 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePutting the Iterative Training of Decision Trees to the Test on a Real-World Robotic Task
Dec 06, 2024



In previous research, we developed methods to train decision trees (DT) as agents for reinforcement learning tasks, based on deep reinforcement learning (DRL) networks. The samples from which the DTs are built, use the environment's state as features and the corresponding action as label. To solve the nontrivial task of selecting samples, which on one hand reflect the DRL agent's capabilities of choosing the right action but on the other hand also cover enough state space to generalize well, we developed an algorithm to iteratively train DTs. In this short paper, we apply this algorithm to a real-world implementation of a robotic task for the first time. Real-world tasks pose additional challenges compared to simulations, such as noise and delays. The task consists of a physical pendulum attached to a cart, which moves on a linear track. By movements to the left and to the right, the pendulum is to be swung in the upright position and balanced in the unstable equilibrium. Our results demonstrate the applicability of the algorithm to real-world tasks by generating a DT whose performance matches the performance of the DRL agent, while consisting of fewer parameters. This research could be a starting point for distilling DTs from DRL agents to obtain transparent, lightweight models for real-world reinforcement learning tasks.
ChatGPT Code Detection: Techniques for Uncovering the Source of Code
May 24, 2024



In recent times, large language models (LLMs) have made significant strides in generating computer code, blurring the lines between code created by humans and code produced by artificial intelligence (AI). As these technologies evolve rapidly, it is crucial to explore how they influence code generation, especially given the risk of misuse in areas like higher education. This paper explores this issue by using advanced classification techniques to differentiate between code written by humans and that generated by ChatGPT, a type of LLM. We employ a new approach that combines powerful embedding features (black-box) with supervised learning algorithms - including Deep Neural Networks, Random Forests, and Extreme Gradient Boosting - to achieve this differentiation with an impressive accuracy of 98%. For the successful combinations, we also examine their model calibration, showing that some of the models are extremely well calibrated. Additionally, we present white-box features and an interpretable Bayes classifier to elucidate critical differences between the code sources, enhancing the explainability and transparency of our approach. Both approaches work well but provide at most 85-88% accuracy. We also show that untrained humans solve the same task not better than random guessing. This study is crucial in understanding and mitigating the potential risks associated with using AI in code generation, particularly in the context of higher education, software development, and competitive programming.
Interpretable Brain-Inspired Representations Improve RL Performance on Visual Navigation Tasks
Feb 19, 2024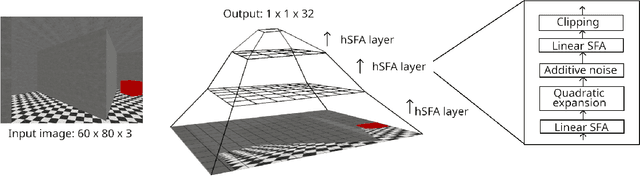

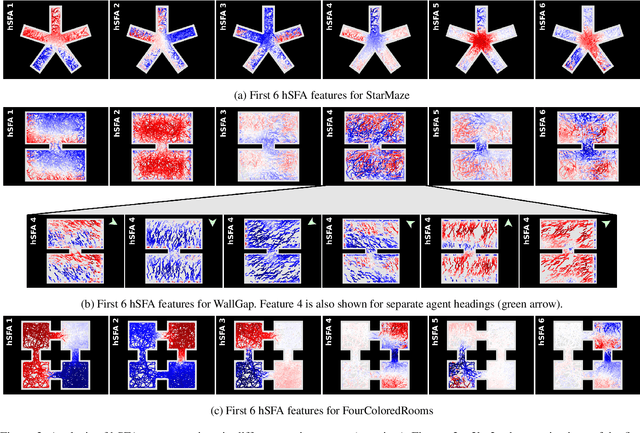
Visual navigation requires a whole range of capabilities. A crucial one of these is the ability of an agent to determine its own location and heading in an environment. Prior works commonly assume this information as given, or use methods which lack a suitable inductive bias and accumulate error over time. In this work, we show how the method of slow feature analysis (SFA), inspired by neuroscience research, overcomes both limitations by generating interpretable representations of visual data that encode location and heading of an agent. We employ SFA in a modern reinforcement learning context, analyse and compare representations and illustrate where hierarchical SFA can outperform other feature extractors on navigation tasks.
