 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Representation Matters: Human-like Sketches in One-shot Drawing Tasks
Jun 10, 2024Humans can effortlessly draw new categories from a single exemplar, a feat that has long posed a challenge for generative models. However, this gap has started to close with recent advances in diffusion models. This one-shot drawing task requires powerful inductive biases that have not been systematically investigated. Here, we study how different inductive biases shape the latent space of Latent Diffusion Models (LDMs). Along with standard LDM regularizers (KL and vector quantization), we explore supervised regularizations (including classification and prototype-based representation) and contrastive inductive biases (using SimCLR and redundancy reduction objectives). We demonstrate that LDMs with redundancy reduction and prototype-based regularizations produce near-human-like drawings (regarding both samples' recognizability and originality) -- better mimicking human perception (as evaluated psychophysically). Overall, our results suggest that the gap between humans and machines in one-shot drawings is almost closed.
Weight Sparsity Complements Activity Sparsity in Neuromorphic Language Models
May 01, 2024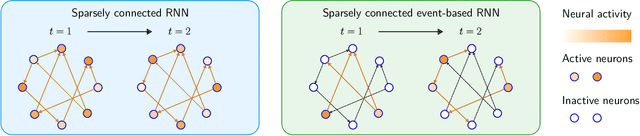
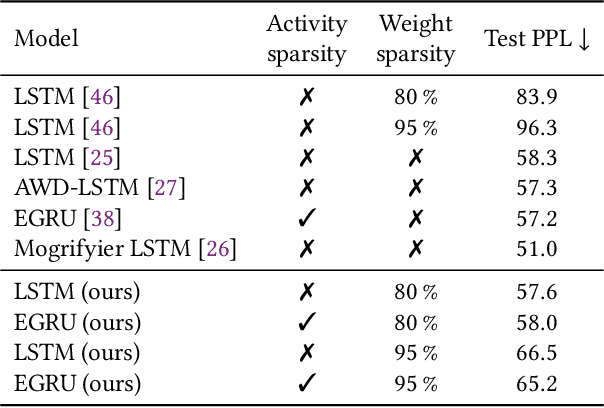
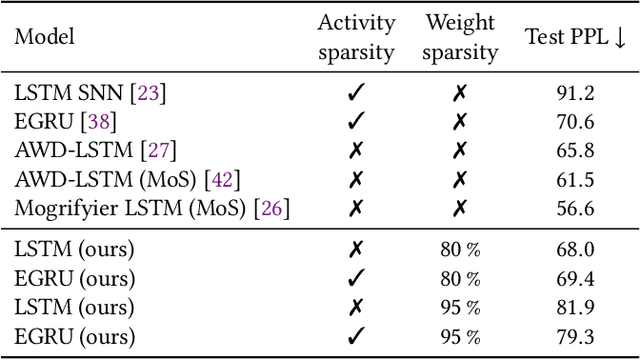
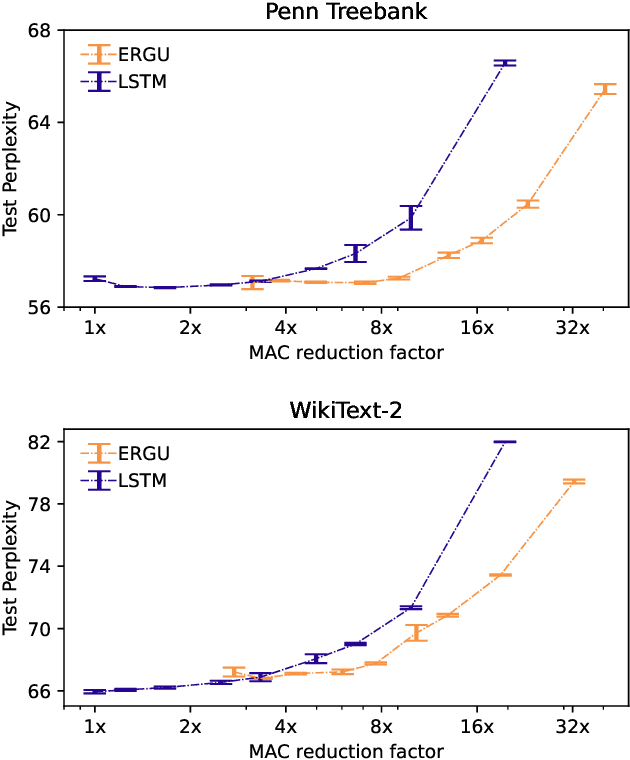
Activity and parameter sparsity are two standard methods of making neural networks computationally more efficient. Event-based architectures such as spiking neural networks (SNNs) naturally exhibit activity sparsity, and many methods exist to sparsify their connectivity by pruning weights. While the effect of weight pruning on feed-forward SNNs has been previously studied for computer vision tasks, the effects of pruning for complex sequence tasks like language modeling are less well studied since SNNs have traditionally struggled to achieve meaningful performance on these tasks. Using a recently published SNN-like architecture that works well on small-scale language modeling, we study the effects of weight pruning when combined with activity sparsity. Specifically, we study the trade-off between the multiplicative efficiency gains the combination affords and its effect on task performance for language modeling. To dissect the effects of the two sparsities, we conduct a comparative analysis between densely activated models and sparsely activated event-based models across varying degrees of connectivity sparsity. We demonstrate that sparse activity and sparse connectivity complement each other without a proportional drop in task performance for an event-based neural network trained on the Penn Treebank and WikiText-2 language modeling datasets. Our results suggest sparsely connected event-based neural networks are promising candidates for effective and efficient sequence modeling.
