 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbolic Grounding Reveals Representational Bottlenecks in Abstract Visual Reasoning
Apr 23, 2026Vision--language models (VLMs) often fail on abstract visual reasoning benchmarks such as Bongard problems, raising the question of whether the main bottleneck lies in reasoning or representation. We study this on Bongard-LOGO, a synthetic benchmark of abstract concept learning with ground-truth generative programs, by comparing end-to-end VLMs on raw images with large language models (LLMs) given symbolic inputs derived from those images. Using symbolic inputs as a diagnostic probe rather than a practical multimodal architecture, our \emph{Componential--Grammatical (C--G)} paradigm reformulates Bongard-LOGO as a symbolic reasoning task based on LOGO-style action programs or structured descriptions. LLMs achieve large and consistent gains, reaching mid--90s accuracy on Free-form problems, while a strong visual baseline remains near chance under matched task definitions. Ablations on input format, explicit concept prompts, and minimal visual grounding show that these factors matter much less than the shift from pixels to symbolic structure. These results identify representation as a key bottleneck in abstract visual reasoning and show how symbolic input can serve as a controlled diagnostic upper bound.
Beyond the Linear Separability Ceiling
Jul 10, 2025Most state-of-the-art Visual-Language Models (VLMs) are seemingly limited by the linear separabilty of their visual embeddings on abstract reasoning tasks. This work investigates this "linear reasoning bottleneck" by introducing the Linear Separability Ceiling (LSC), the performance of a simple linear classifier on a VLM's visual embeddings. We find this bottleneck is widespread and stems not from poor perception, but from failures in the language model's reasoning pathways. We demonstrate this is a solvable alignment issue. The required intervention, however, is task-dependent: activating existing pathways suffices for semantic concepts, while complex relational reasoning requires adapting core model weights. Using postfix tuning as a methodological control, we find strong evidence for powerful, dormant reasoning pathways within VLMs. However, for complex relational tasks requiring deeper adaptation, explicitly improving representation quality causes the model to fail on new prompt formats despite its embeddings remaining well separated. Ultimately, this work provides a new lens for VLM analysis, showing that robust reasoning is a matter of targeted alignment, not simply improved representation learning.
Cognitive Paradigms for Evaluating VLMs on Visual Reasoning Task
Jan 23, 2025



Evaluating the reasoning capabilities of Vision-Language Models (VLMs) in complex visual tasks provides valuable insights into their potential and limitations. In this work, we assess the performance of VLMs on the challenging Bongard Openworld Problems benchmark, which involves reasoning over natural images. We propose and evaluate three human-inspired paradigms: holistic analysis (global context processing), deductive rule learning (explicit rule derivation and application), and componential analysis (structured decomposition of images into components). Our results demonstrate that state-of-the-art models, including GPT-4o and Gemini, not only surpass human benchmarks but also excel in structured reasoning tasks, with componential analysis proving especially effective. However, ablation studies reveal key challenges, such as handling synthetic images, making fine-grained distinctions, and interpreting nuanced contextual information. These insights underscore the need for further advancements in model robustness and generalization, while highlighting the transformative potential of structured reasoning approaches in enhancing VLM capabilities.
PhD Thesis: Exploring the role of attention in cognitive and computer vision architecture
Jun 28, 2023We investigate the role of attention and memory in complex reasoning tasks. We analyze Transformer-based self-attention as a model and extend it with memory. By studying a synthetic visual reasoning test, we refine the taxonomy of reasoning tasks. Incorporating self-attention with ResNet50, we enhance feature maps using feature-based and spatial attention, achieving efficient solving of challenging visual reasoning tasks. Our findings contribute to understanding the attentional needs of SVRT tasks. Additionally, we propose GAMR, a cognitive architecture combining attention and memory, inspired by active vision theory. GAMR outperforms other architectures in sample efficiency, robustness, and compositionality, and shows zero-shot generalization on new reasoning tasks.
