 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Virtual Reality and AI Tutoring for Language Learning: A Case Study of a Virtual Campus Environment with OpenAI GPT Integration with Unity 3D
Nov 19, 2024


This paper presents a new approach to multiple language learning, with Hindi the language to be learnt in our case, by using the integration of virtual reality environments and AI enabled tutoring systems using OpenAIs GPT api calls. We have developed a scenario which has a virtual campus environment using Unity which focuses on a detailed representation of our universitys buildings 11th floor, where most of the cultural and technological activities take place. Within this virtual environment that we have created, we have an AI tutor powered by OpenAI's GPT model which was called using an api which moves around with the user. This provided language learning support in Hindi, as GPT is able to take care of language translation. Our approach mainly involves utilising speech to text, text to text conversion and text to speech capabilities to facilitate real time interaction between users and the AI tutor in the presence of internet. This research demonstrates the use of combining VR technology with AI tutoring for immersive language learning experiences and provides interaction.
ScripTONES: Sentiment-Conditioned Music Generation for Movie Scripts
Jan 13, 2024



Film scores are considered an essential part of the film cinematic experience, but the process of film score generation is often expensive and infeasible for small-scale creators. Automating the process of film score composition would provide useful starting points for music in small projects. In this paper, we propose a two-stage pipeline for generating music from a movie script. The first phase is the Sentiment Analysis phase where the sentiment of a scene from the film script is encoded into the valence-arousal continuous space. The second phase is the Conditional Music Generation phase which takes as input the valence-arousal vector and conditionally generates piano MIDI music to match the sentiment. We study the efficacy of various music generation architectures by performing a qualitative user survey and propose methods to improve sentiment-conditioning in VAE architectures.
Real-Time Automated Answer Scoring
Oct 13, 2022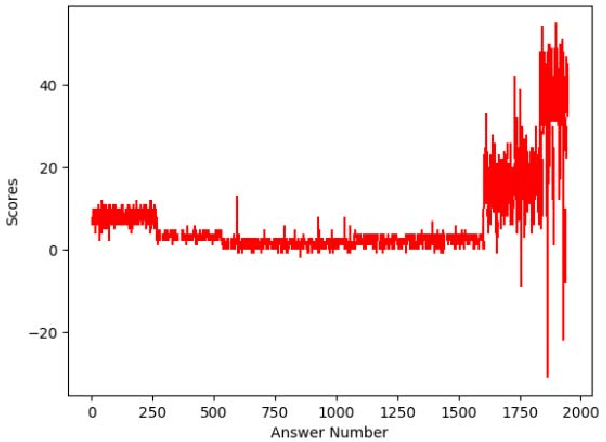
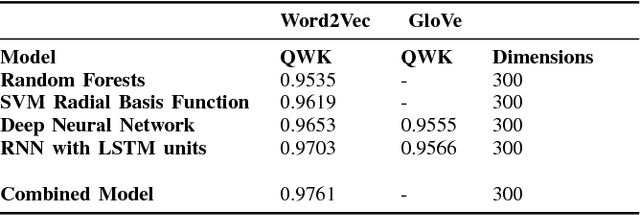
In recent years, the role of big data analytics has exponentially grown and is now slowly making its way into the education industry. Several attempts are being made in this sphere in order to improve the quality of education being provided to students and while many collaborations have been carried out before, automated scoring of answers has been explored to a rather limited extent. One of the biggest hurdles to choosing constructed-response assessments over multiple-choice assessments is the effort and large cost that comes with their evaluation and this is precisely the issue that this project aims to solve. The aim is to accept raw-input from the student in the form of their answer, preprocess the answer, and automatically score the answer. In addition, we have made this a real-time system that captures "snapshots" of the writer's progress with respect to the answer, allowing us to unearth trends with respect to the way a student thinks, and how the student has arrived at their final answer.
* This paper was originally written in mid 2018
Real-time Action Recognition for Fine-Grained Actions and The Hand Wash Dataset
Oct 13, 2022
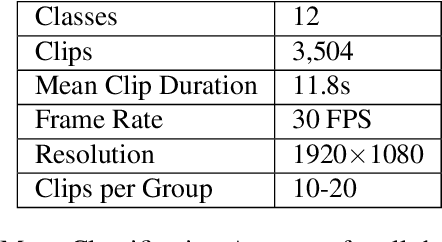
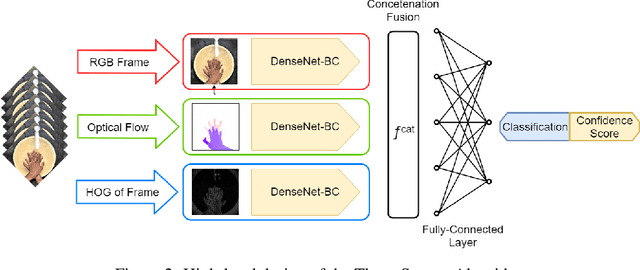
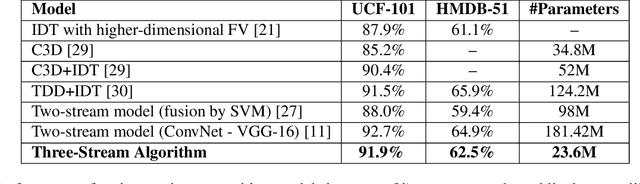
In this paper we present a three-stream algorithm for real-time action recognition and a new dataset of handwash videos, with the intent of aligning action recognition with real-world constraints to yield effective conclusions. A three-stream fusion algorithm is proposed, which runs both accurately and efficiently, in real-time even on low-powered systems such as a Raspberry Pi. The cornerstone of the proposed algorithm is the incorporation of both spatial and temporal information, as well as the information of the objects in a video while using an efficient architecture, and Optical Flow computation to achieve commendable results in real-time. The results achieved by this algorithm are benchmarked on the UCF-101 as well as the HMDB-51 datasets, achieving an accuracy of 92.7% and 64.9% respectively. An important point to note is that the algorithm is novel in the aspect that it is also able to learn the intricate differences between extremely similar actions, which would be difficult even for the human eye. Additionally, noticing a dearth in the number of datasets for the recognition of very similar or fine-grained actions, this paper also introduces a new dataset that is made publicly available, the Hand Wash Dataset with the intent of introducing a new benchmark for fine-grained action recognition tasks in the future.
