 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking objects that change in appearance with phase synchrony
Oct 02, 2024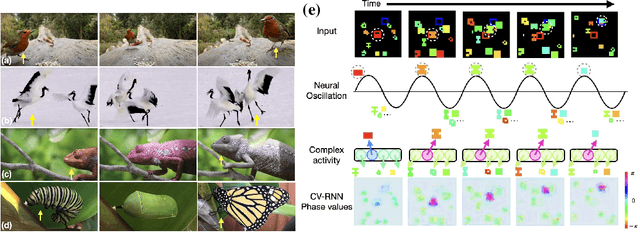
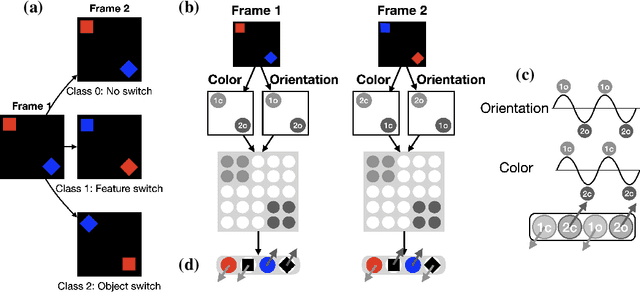
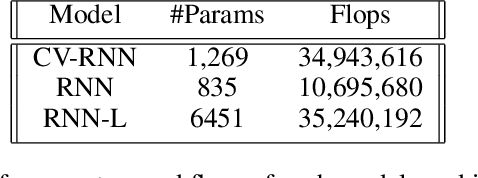
Objects we encounter often change appearance as we interact with them. Changes in illumination (shadows), object pose, or movement of nonrigid objects can drastically alter available image features. How do biological visual systems track objects as they change? It may involve specific attentional mechanisms for reasoning about the locations of objects independently of their appearances -- a capability that prominent neuroscientific theories have associated with computing through neural synchrony. We computationally test the hypothesis that the implementation of visual attention through neural synchrony underlies the ability of biological visual systems to track objects that change in appearance over time. We first introduce a novel deep learning circuit that can learn to precisely control attention to features separately from their location in the world through neural synchrony: the complex-valued recurrent neural network (CV-RNN). Next, we compare object tracking in humans, the CV-RNN, and other deep neural networks (DNNs), using FeatureTracker: a large-scale challenge that asks observers to track objects as their locations and appearances change in precisely controlled ways. While humans effortlessly solved FeatureTracker, state-of-the-art DNNs did not. In contrast, our CV-RNN behaved similarly to humans on the challenge, providing a computational proof-of-concept for the role of phase synchronization as a neural substrate for tracking appearance-morphing objects as they move about.
The 3D-PC: a benchmark for visual perspective taking in humans and machines
Jun 06, 2024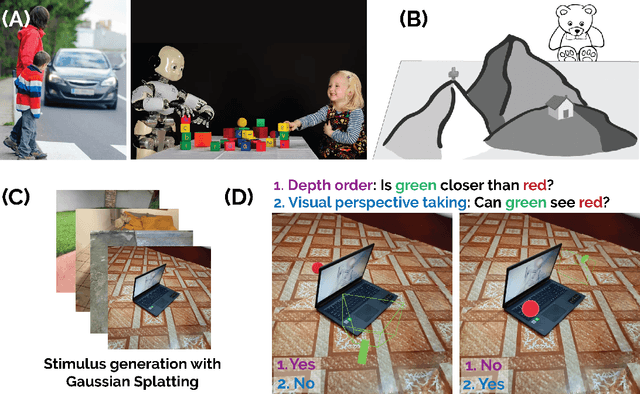


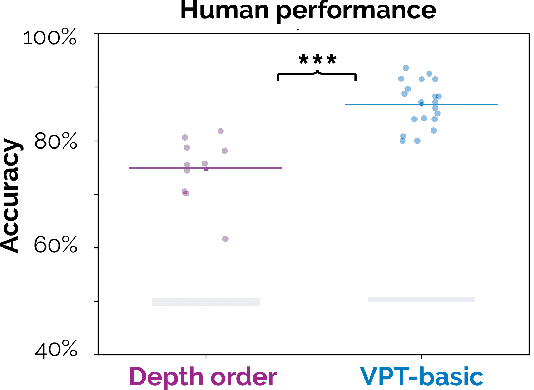