Conviformers: Convolutionally guided Vision Transformer
Aug 28, 2022



Vision transformers are nowadays the de-facto choice for image classification tasks. There are two broad categories of classification tasks, fine-grained and coarse-grained. In fine-grained classification, the necessity is to discover subtle differences due to the high level of similarity between sub-classes. Such distinctions are often lost as we downscale the image to save the memory and computational cost associated with vision transformers (ViT). In this work, we present an in-depth analysis and describe the critical components for developing a system for the fine-grained categorization of plants from herbarium sheets. Our extensive experimental analysis indicated the need for a better augmentation technique and the ability of modern-day neural networks to handle higher dimensional images. We also introduce a convolutional transformer architecture called Conviformer which, unlike the popular Vision Transformer (ConViT), can handle higher resolution images without exploding memory and computational cost. We also introduce a novel, improved pre-processing technique called PreSizer to resize images better while preserving their original aspect ratios, which proved essential for classifying natural plants. With our simple yet effective approach, we achieved SoTA on Herbarium 202x and iNaturalist 2019 dataset.
MAREO: Memory- and Attention- based visual REasOning
Jun 13, 2022



Humans continue to vastly outperform modern AI systems in their ability to parse and understand complex visual scenes flexibly. Attention and memory are two systems known to play a critical role in our ability to selectively maintain and manipulate behaviorally-relevant visual information to solve some of the most challenging visual reasoning tasks. Here, we present a novel architecture for visual reasoning inspired by the cognitive-science literature on visual reasoning, the Memory- and Attention-based (visual) REasOning (MAREO) architecture. MAREO instantiates an active-vision theory, which posits that the brain solves complex