Guaranteeing Convergence of Iterative Skewed Voting Algorithms for Image Segmentation
Feb 21, 2011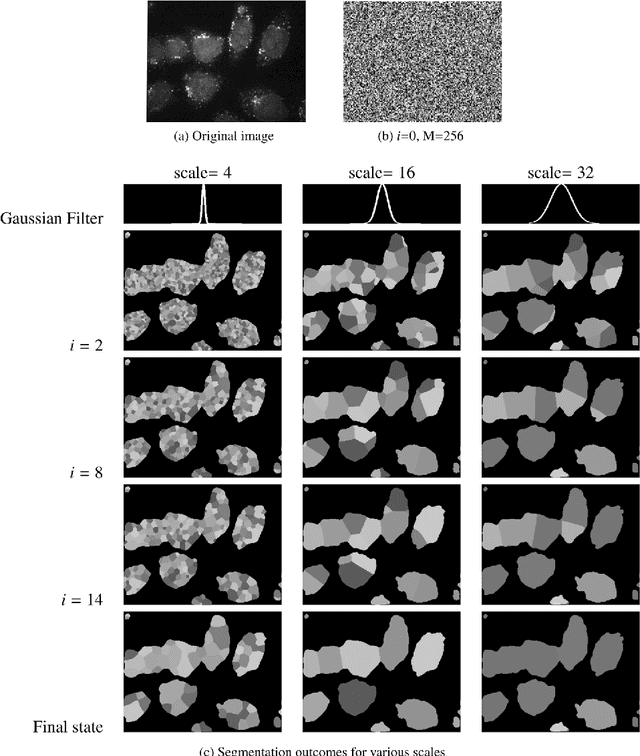
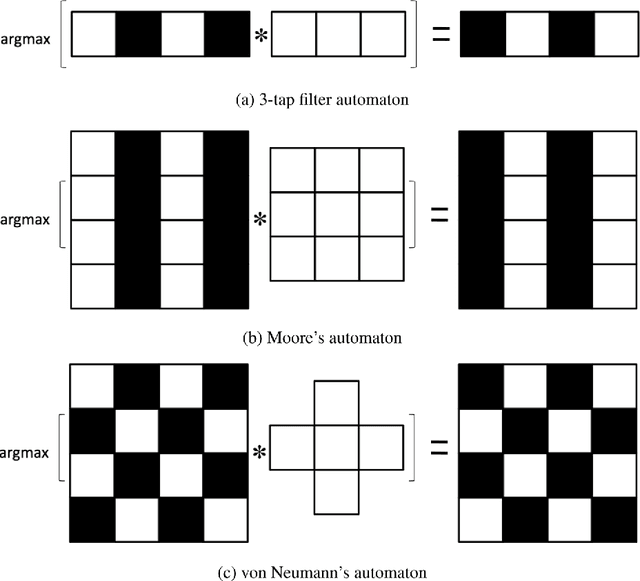
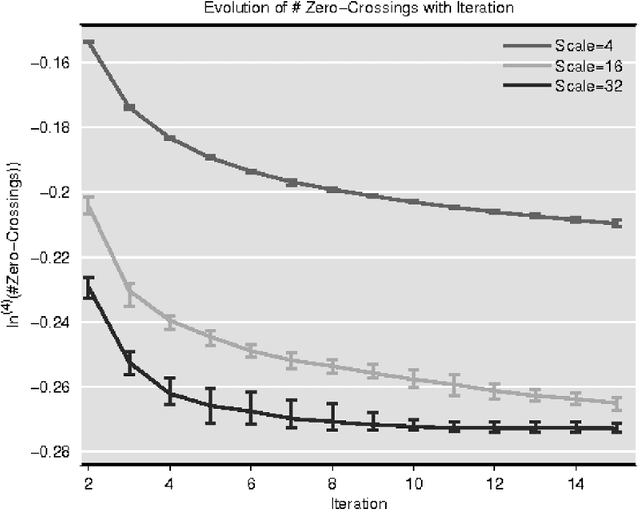
In this paper we provide rigorous proof for the convergence of an iterative voting-based image segmentation algorithm called Active Masks. Active Masks (AM) was proposed to solve the challenging task of delineating punctate patterns of cells from fluorescence microscope images. Each iteration of AM consists of a linear convolution composed with a nonlinear thresholding; what makes this process special in our case is the presence of additive terms whose role is to "skew" the voting when prior information is available. In real-world implementation, the AM algorithm always converges to a fixed point. We study the behavior of AM rigorously and present a proof of this convergence. The key idea is to formulate AM as a generalized (parallel) majority cellular automaton, adapting proof techniques from discrete dynamical systems.