Visual perspective taking (VPT) is the ability to perceive and reason about the perspectives of others. It is an essential feature of human intelligence, which develops over the first decade of life and requires an ability to process the 3D structure of visual scenes. A growing number of reports have indicated that deep neural networks (DNNs) become capable of analyzing 3D scenes after training on large image datasets. We investigated if this emergent ability for 3D analysis in DNNs is sufficient for VPT with the 3D perception challenge (3D-PC): a novel benchmark for 3D perception in humans and DNNs. The 3D-PC is comprised of three 3D-analysis tasks posed within natural scene images: 1. a simple test of object depth order, 2. a basic VPT task (VPT-basic), and 3. another version of VPT (VPT-Strategy) designed to limit the effectiveness of "shortcut" visual strategies. We tested human participants (N=33) and linearly probed or text-prompted over 300 DNNs on the challenge and found that nearly all of the DNNs approached or exceeded human accuracy in analyzing object depth order. Surprisingly, DNN accuracy on this task correlated with their object recognition performance. In contrast, there was an extraordinary gap between DNNs and humans on VPT-basic. Humans were nearly perfect, whereas most DNNs were near chance. Fine-tuning DNNs on VPT-basic brought them close to human performance, but they, unlike humans, dropped back to chance when tested on VPT-perturb. Our challenge demonstrates that the training routines and architectures of today's DNNs are well-suited for learning basic 3D properties of scenes and objects but are ill-suited for reasoning about these properties like humans do. We release our 3D-PC datasets and code to help bridge this gap in 3D perception between humans and machines.
Neural scaling laws for phenotypic drug discovery
Sep 28, 2023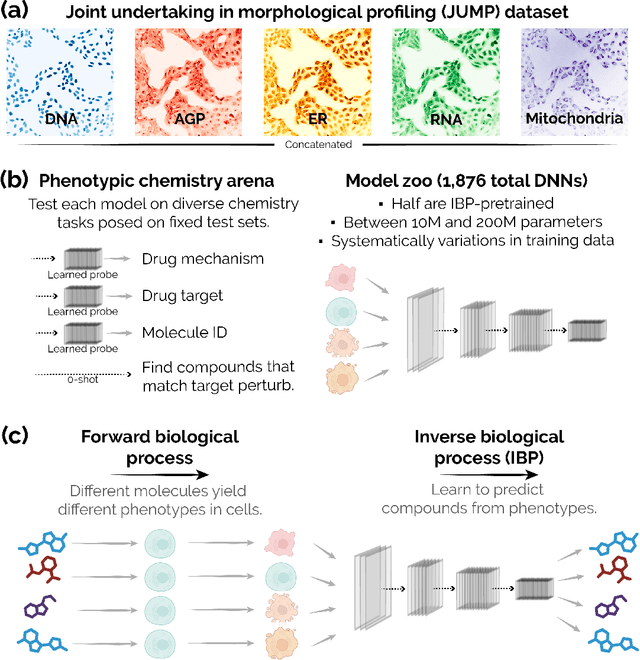
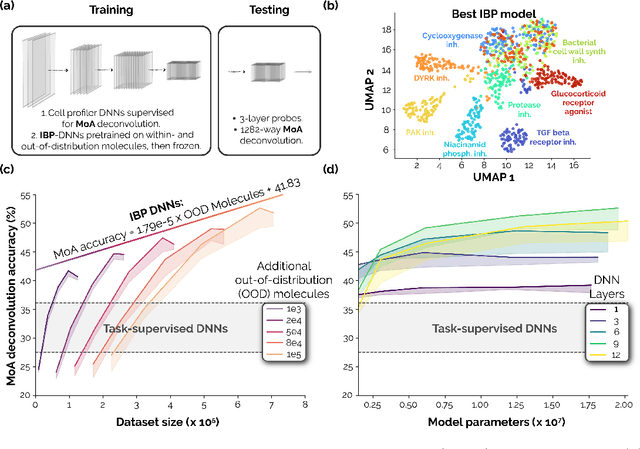
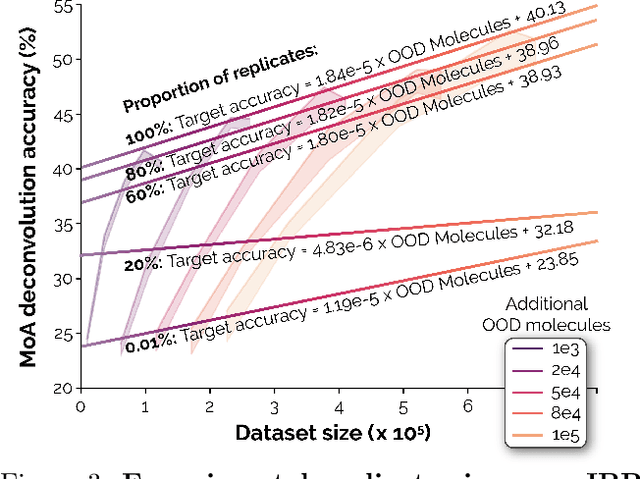
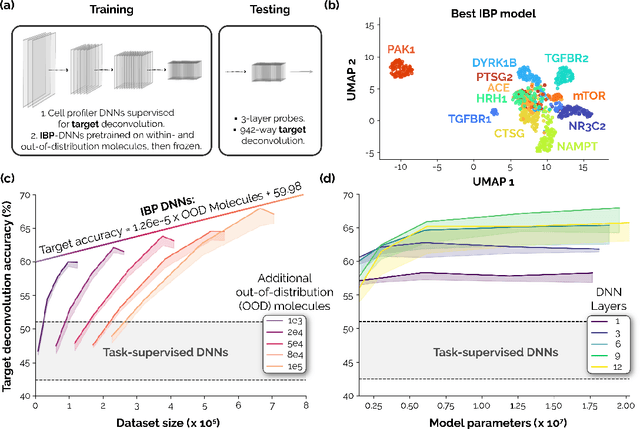
Recent breakthroughs by deep neural networks (DNNs) in natural language processing (NLP) and computer vision have been driven by a scale-up of models and data rather than the discovery of novel computing paradigms. Here, we investigate if scale can have a similar impact for models designed to aid small molecule drug discovery. We address this question through a large-scale and systematic analysis of how DNN size, data diet, and learning routines interact to impact accuracy on our Phenotypic Chemistry Arena (Pheno-CA) benchmark: a diverse set of drug development tasks posed on image-based high content screening data. Surprisingly, we find that DNNs explicitly supervised to solve tasks in the Pheno-CA do not continuously improve as their data and model size is scaled-up. To address this issue, we introduce a novel precursor task, the Inverse Biological Process (IBP), which is designed to resemble the causal objective functions that have proven successful for NLP. We indeed find that DNNs first trained with IBP then probed for performance on the Pheno-CA significantly outperform task-supervised DNNs. More importantly, the performance of these IBP-trained DNNs monotonically improves with data and model scale. Our findings reveal that the DNN ingredients needed to accurately solve small molecule drug development tasks are already in our hands, and project how much more experimental data is needed to achieve any desired level of improvement. We release our Pheno-CA benchmark and code to encourage further study of neural scaling laws for small molecule drug discovery.
Diagnosing and exploiting the computational demands of videos games for deep reinforcement learning
Sep 22, 2023Humans learn by interacting with their environments and perceiving the outcomes of their actions. A landmark in artificial intelligence has been the development of deep reinforcement learning (dRL) algorithms capable of doing the same in video games, on par with or better than humans. However, it remains unclear whether the successes of dRL models reflect advances in visual representation learning, the effectiveness of reinforcement learning algorithms at discovering better policies, or both. To address this question, we introduce the Learning Challenge Diagnosticator (LCD), a tool that separately measures the perceptual and reinforcement learning demands of a task. We use LCD to discover a novel taxonomy of challenges in the Procgen benchmark, and demonstrate that these predictions are both highly reliable and can instruct algorithmic development. More broadly, the LCD reveals multiple failure cases that can occur when optimizing dRL algorithms over entire video game benchmarks like Procgen, and provides a pathway towards more efficient progress.