Improving Reinforcement Learning Efficiency with Auxiliary Tasks in Non-Visual Environments: A Comparison
Oct 09, 2023Real-world reinforcement learning (RL) environments, whether in robotics or industrial settings, often involve non-visual observations and require not only efficient but also reliable and thus interpretable and flexible RL approaches. To improve efficiency, agents that perform state representation learning with auxiliary tasks have been widely studied in visual observation contexts. However, for real-world problems, dedicated representation learning modules that are decoupled from RL agents are more suited to meet requirements. This study compares common auxiliary tasks based on, to the best of our knowledge, the only decoupled representation learning method for low-dimensional non-visual observations. We evaluate potential improvements in sample efficiency and returns for environments ranging from a simple pendulum to a complex simulated robotics task. Our findings show that representation learning with auxiliary tasks only provides performance gains in sufficiently complex environments and that learning environment dynamics is preferable to predicting rewards. These insights can inform future development of interpretable representation learning approaches for non-visual observations and advance the use of RL solutions in real-world scenarios.
Towards Learning Rubik's Cube with N-tuple-based Reinforcement Learning
Jan 28, 2023This work describes in detail how to learn and solve the Rubik's cube game (or puzzle) in the General Board Game (GBG) learning and playing framework. We cover the cube sizes 2x2x2 and 3x3x3. We describe in detail the cube's state representation, how to transform it with twists, whole-cube rotations and color transformations and explain the use of symmetries in Rubik's cube. Next, we discuss different n-tuple representations for the cube, how we train the agents by reinforcement learning and how we improve the trained agents during evaluation by MCTS wrapping. We present results for agents that learn Rubik's cube from scratch, with and without MCTS wrapping, with and without