visual reasoning problems compositionally by learning to combine previously-learned elementary visual operations to form more complex visual routines. MAREO learns to solve visual reasoning tasks via sequences of attention shifts to route and maintain task-relevant visual information into a memory bank via a multi-head transformer module. Visual routines are then deployed by a dedicated reasoning module trained to judge various relations between objects in the scenes. Experiments on four types of reasoning tasks demonstrate MAREO's ability to learn visual routines in a robust and sample-efficient manner.
A Benchmark for Compositional Visual Reasoning
Jun 11, 2022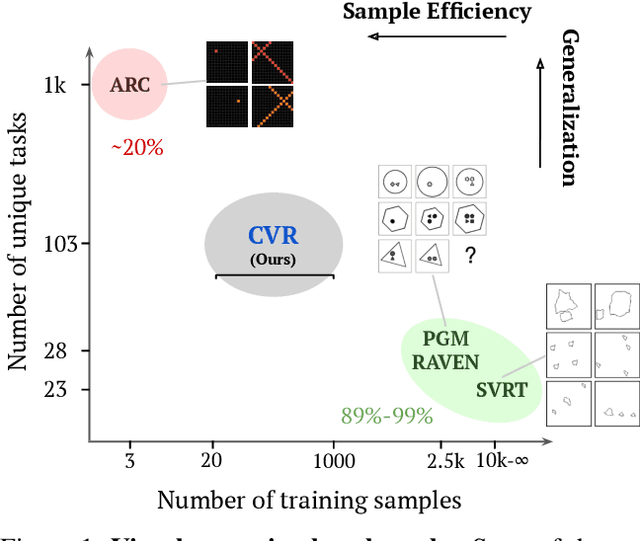
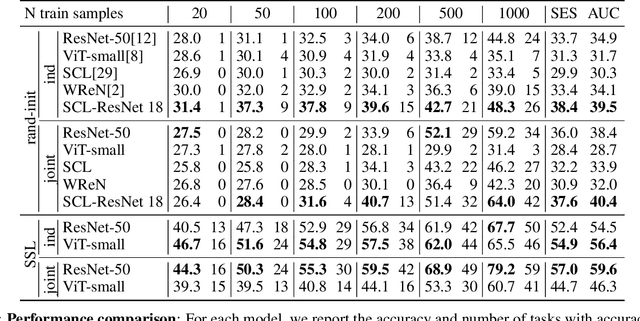
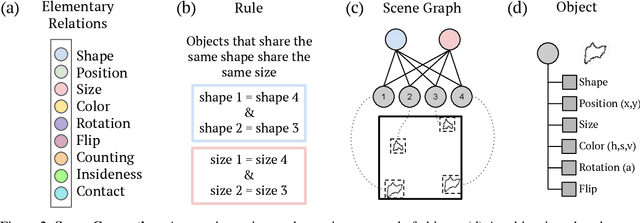
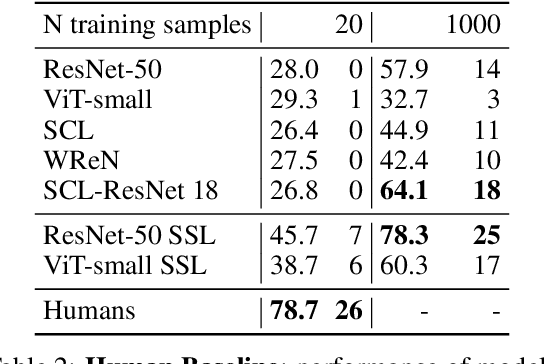
A fundamental component of human vision is our ability to parse complex visual scenes and judge the relations between their constituent objects. AI benchmarks for visual reasoning have driven rapid progress in recent years with state-of-the-art systems now reaching human accuracy on some of these benchmarks. Yet, a major gap remains in terms of the sample efficiency with which humans and AI systems learn new visual reasoning tasks. Humans' remarkable efficiency at learning has been at least partially attributed to their ability to harness compositionality -- such that they can efficiently take advantage of previously gained knowledge when learning new tasks. Here, we introduce a novel visual reasoning benchmark, Compositional Visual Relations (CVR), to drive progress towards the development of more data-efficient learning algorithms. We take inspiration from fluidic intelligence and non-verbal reasoning tests and describe a novel method for creating compositions of abstract rules and associated image datasets at scale. Our proposed benchmark includes measures of sample efficiency, generalization and transfer across task rules, as well as the ability to leverage compositionality. We systematically evaluate modern neural architectures and find