improvements in sample efficiency and returns for environments ranging from a simple pendulum to a complex simulated robotics task. Our findings show that representation learning with auxiliary tasks only provides performance gains in sufficiently complex environments and that learning environment dynamics is preferable to predicting rewards. These insights can inform future development of interpretable representation learning approaches for non-visual observations and advance the use of RL solutions in real-world scenarios.