symmetries and show that both, MCTS wrapping and symmetries, increase computational costs, but lead at the same time to much better results. We can solve the 2x2x2 cube completely, and the 3x3x3 cube in the majority of the cases for scrambled cubes up to p = 15 (QTM). We cannot yet reliably solve 3x3x3 cubes with more than 15 scrambling twists. Although our computational costs are higher with MCTS wrapping and with symmetries than without, they are still considerably lower than in the approaches of McAleer et al. (2018, 2019) and Agostinelli et al. (2019) who provide the best Rubik's cube learning agents so far.
AlphaZero-Inspired General Board Game Learning and Playing
Apr 28, 2022
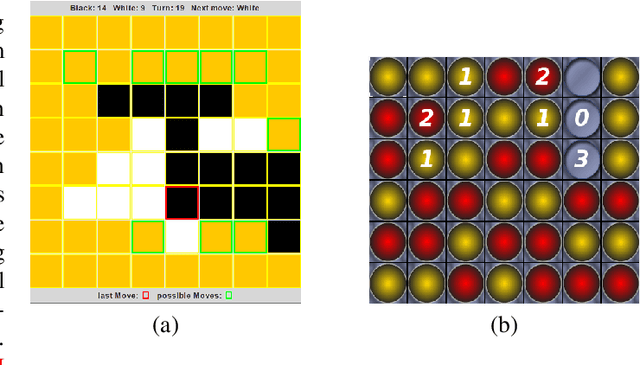
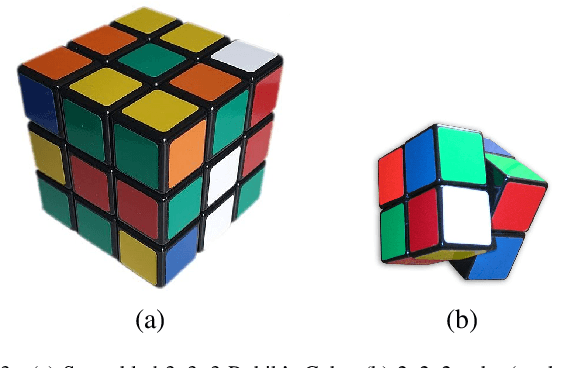
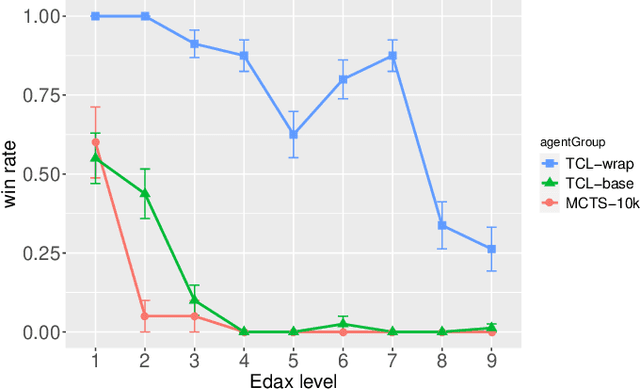
Recently, the seminal algorithms AlphaGo and AlphaZero have started a new era in game learning and deep reinforcement learning. While the achievements of AlphaGo and AlphaZero - playing Go and other complex games at super human level - are truly impressive, these architectures have the drawback that they are very complex and require high computational resources. Many researchers are looking for methods that are similar to AlphaZero, but have lower computational demands and are thus more easily reproducible. In this paper, we pick an important element of AlphaZero - the Monte Carlo Tree Search (MCTS) planning stage - and combine it with reinforcement learning (RL) agents. We wrap MCTS for the first time around RL n-tuple networks to create versatile agents that keep at the same time the computational demands low. We apply this new architecture to several complex games (Othello, ConnectFour, Rubik's Cube) and show the advantages achieved with this AlphaZero-inspired MCTS wrapper. In particular, we present results that this AlphaZero-inspired agent is the first one trained on standard hardware (no GPU or TPU) to beat the very strong Othello program Edax up to and including level 7 (where most other algorithms could only defeat Edax up to level 2).
Final Adaptation Reinforcement Learning for N-Player Games
