 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 3D-PC: a benchmark for visual perspective taking in humans and machines
Jun 06, 2024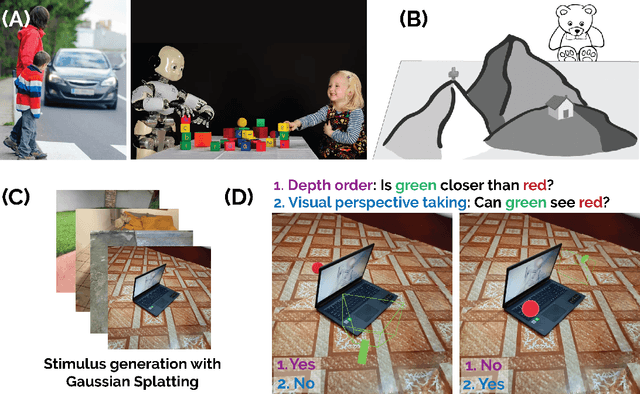


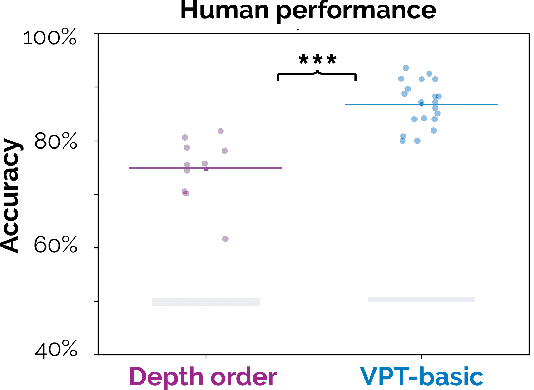
Visual perspective taking (VPT) is the ability to perceive and reason about the perspectives of others. It is an essential feature of human intelligence, which develops over the first decade of life and requires an ability to process the 3D structure of visual scenes. A growing number of reports have indicated that deep neural networks (DNNs) become capable of analyzing 3D scenes after training on large image datasets. We investigated if this emergent ability for 3D analysis in DNNs is sufficient for VPT with the 3D perception challenge (3D-PC): a novel benchmark for 3D perception in humans and DNNs. The 3D-PC is comprised of three 3D-analysis tasks posed within natural scene images: 1. a simple test of object depth order, 2. a basic VPT task (VPT-basic), and 3. another version of VPT (VPT-Strategy) designed to limit the effectiveness of "shortcut" visual strategies. We tested human participants (N=33) and linearly probed or text-prompted over 300 DNNs on the challenge and found that nearly all of the DNNs approached or exceeded human accuracy in analyzing object depth order. Surprisingly, DNN accuracy on this task correlated with their object recognition performance. In contrast, there was an extraordinary gap between DNNs and humans on VPT-basic. Humans were nearly perfect, whereas most DNNs were near chance. Fine-tuning DNNs on VPT-basic brought them close to human performance, but they, unlike humans, dropped back to chance when tested on VPT-perturb. Our challenge demonstrates that the training routines and architectures of today's DNNs are well-suited for learning basic 3D properties of scenes and objects but are ill-suited for reasoning about these properties like humans do. We release our 3D-PC datasets and code to help bridge this gap in 3D perception between humans and machines.
Diffusion Models as Artists: Are we Closing the Gap between Humans and Machines?
Jan 27, 2023



An important milestone for AI is the development of algorithms that can produce drawings that are indistinguishable from those of humans. Here, we adapt the 'diversity vs. recognizability' scoring framework from Boutin et al, 2022 and find that one-shot diffusion models have indeed started to close the gap between humans and machines. However, using a finer-grained measure of the originality of individual samples, we show that strengthening the guidance of diffusion models helps improve the humanness of their drawings, but they still fall short of approximating the originality and recognizability of human drawings. Comparing human category diagnostic features, collected through an online psychophysics experiment, against those derived from diffusion models reveals that humans rely on fewer and more localized features. Overall, our study suggests that diffusion models have significantly helped improve the quality of machine-generated drawings; however, a gap between humans and machines remains -- in part explainable by discrepancies in visual strategies.
