 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTREAM: A Universal State-Space Model for Sparse Geometric Data
Nov 19, 2024Handling sparse and unstructured geometric data, such as point clouds or event-based vision, is a pressing challenge in the field of machine vision. Recently, sequence models such as Transformers and state-space models entered the domain of geometric data. These methods require specialized preprocessing to create a sequential view of a set of points. Furthermore, prior works involving sequence models iterate geometric data with either uniform or learned step sizes, implicitly relying on the model to infer the underlying geometric structure. In this work, we propose to encode geometric structure explicitly into the parameterization of a state-space model. State-space models are based on linear dynamics governed by a one-dimensional variable such as time or a spatial coordinate. We exploit this dynamic variable to inject relative differences of coordinates into the step size of the state-space model. The resulting geometric operation computes interactions between all pairs of N points in O(N) steps. Our model deploys the Mamba selective state-space model with a modified CUDA kernel to efficiently map sparse geometric data to modern hardware. The resulting sequence model, which we call STREAM, achieves competitive results on a range of benchmarks from point-cloud classification to event-based vision and audio classification. STREAM demonstrates a powerful inductive bias for sparse geometric data by improving the PointMamba baseline when trained from scratch on the ModelNet40 and ScanObjectNN point cloud analysis datasets. It further achieves, for the first time, 100% test accuracy on all 11 classes of the DVS128 Gestures dataset.
Weight Sparsity Complements Activity Sparsity in Neuromorphic Language Models
May 01, 2024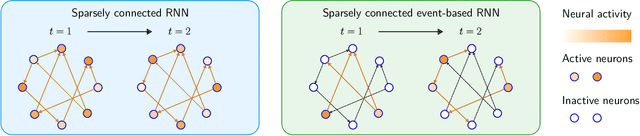
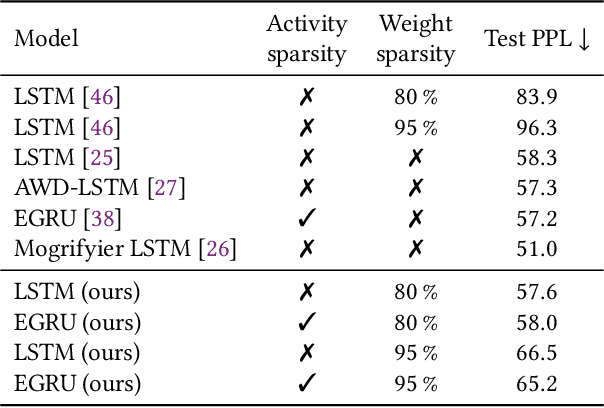
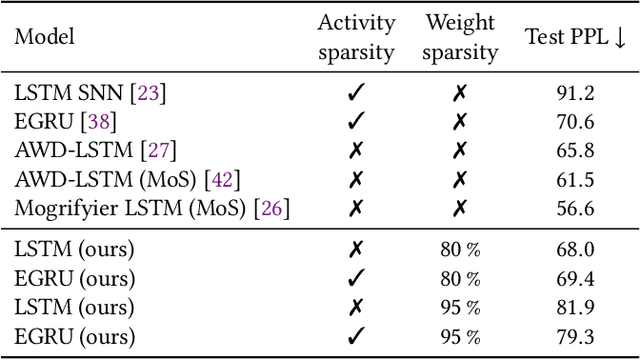
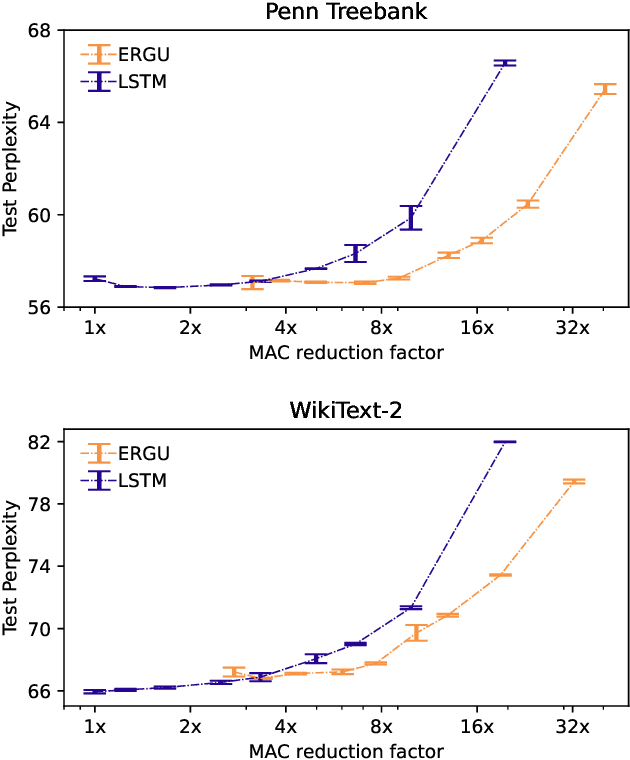
Activity and parameter sparsity are two standard methods of making neural networks computationally more efficient. Event-based architectures such as spiking neural networks (SNNs) naturally exhibit activity sparsity, and many methods exist to sparsify their connectivity by pruning weights. While the effect of weight pruning on feed-forward SNNs has been previously studied for computer vision tasks, the effects of pruning for complex sequence tasks like language modeling are less well studied since SNNs have traditionally struggled to achieve meaningful performance on these tasks. Using a recently published SNN-like architecture that works well on small-scale language modeling, we study the effects of weight pruning when combined with activity sparsity. Specifically, we study the trade-off between the multiplicative efficiency gains the combination affords and its effect on task performance for language modeling. To dissect the effects of the two sparsities, we conduct a comparative analysis between densely activated models and sparsely activated event-based models across varying degrees of connectivity sparsity. We demonstrate that sparse activity and sparse connectivity complement each other without a proportional drop in task performance for an event-based neural network trained on the Penn Treebank and WikiText-2 language modeling datasets. Our results suggest sparsely connected event-based neural networks are promising candidates for effective and efficient sequence modeling.