Nov 29, 2021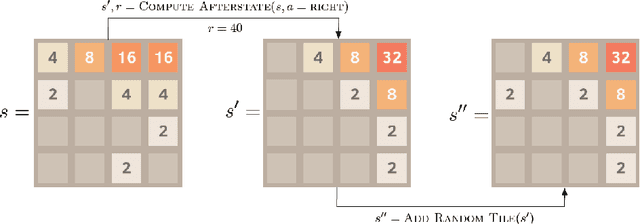
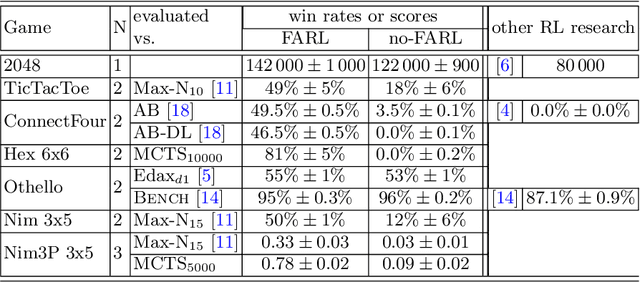
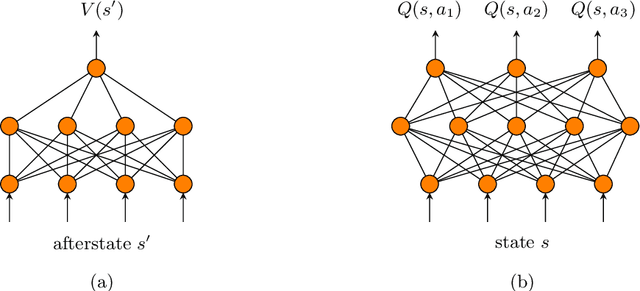
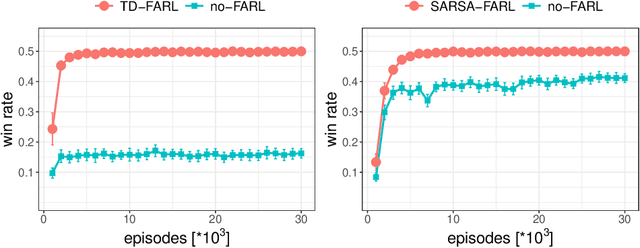
This paper covers n-tuple-based reinforcement learning (RL) algorithms for games. We present new algorithms for TD-, SARSA- and Q-learning which work seamlessly on various games with arbitrary number of players. This is achieved by taking a player-centered view where each player propagates his/her rewards back to previous rounds. We add a new element called Final Adaptation RL (FARL) to all these algorithms. Our main contribution is that FARL is a vitally important ingredient to achieve success with the player-centered view in various games. We report results on seven board games with 1, 2 and 3 players, including Othello, ConnectFour and Hex. In most cases it is found that FARL is important to learn a near-perfect playing strategy. All algorithms are available in the GBG framework on GitHub.
General Board Game Playing for Education and Research in Generic AI Game Learning
Jul 11, 2019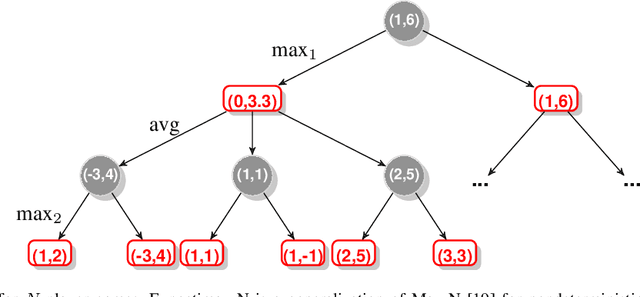
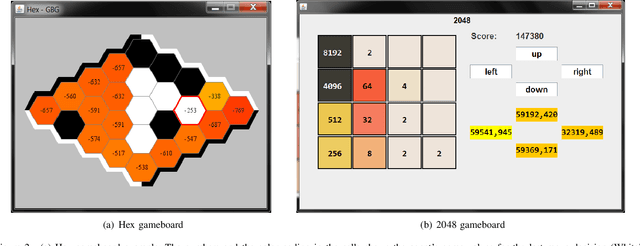
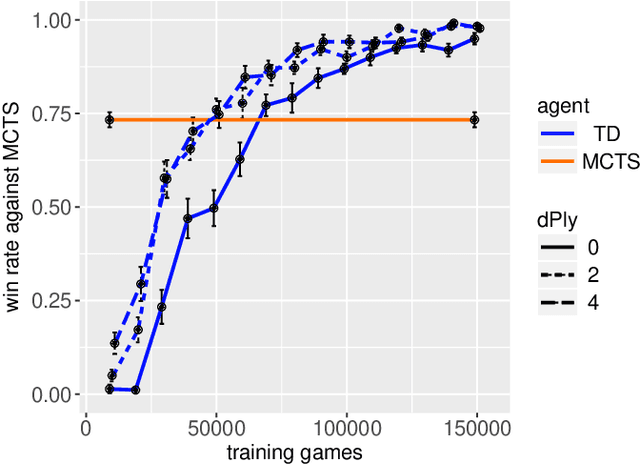

We present a new general board game (GBG) playing and learning framework. GBG defines the common interfaces for board games, game states and their AI agents. It allows one to run competitions of different agents on different games. It standardizes those parts of board game playing and learning that otherwise would be tedious and repetitive parts in coding. GBG is suitable for arbitrary 1-, 2-, ..., N-player board games. It makes a generic TD($\lambda$)-n-tuple agent for the first time available to arbitrary games. On various games, TD($\lambda$)-n-tuple is found to be superior to other generic agents like MCTS. GBG aims at the educational perspective, where it helps students to start faster in the area of game learning. GBG aims as well at the research perspective by collecting a growing set of games and AI agents to assess their strengths and generalization capabilities in meaningful competitions. Initial successful educational and research results are reported.
