 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 3D-PC: a benchmark for visual perspective taking in humans and machines
Jun 06, 2024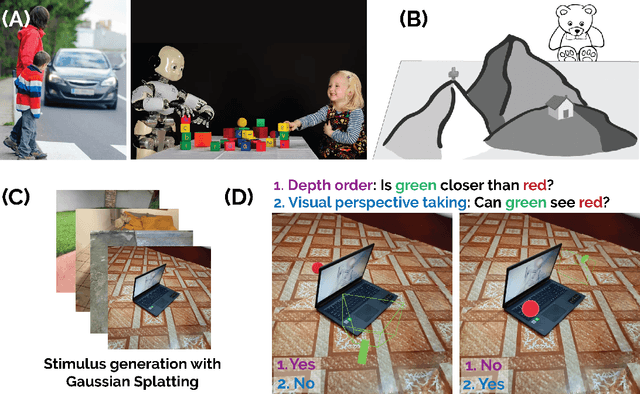


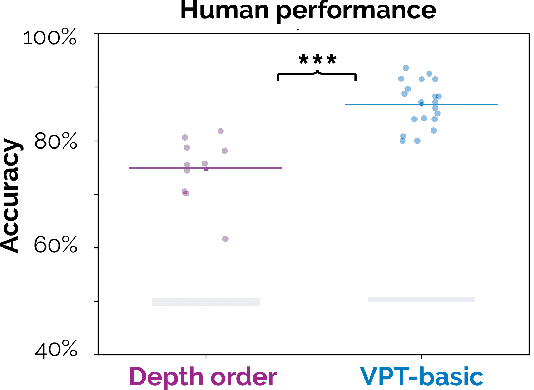
Visual perspective taking (VPT) is the ability to perceive and reason about the perspectives of others. It is an essential feature of human intelligence, which develops over the first decade of life and requires an ability to process the 3D structure of visual scenes. A growing number of reports have indicated that deep neural networks (DNNs) become capable of analyzing 3D scenes after training on large image datasets. We investigated if this emergent ability for 3D analysis in DNNs is sufficient for VPT with the 3D perception challenge (3D-PC): a novel benchmark for 3D perception in humans and DNNs. The 3D-PC is comprised of three 3D-analysis tasks posed within natural scene images: 1. a simple test of object depth order, 2. a basic VPT task (VPT-basic), and 3. another version of VPT (VPT-Strategy) designed to limit the effectiveness of "shortcut" visual strategies. We tested human participants (N=33) and linearly probed or text-prompted over 300 DNNs on the challenge and found that nearly all of the DNNs approached or exceeded human accuracy in analyzing object depth order. Surprisingly, DNN accuracy on this task correlated with their object recognition performance. In contrast, there was an extraordinary gap between DNNs and humans on VPT-basic. Humans were nearly perfect, whereas most DNNs were near chance. Fine-tuning DNNs on VPT-basic brought them close to human performance, but they, unlike humans, dropped back to chance when tested on VPT-perturb. Our challenge demonstrates that the training routines and architectures of today's DNNs are well-suited for learning basic 3D properties of scenes and objects but are ill-suited for reasoning about these properties like humans do. We release our 3D-PC datasets and code to help bridge this gap in 3D perception between humans and machines.
Skeleton Extraction from 3D Point Clouds by Decomposing the Object into Parts
Dec 26, 2019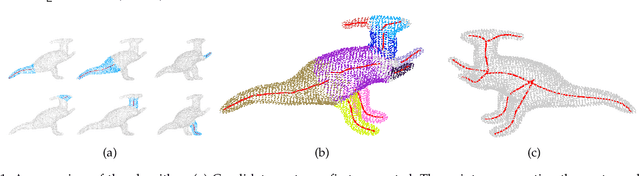
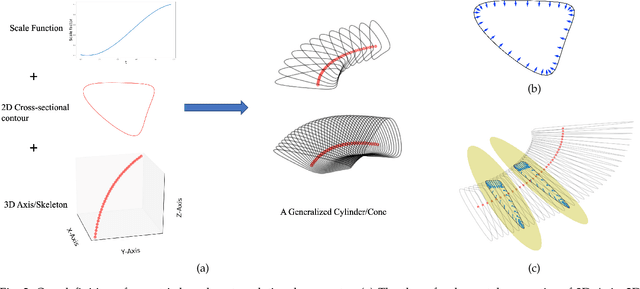

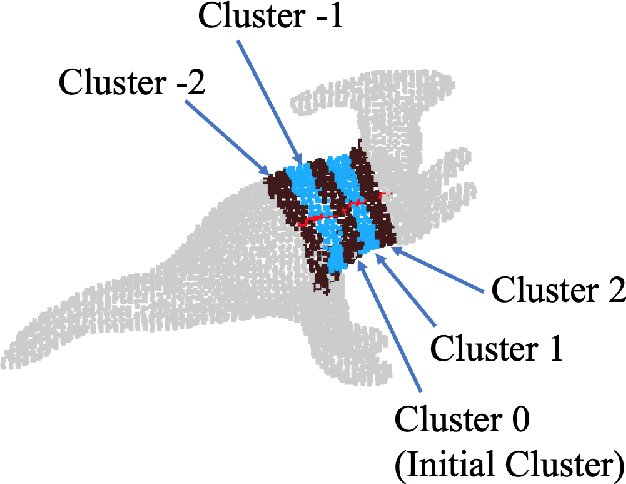
Decomposing a point cloud into its components and extracting curve skeletons from point clouds are two related problems. Decomposition of a shape into its components is often obtained as a byproduct of skeleton extraction. In this work, we propose to extract curve skeletons, from unorganized point clouds, by decomposing the object into its parts, identifying part skeletons and then linking these part skeletons together to obtain the complete skeleton. We believe it is the most natural way to extract skeletons in the sense that this would be the way a human would approach the problem. Our parts are generalized cylinders (GCs). Since, the axis of a GC is an integral part of its definition, the parts have natural skeletal representations. We use translational symmetry, the fundamental property of GCs, to extract parts from point clouds. We demonstrate how this method can handle a large variety of shapes. We compare our method with state of the art methods and show how a part based approach can deal with some of the limitations of other methods. We present an improved version of an existing point set registration algorithm and demonstrate its utility in extracting parts from point clouds. We also show how this method can be used to extract skeletons from and identify parts of noisy point clouds. A part based approach also provides a natural and intuitive interface for user interaction. We demonstrate the ease with which mistakes, if any, can be fixed with minimal user interaction with the help of a graphical user interface.