SpiNNaker2: A Large-Scale Neuromorphic System for Event-Based and Asynchronous Machine Learning
Jan 09, 2024The joint progress of artificial neural networks (ANNs) and domain specific hardware accelerators such as GPUs and TPUs took over many domains of machine learning research. This development is accompanied by a rapid growth of the required computational demands for larger models and more data. Concurrently, emerging properties of foundation models such as in-context learning drive new opportunities for machine learning applications. However, the computational cost of such applications is a limiting factor of the technology in data centers, and more importantly in mobile devices and edge systems. To mediate the energy footprint and non-trivial latency of contemporary systems, neuromorphic computing systems deeply integrate computational principles of neurobiological systems by leveraging low-power analog and digital technologies. SpiNNaker2 is a digital neuromorphic chip developed for scalable machine learning. The event-based and asynchronous design of SpiNNaker2 allows the composition of large-scale systems involving thousands of chips. This work features the operating principles of SpiNNaker2 systems, outlining the prototype of novel machine learning applications. These applications range from ANNs over bio-inspired spiking neural networks to generalized event-based neural networks. With the successful development and deployment of SpiNNaker2, we aim to facilitate the advancement of event-based and asynchronous algorithms for future generations of machine learning systems.
Language Modeling on a SpiNNaker 2 Neuromorphic Chip
Dec 14, 2023



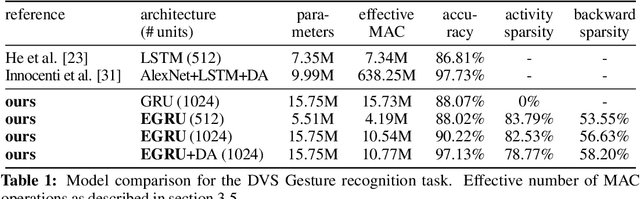
As large language models continue to scale in size rapidly, so too does the computational power required to run them. Event-based networks on neuromorphic devices offer a potential way to reduce energy consumption for inference significantly. However, to date, most event-based networks that can run on neuromorphic hardware, including spiking neural networks (SNNs), have not achieved task performance even on par with LSTM models for language modeling. As a result, language modeling on neuromorphic devices has seemed a distant prospect. In this work, we demonstrate the first-ever implementation of a language model on a neuromorphic device - specifically the SpiNNaker 2 chip - based on a recently published event-based architecture called the EGRU. SpiNNaker 2 is a many-core neuromorphic chip designed for large-scale asynchronous processing, while the EGRU is architected to leverage such hardware efficiently while maintaining competitive task performance. This implementation marks the first time a neuromorphic language model matches LSTMs, setting the stage for taking task performance to the level of large language models. We also demonstrate results on a gesture recognition task based on inputs from a DVS camera. Overall, our results showcase the feasibility of this neuro-inspired neural network in hardware, highlighting significant gains versus conventional hardware in energy efficiency for the common use case of single batch inference.