SACOBRA with Online Whitening for Solving Optimization Problems with High Conditioning
Apr 17, 2019

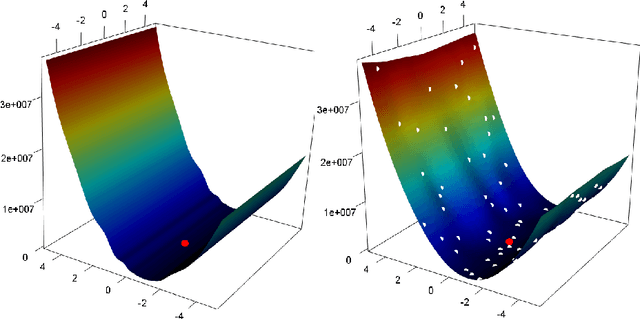
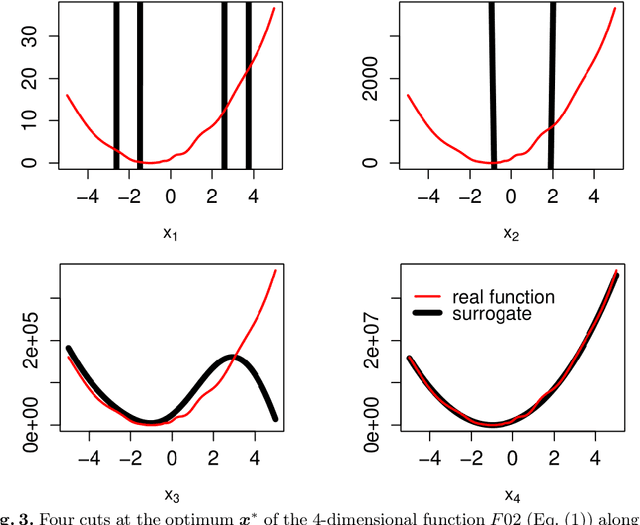
Real-world optimization problems often have expensive objective functions in terms of cost and time. It is desirable to find near-optimal solutions with very few function evaluations. Surrogate-assisted optimizers tend to reduce the required number of function evaluations by replacing the real function with an efficient mathematical model built on few evaluated points. Problems with a high condition number are a challenge for many surrogate-assisted optimizers including SACOBRA. To address such problems we propose a new online whitening operating in the black-box optimization paradigm. We show on a set of high-conditioning functions that online whitening tackles SACOBRA's early stagnation issue and reduces the optimization error by a factor between 10 to 1e12 as compared to the plain SACOBRA, though it imposes many extra function evaluations. Covariance matrix adaptation evolution strategy (CMA-ES) has for very high numbers of function evaluations even lower errors, whereas SACOBRA performs better in the expensive setting (less than 1e03 function evaluations). If we count all parallelizable function evaluations (population evaluation in CMA-ES, online whitening in our approach) as one iteration, then both algorithms have comparable strength even on the long run. This holds for problems with dimension D <= 20.
Illumination-invariant image mosaic calculation based on logarithmic search
Mar 21, 2016
This technical report describes an improved image mosaicking algorithm. It is based on Jain's logarithmic search algorithm [Jain 1981] which is coupled to the method of Kourogi (1999} for matching images in a video sequence. Logarithmic search has a better invariance against illumination changes than the original optical-flow-based method of Kourogi.