Unlocking Feature Visualization for Deeper Networks with MAgnitude Constrained Optimization
Jun 11, 2023
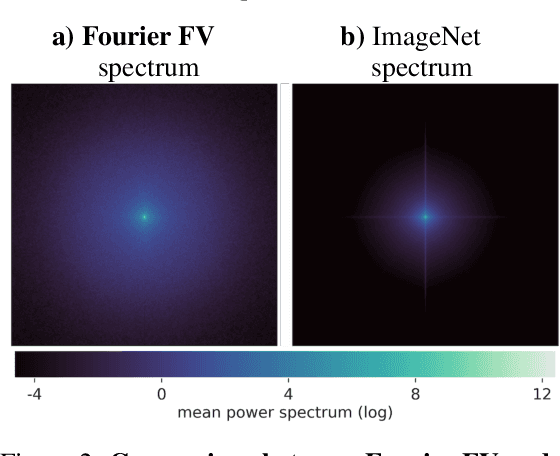
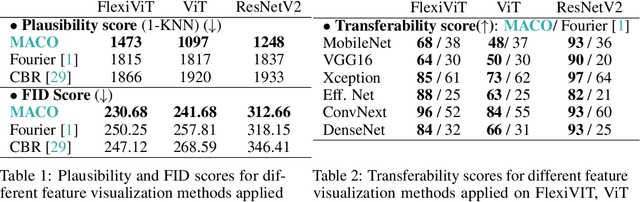
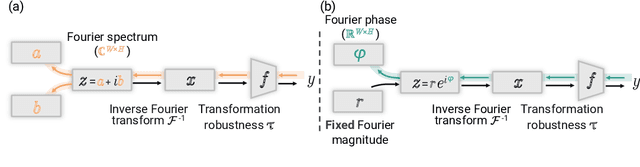
Feature visualization has gained substantial popularity, particularly after the influential work by Olah et al. in 2017, which established it as a crucial tool for explainability. However, its widespread adoption has been limited due to a reliance on tricks to generate interpretable images, and corresponding challenges in scaling it to deeper neural networks. Here, we describe MACO, a simple approach to address these shortcomings. The main idea is to generate images by optimizing the phase spectrum while keeping the magnitude constant to ensure that generated explanations lie in the space of natural images. Our approach yields significantly better results (both qualitatively and quantitatively) and unlocks efficient and interpretable feature visualizations for large state-of-the-art neural networks. We also show that our approach exhibits an attribution mechanism allowing us to augment feature visualizations with spatial importance. We validate our method on a novel benchmark for comparing feature visualization methods, and release its visualizations for all classes of the ImageNet dataset on https://serre-lab.github.io/Lens/. Overall, our approach unlocks, for the first time, feature visualizations for large, state-of-the-art deep neural networks without resorting to any parametric prior image model.