Activity Sparsity Complements Weight Sparsity for Efficient RNN Inference
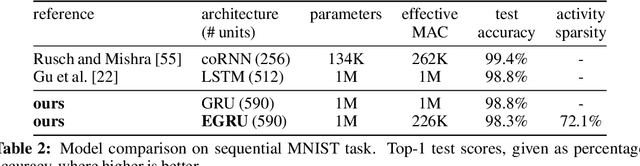
Nov 13, 2023Artificial neural networks open up unprecedented machine learning capabilities at the cost of ever growing computational requirements. Sparsifying the parameters, often achieved through weight pruning, has been identified as a powerful technique to compress the number of model parameters and reduce the computational operations of neural networks. Yet, sparse activations, while omnipresent in both biological neural networks and deep learning systems, have not been fully utilized as a compression technique in deep learning. Moreover, the interaction between sparse activations and weight pruning is not fully understood. In this work, we demonstrate that activity sparsity can compose multiplicatively with parameter sparsity in a recurrent neural network model based on the GRU that is designed to be activity sparse. We achieve up to $20\times$ reduction of computation while maintaining perplexities below $60$ on the Penn Treebank language modeling task. This magnitude of reduction has not been achieved previously with solely sparsely connected LSTMs, and the language modeling performance of our model has not been achieved previously with any sparsely activated recurrent neural networks or spiking neural networks. Neuromorphic computing devices are especially good at taking advantage of the dynamic activity sparsity, and our results provide strong evidence that making deep learning models activity sparse and porting them to neuromorphic devices can be a viable strategy that does not compromise on task performance. Our results also drive further convergence of methods from deep learning and neuromorphic computing for efficient machine learning.
Block-local learning with probabilistic latent representations
May 24, 2023



The ubiquitous backpropagation algorithm requires sequential updates across blocks of a network, introducing a locking problem. Moreover, backpropagation relies on the transpose of weight matrices to calculate updates, introducing a weight transport problem across blocks. Both these issues prevent efficient parallelisation and horizontal scaling of models across devices. We propose a new method that introduces a twin network that propagates information backwards from the targets to the input to provide auxiliary local losses. Forward and backward propagation can work in parallel and with different sets of weights, addressing the problems of weight transport and locking. Our approach derives from a statistical interpretation of end-to-end training which treats activations of network layers as parameters of probability distributions. The resulting learning framework uses these parameters locally to assess the matching between forward and backward information. Error backpropagation is then performed locally within each block, leading to `block-local' learning. Several previously proposed alternatives to error backpropagation emerge as special cases of our model. We present results on various tasks and architectures, including transformers, demonstrating state-of-the-art performance using block-local learning. These results provide a new principled framework to train very large networks in a distributed setting and can also be applied in neuromorphic systems.
EGRU: Event-based GRU for activity-sparse inference and learning
Jun 13, 2022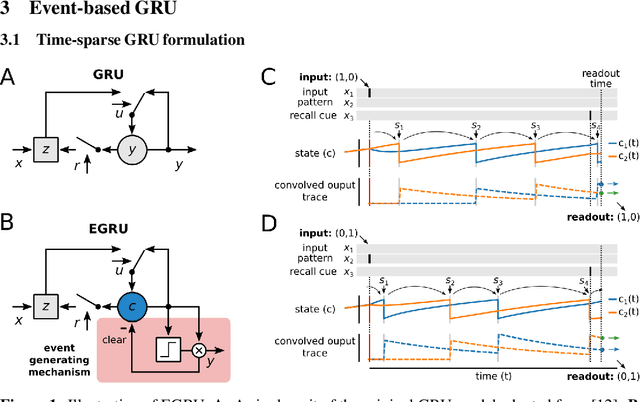
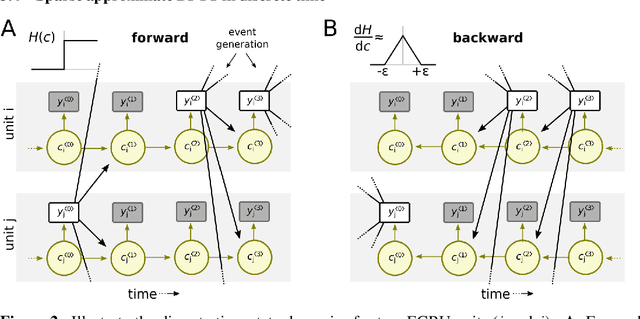
The scalability of recurrent neural networks (RNNs) is hindered by the sequential dependence of each time step's computation on the previous time step's output. Therefore, one way to speed up and scale RNNs is to reduce the computation required at each time step independent of model size and task. In this paper, we propose a model that reformulates Gated Recurrent Units (GRU) as an event-based activity-sparse model that we call the Event-based GRU (EGRU), where units compute updates only on receipt of input events (event-based) from other units. When combined with having only a small fraction of the units active at a time (activity-sparse), this model has the potential to be vastly more compute efficient than current RNNs. Notably, activity-sparsity in our model also translates into sparse parameter updates during gradient descent, extending this compute efficiency to the training phase. We show that the EGRU demonstrates competitive performance compared to state-of-the-art recurrent network models in real-world tasks, including language modeling while maintaining high activity sparsity naturally during inference and training. This sets the stage for the next generation of recurrent networks that are scalable and more suitable for novel neuromorphic hardware.