Digital Image Forensics using Deep Learning
Oct 14, 2022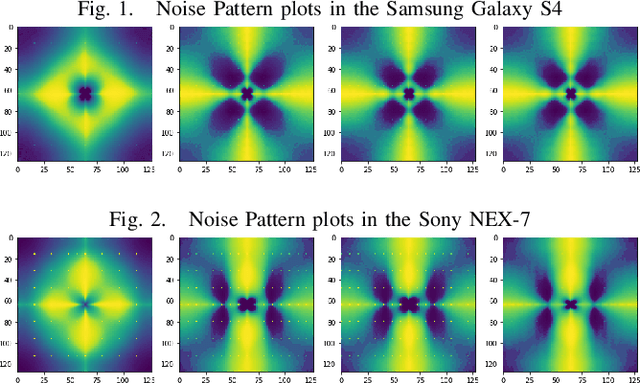
During the investigation of criminal activity when evidence is available, the issue at hand is determining the credibility of the video and ascertaining that the video is real. Today, one way to authenticate the footage is to identify the camera that was used to capture the image or video in question. While a very common way to do this is by using image meta-data, this data can easily be falsified by changing the video content or even splicing together content from two different cameras. Given the multitude of solutions proposed to this problem, it is yet to be sufficiently solved. The aim of our project is to build an algorithm that identifies which camera was used to capture an image using traces of information left intrinsically in the image, using filters, followed by a deep neural network on these filters. Solving this problem would have a big impact on the verification of evidence used in criminal and civil trials and even news reporting.
Real-Time Automated Answer Scoring
Oct 13, 2022
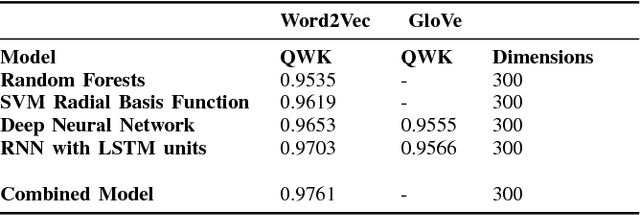
In recent years, the role of big data analytics has exponentially grown and is now slowly making its way into the education industry. Several attempts are being made in this sphere in order to improve the quality of education being provided to students and while many collaborations have been carried out before, automated scoring of answers has been explored to a rather limited extent. One of the biggest hurdles to choosing constructed-response assessments over multiple-choice assessments is the effort and large cost that comes with their evaluation and this is precisely the issue that this project aims to solve. The aim is to accept raw-input from the student in the form of their answer, preprocess the answer, and automatically score the answer. In addition, we have made this a real-time system that captures "snapshots" of the writer's progress with respect to the answer, allowing us to unearth trends with respect to the way a student thinks, and how the student has arrived at their final answer.
* This paper was originally written in mid 2018
A Concise Introduction to Reinforcement Learning in Robotics
Oct 13, 2022

One of the biggest hurdles robotics faces is the facet of sophisticated and hard-to-engineer behaviors. Reinforcement learning offers a set of tools, and a framework to address this problem. In parallel, the misgivings of robotics offer a solid testing ground and evaluation metric for advancements in reinforcement learning. The two disciplines go hand-in-hand, much like the fields of Mathematics and Physics. By means of this survey paper, we aim to invigorate links between the research communities of the two disciplines by focusing on the work done in reinforcement learning for locomotive and control aspects of robotics. Additionally, we aim to highlight not only the notable successes but also the key challenges of the application of Reinforcement Learning in Robotics. This paper aims to serve as a reference guide for researchers in reinforcement learning applied to the field of robotics. The literature survey is at a fairly introductory level, aimed at aspiring researchers. Appropriately, we have covered the most essential concepts required for research in the field of reinforcement learning, with robotics in mind. Through a thorough analysis of this problem, we are able to manifest how reinforcement learning could be applied profitably, and also focus on open-ended questions, as well as the potential for future research.