Language Modeling on a SpiNNaker 2 Neuromorphic Chip
Dec 14, 2023



As large language models continue to scale in size rapidly, so too does the computational power required to run them. Event-based networks on neuromorphic devices offer a potential way to reduce energy consumption for inference significantly. However, to date, most event-based networks that can run on neuromorphic hardware, including spiking neural networks (SNNs), have not achieved task performance even on par with LSTM models for language modeling. As a result, language modeling on neuromorphic devices has seemed a distant prospect. In this work, we demonstrate the first-ever implementation of a language model on a neuromorphic device - specifically the SpiNNaker 2 chip - based on a recently published event-based architecture called the EGRU. SpiNNaker 2 is a many-core neuromorphic chip designed for large-scale asynchronous processing, while the EGRU is architected to leverage such hardware efficiently while maintaining competitive task performance. This implementation marks the first time a neuromorphic language model matches LSTMs, setting the stage for taking task performance to the level of large language models. We also demonstrate results on a gesture recognition task based on inputs from a DVS camera. Overall, our results showcase the feasibility of this neuro-inspired neural network in hardware, highlighting significant gains versus conventional hardware in energy efficiency for the common use case of single batch inference.
Activity Sparsity Complements Weight Sparsity for Efficient RNN Inference
Nov 13, 2023Artificial neural networks open up unprecedented machine learning capabilities at the cost of ever growing computational requirements. Sparsifying the parameters, often achieved through weight pruning, has been identified as a powerful technique to compress the number of model parameters and reduce the computational operations of neural networks. Yet, sparse activations, while omnipresent in both biological neural networks and deep learning systems, have not been fully utilized as a compression technique in deep learning. Moreover, the interaction between sparse activations and weight pruning is not fully understood. In this work, we demonstrate that activity sparsity can compose multiplicatively with parameter sparsity in a recurrent neural network model based on the GRU that is designed to be activity sparse. We achieve up to $20\times$ reduction of computation while maintaining perplexities below $60$ on the Penn Treebank language modeling task. This magnitude of reduction has not been achieved previously with solely sparsely connected LSTMs, and the language modeling performance of our model has not been achieved previously with any sparsely activated recurrent neural networks or spiking neural networks. Neuromorphic computing devices are especially good at taking advantage of the dynamic activity sparsity, and our results provide strong evidence that making deep learning models activity sparse and porting them to neuromorphic devices can be a viable strategy that does not compromise on task performance. Our results also drive further convergence of methods from deep learning and neuromorphic computing for efficient machine learning.
Diffusion Models as Artists: Are we Closing the Gap between Humans and Machines?
Jan 27, 2023



An important milestone for AI is the development of algorithms that can produce drawings that are indistinguishable from those of humans. Here, we adapt the 'diversity vs. recognizability' scoring framework from Boutin et al, 2022 and find that one-shot diffusion models have indeed started to close the gap between humans and machines. However, using a finer-grained measure of the originality of individual samples, we show that strengthening the guidance of diffusion models helps improve the humanness of their drawings, but they still fall short of approximating the originality and recognizability of human drawings. Comparing human category diagnostic features, collected through an online psychophysics experiment, against those derived from diffusion models reveals that humans rely on fewer and more localized features. Overall, our study suggests that diffusion models have significantly helped improve the quality of machine-generated drawings; however, a gap between humans and machines remains -- in part explainable by discrepancies in visual strategies.