that, surprisingly, convolutional architectures surpass transformer-based architectures across all performance measures in most data regimes. However, all computational models are a lot less data efficient compared to humans even after learning informative visual representations using self-supervision. Overall, we hope that our challenge will spur interest in the development of neural architectures that can learn to harness compositionality toward more efficient learning.
Understanding the computational demands underlying visual reasoning
Aug 08, 2021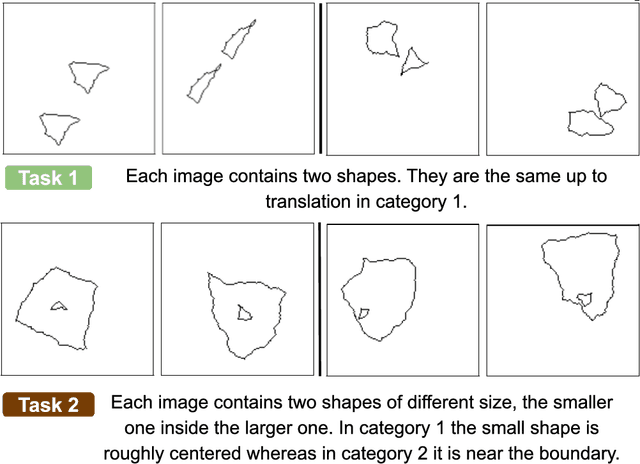
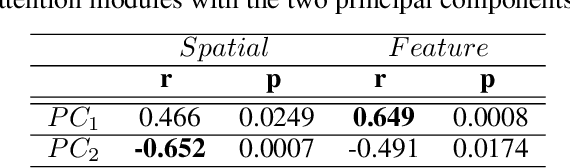
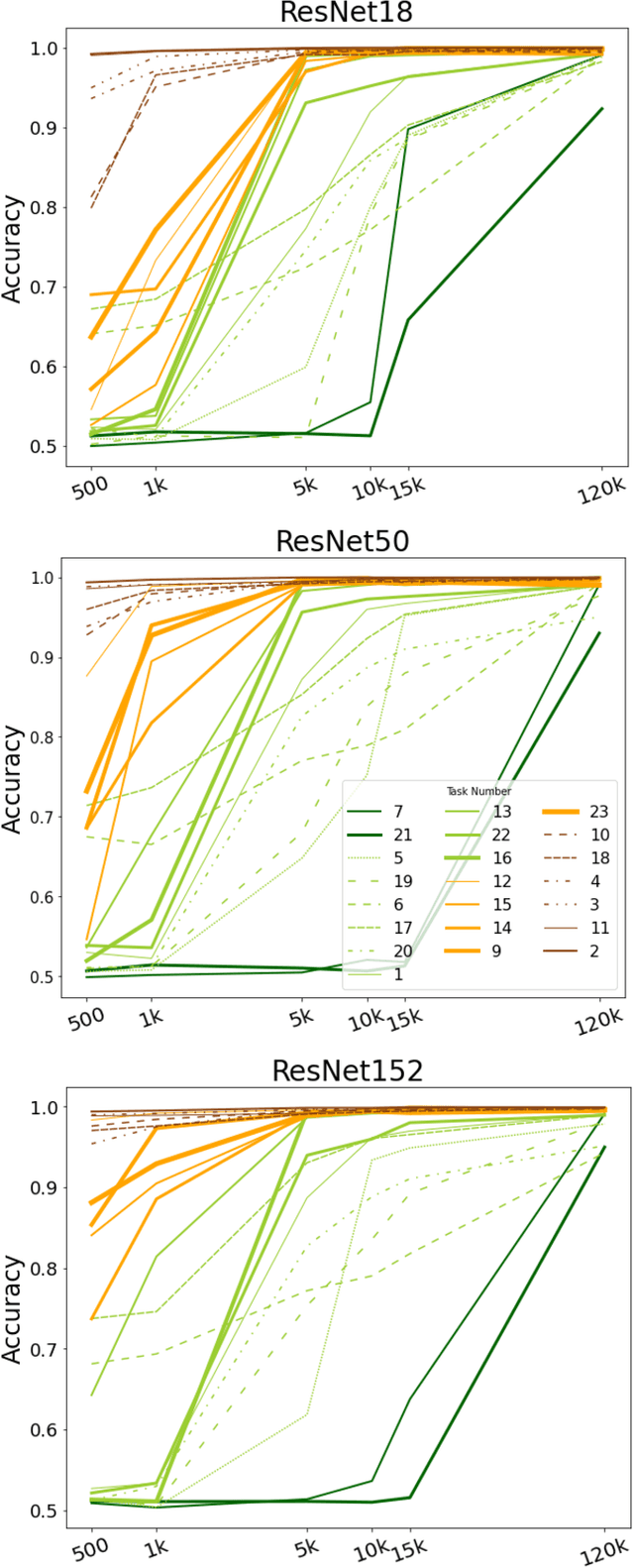
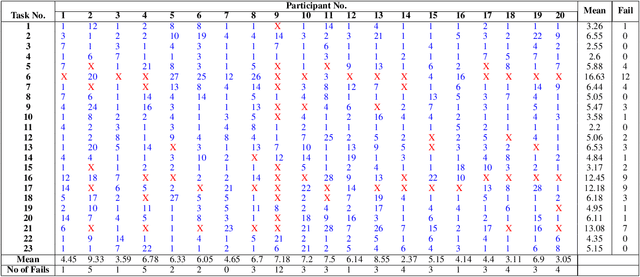
Visual understanding requires comprehending complex visual relations between objects within a scene. Here, we seek to characterize the computational demands for abstract visual reasoning. We do this by systematically assessing the ability of modern deep convolutional neural networks (CNNs) to learn to solve the Synthetic Visual Reasoning Test (SVRT) challenge, a collection of twenty-three visual reasoning problems. Our analysis leads to a novel taxonomy of visual reasoning tasks, which can be primarily explained by both the type of relations (same-different vs. spatial-relation judgments) and the number of relations used to compose the underlying rules. Prior cognitive neuroscience work suggests that attention plays a key role in human's visual reasoning ability. To test this, we extended the CNNs with spatial and feature-based attention mechanisms. In a second series of experiments, we evaluated the ability of these attention networks to learn to solve the SVRT challenge and found the resulting architectures to be much more efficient at solving the hardest of these visual reasoning tasks. Most importantly, the corresponding improvements on individual tasks partially explained the taxonomy. Overall, this work advances our understanding of visual reasoning and yields testable Neuroscience predictions regarding the need for feature-based vs. spatial attention in visual reasoning.