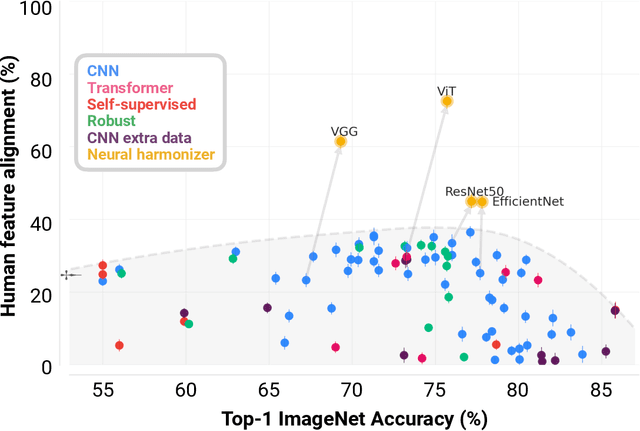
Performance-optimized deep neural networks are evolving into worse models of inferotemporal visual cortex
Jun 06, 2023One of the most impactful findings in computational neuroscience over the past decade is that the object recognition accuracy of deep neural networks (DNNs) correlates with their ability to predict neural responses to natural images in the inferotemporal (IT) cortex. This discovery supported the long-held theory that object recognition is a core objective of the visual cortex, and suggested that more accurate DNNs would serve as better models of IT neuron responses to images. Since then, deep learning has undergone a revolution of scale: billion parameter-scale DNNs trained on billions of images are rivaling or outperforming humans at visual tasks including object recognition. Have today's DNNs become more accurate at predicting IT neuron responses to images as they have grown more accurate at object recognition? Surprisingly, across three independent experiments, we find this is not the case. DNNs have become progressively worse models of IT as their accuracy has increased on ImageNet. To understand why DNNs experience this trade-off and evaluate if they are still an appropriate paradigm for modeling the visual system, we turn to recordings of IT that capture spatially resolved maps of neuronal activity elicited by natural images. These neuronal activity maps reveal that DNNs trained on ImageNet learn to rely on different visual features than those encoded by IT and that this problem worsens as their accuracy increases. We successfully resolved this issue with the neural harmonizer, a plug-and-play training routine for DNNs that aligns their learned representations with humans. Our results suggest that harmonized DNNs break the trade-off between ImageNet accuracy and neural prediction accuracy that assails current DNNs and offer a path to more accurate models of biological vision.
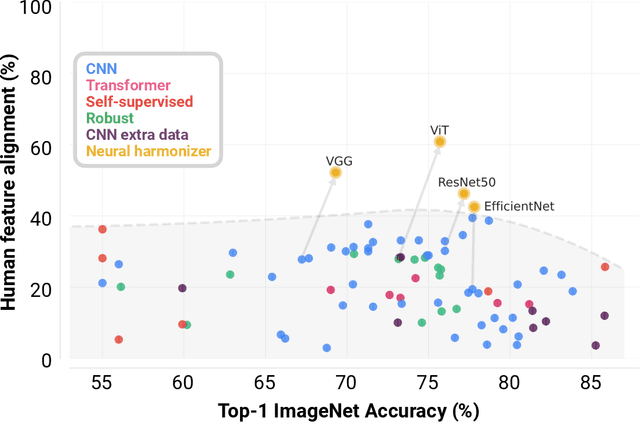
Adversarial alignment: Breaking the trade-off between the strength of an attack and its relevance to human perception
Jun 05, 2023
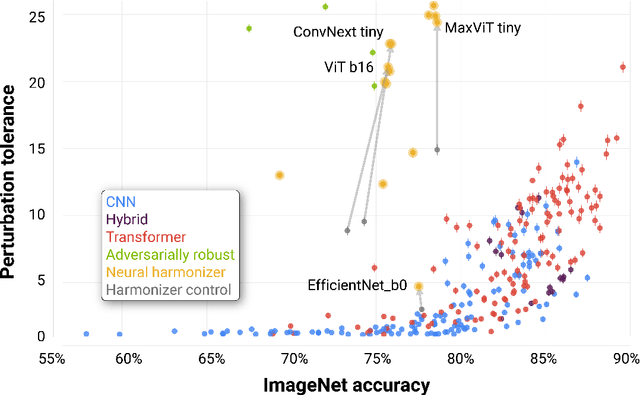
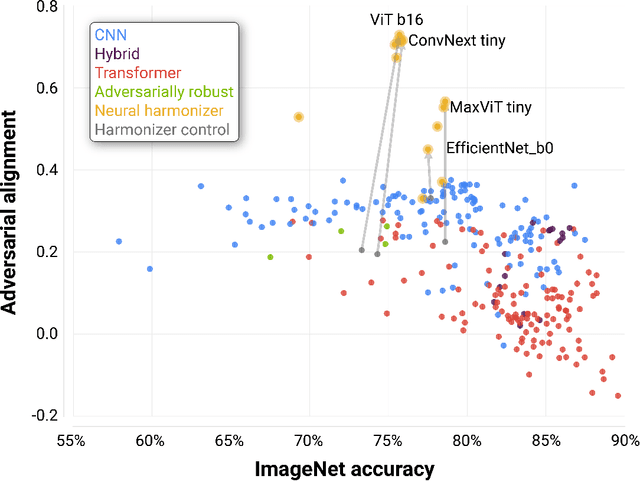
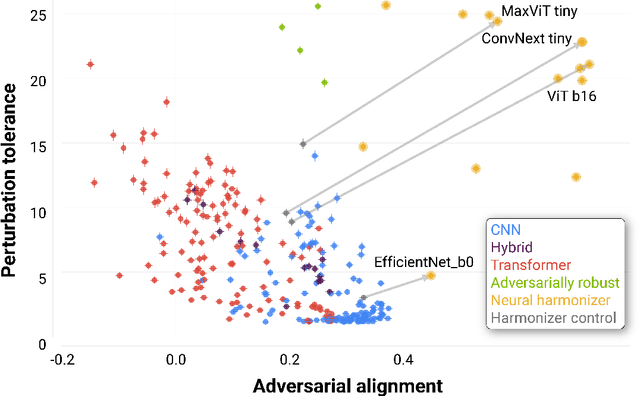
Deep neural networks (DNNs) are known to have a fundamental sensitivity to adversarial attacks, perturbations of the input that are imperceptible to humans yet powerful enough to change the visual decision of a model. Adversarial attacks have long been considered the "Achilles' heel" of deep learning, which may eventually force a shift in modeling paradigms. Nevertheless, the formidable capabilities of modern large-scale DNNs have somewhat eclipsed these early concerns. Do adversarial attacks continue to pose a threat to DNNs? Here, we investigate how the robustness