* This paper was originally written in 2019
Real-time Action Recognition for Fine-Grained Actions and The Hand Wash Dataset
Oct 13, 2022
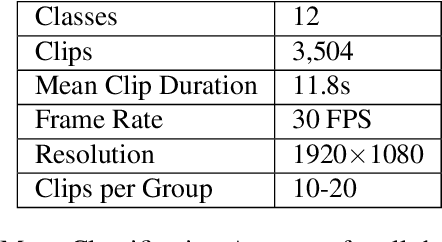
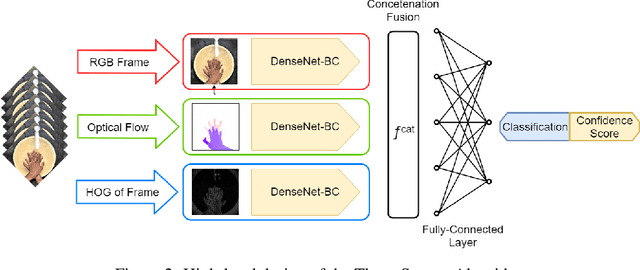
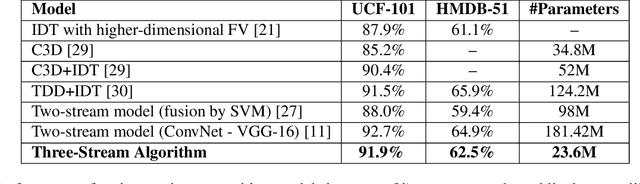
In this paper we present a three-stream algorithm for real-time action recognition and a new dataset of handwash videos, with the intent of aligning action recognition with real-world constraints to yield effective conclusions. A three-stream fusion algorithm is proposed, which runs both accurately and efficiently, in real-time even on low-powered systems such as a Raspberry Pi. The cornerstone of the proposed algorithm is the incorporation of both spatial and temporal information, as well as the information of the objects in a video while using an efficient architecture, and Optical Flow computation to achieve commendable results in real-time. The results achieved by this algorithm are benchmarked on the UCF-101 as well as the HMDB-51 datasets, achieving an accuracy of 92.7% and 64.9% respectively. An important point to note is that the algorithm is novel in the aspect that it is also able to learn the intricate differences between extremely similar actions, which would be difficult even for the human eye. Additionally, noticing a dearth in the number of datasets for the recognition of very similar or fine-grained actions, this paper also introduces a new dataset that is made publicly available, the Hand Wash Dataset with the intent of introducing a new benchmark for fine-grained action recognition tasks in the future.
Cross-domain Variational Capsules for Information Extraction
Oct 13, 2022In this paper, we present a characteristic extraction algorithm and the Multi-domain Image Characteristics Dataset of characteristic-tagged images to simulate the way a human brain classifies cross-domain information and generates insight. The intent was to identify prominent characteristics in data and use this identification mechanism to auto-generate insight from data in other unseen domains. An information extraction algorithm is proposed which is a combination of Variational Autoencoders (VAEs) and Capsule Networks. Capsule Networks are used to decompose images into their individual features and VAEs are used to explore variations on these decomposed features. Thus, making the model robust in recognizing characteristics from variations of the data. A noteworthy point is that the algorithm uses efficient hierarchical decoding of data which helps in richer output interpretation. Noticing a dearth in the number of datasets that contain visible characteristics in images belonging to various domains, the Multi-domain Image Characteristics Dataset was created and made publicly available. It consists of thousands of images across three domains. This dataset was created with the intent of introducing a new benchmark for fine-grained characteristic recognition tasks in the future.
* This paper was originally written in 2020