of DNNs to adversarial attacks has evolved as their accuracy on ImageNet has continued to improve. We measure adversarial robustness in two different ways: First, we measure the smallest adversarial attack needed to cause a model to change its object categorization decision. Second, we measure how aligned successful attacks are with the features that humans find diagnostic for object recognition. We find that adversarial attacks are inducing bigger and more easily detectable changes to image pixels as DNNs grow better on ImageNet, but these attacks are also becoming less aligned with features that humans find diagnostic for recognition. To better understand the source of this trade-off, we turn to the neural harmonizer, a DNN training routine that encourages models to leverage the same features as humans to solve tasks. Harmonized DNNs achieve the best of both worlds and experience attacks that are detectable and affect features that humans find diagnostic for recognition, meaning that attacks on these models are more likely to be rendered ineffective by inducing similar effects on human perception. Our findings suggest that the sensitivity of DNNs to adversarial attacks can be mitigated by DNN scale, data scale, and training routines that align models with biological intelligence.
Harmonizing the object recognition strategies of deep neural networks with humans
Nov 11, 2022
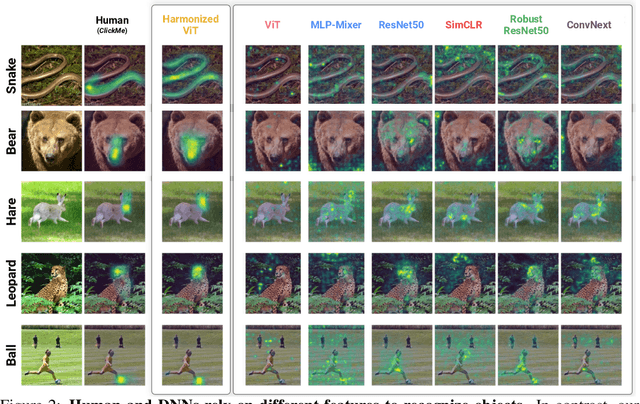
The many successes of deep neural networks (DNNs) over the past decade have largely been driven by computational scale rather than insights from biological intelligence. Here, we explore if these trends have also carried concomitant improvements in explaining the visual strategies humans rely on for object recognition. We do this by comparing two related but distinct properties of visual strategies in humans and DNNs: where they believe important visual features are in images and how they use those features to categorize objects. Across 84 different DNNs trained on ImageNet and three independent datasets measuring the where and the how of human visual strategies for object recognition on those images, we find a systematic trade-off between DNN categorization accuracy and alignment with human visual strategies for object recognition. State-of-the-art DNNs are progressively becoming less aligned with humans as their accuracy improves. We rectify this growing issue with our neural harmonizer: a general-purpose training routine that both aligns DNN and human visual strategies and improves categorization accuracy. Our work represents the first demonstration that the scaling laws that are guiding the design of DNNs today have also produced worse models of human vision. We release our code and data at https://serre-lab.github.io/Harmonization to help the field build more human-like DNNs.
The Challenge of Appearance-Free Object Tracking with Feedforward Neural Networks
Sep 30, 2021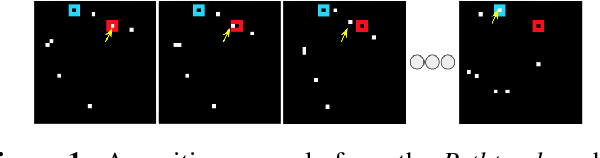

Nearly all models for object tracking with artificial neural networks depend on appearance features extracted from a "backbone" architecture, designed for object recognition. Indeed, significant progress on object tracking has been spurred by introducing backbones that are better able to discriminate objects by their appearance. However, extensive neurophysiology and psychophysics evidence suggests that biological visual systems track objects using both appearance and motion features. Here, we introduce $\textit{PathTracker}$, a visual challenge inspired by cognitive psychology, which tests the ability of observers to learn to track objects solely by their motion. We find that standard 3D-convolutional deep network models struggle to solve this task when clutter is introduced into the generated scenes, or when objects travel long distances. This challenge reveals that tracing the path of object motion is a blind spot of feedforward neural networks. We expect that strategies for appearance-free object tracking from biological vision can inspire solutions these failures of deep neural networks.
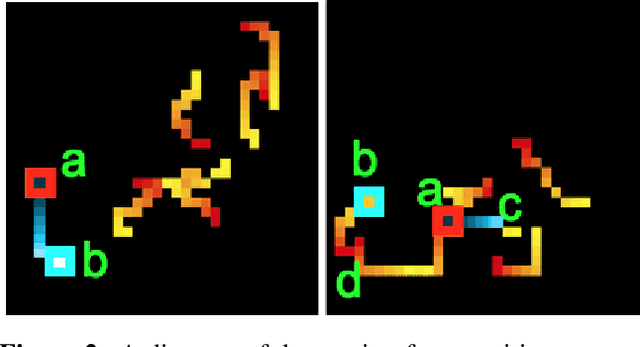
Understanding the computational demands underlying visual reasoning
Aug 08, 2021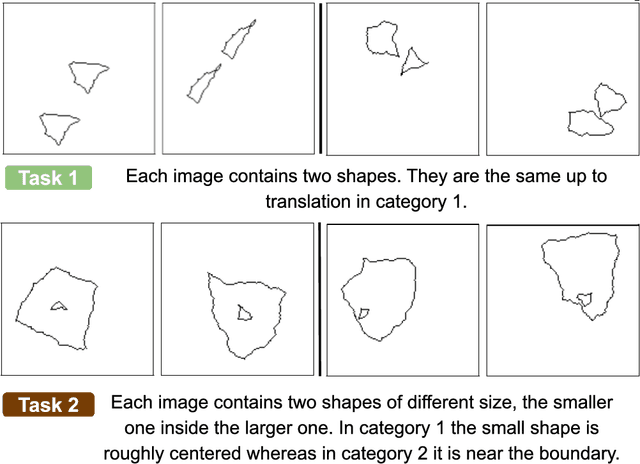
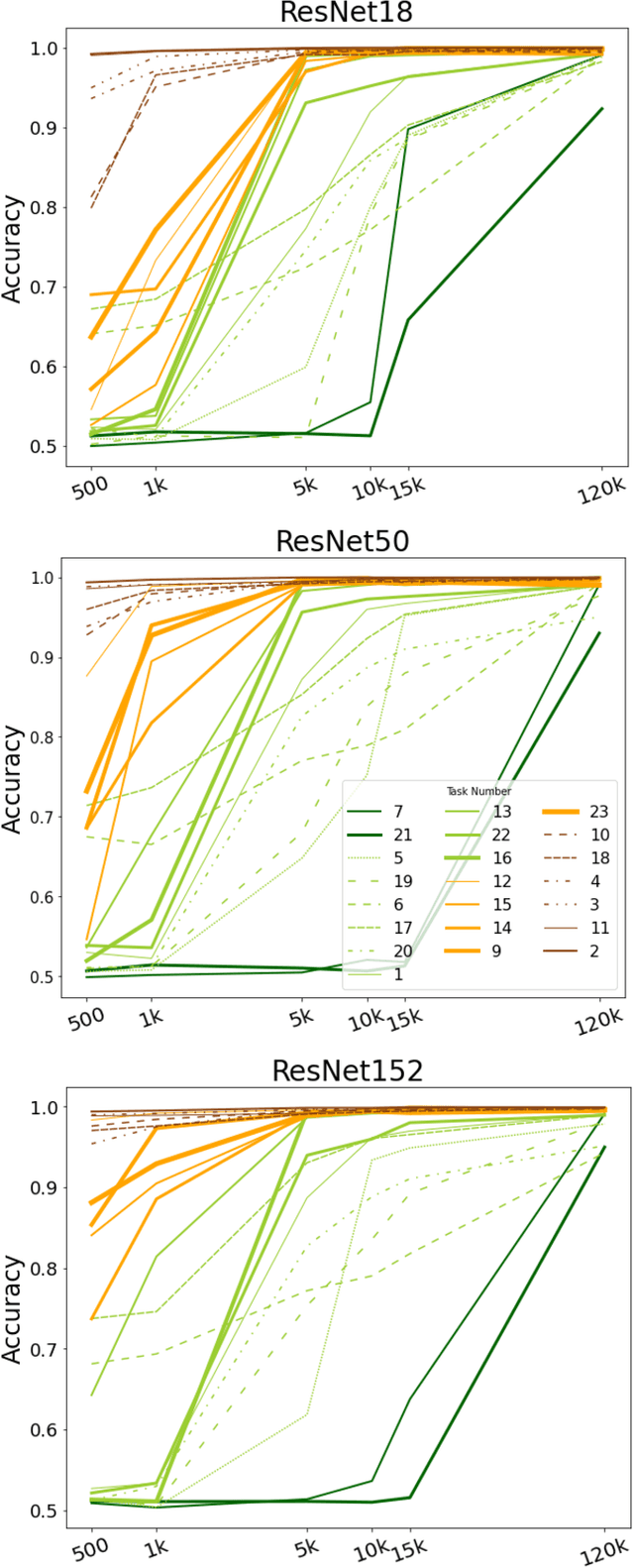
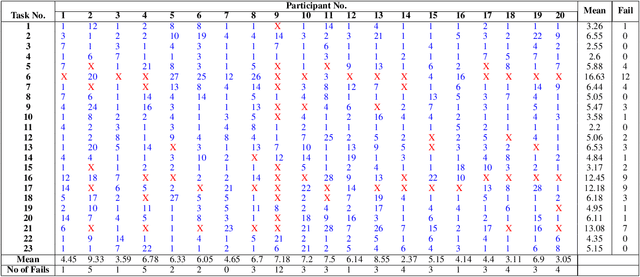
Visual understanding requires comprehending complex visual relations between objects within a scene. Here, we seek to characterize the computational demands for abstract visual reasoning. We do this by systematically assessing the ability of modern deep convolutional neural networks (CNNs) to learn to solve the Synthetic Visual Reasoning Test (SVRT) challenge, a collection of twenty-three visual reasoning problems. Our analysis leads to a novel taxonomy of visual reasoning tasks, which can be primarily explained by both the type of relations (same-different vs. spatial-relation judgments) and the number of relations used to compose the underlying rules. Prior cognitive neuroscience work suggests that attention plays a key role in human's visual reasoning ability. To test this, we extended the CNNs with spatial and feature-based attention mechanisms. In a second series of experiments, we evaluated the ability of these attention networks to learn to solve the SVRT challenge and found the resulting architectures to be much more efficient at solving the hardest of these visual reasoning tasks. Most importantly, the corresponding improvements on individual tasks partially explained the taxonomy. Overall, this work advances our understanding of visual reasoning and yields testable Neuroscience predictions regarding the need for feature-based vs. spatial attention in visual reasoning.