 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing deep neural networks through complex-valued representations and Kuramoto synchronization dynamics
Feb 28, 2025Neural synchrony is hypothesized to play a crucial role in how the brain organizes visual scenes into structured representations, enabling the robust encoding of multiple objects within a scene. However, current deep learning models often struggle with object binding, limiting their ability to represent multiple objects effectively. Inspired by neuroscience, we investigate whether synchrony-based mechanisms can enhance object encoding in artificial models trained for visual categorization. Specifically, we combine complex-valued representations with Kuramoto dynamics to promote phase alignment, facilitating the grouping of features belonging to the same object. We evaluate two architectures employing synchrony: a feedforward model and a recurrent model with feedback connections to refine phase synchronization using top-down information. Both models outperform their real-valued counterparts and complex-valued models without Kuramoto synchronization on tasks involving multi-object images, such as overlapping handwritten digits, noisy inputs, and out-of-distribution transformations. Our findings highlight the potential of synchrony-driven mechanisms to enhance deep learning models, improving their performance, robustness, and generalization in complex visual categorization tasks.
Understanding the computational demands underlying visual reasoning
Aug 08, 2021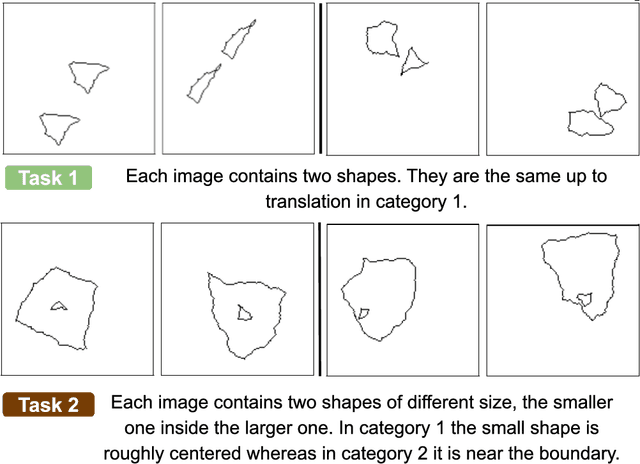
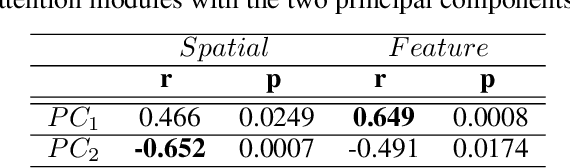
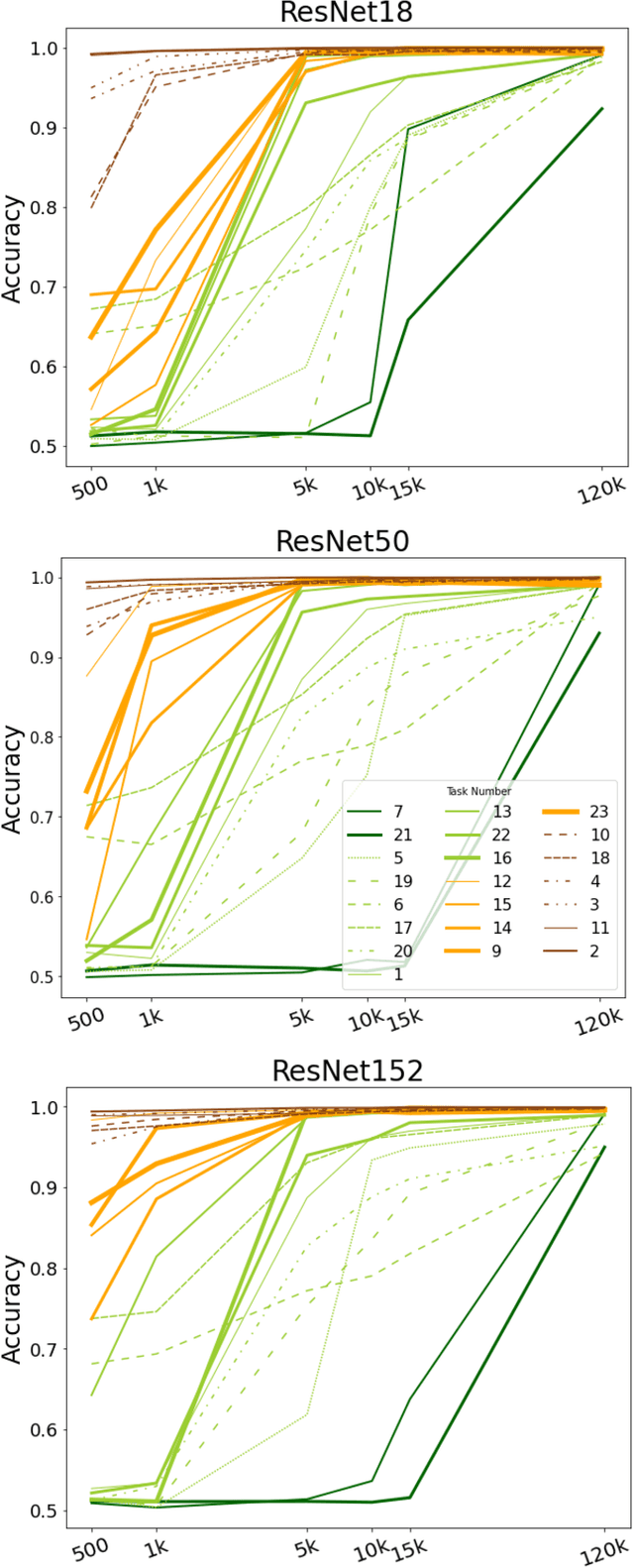
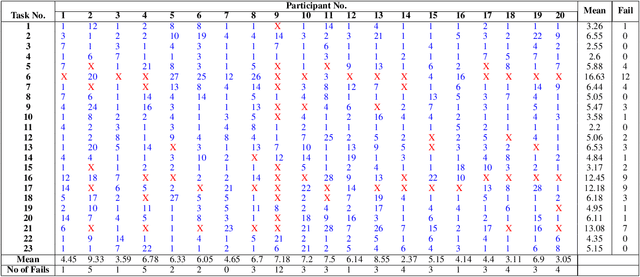
Visual understanding requires comprehending complex visual relations between objects within a scene. Here, we seek to characterize the computational demands for abstract visual reasoning. We do this by systematically assessing the ability of modern deep convolutional neural networks (CNNs) to learn to solve the Synthetic Visual Reasoning Test (SVRT) challenge, a collection of twenty-three visual reasoning problems. Our analysis leads to a novel taxonomy of visual reasoning tasks, which can be primarily explained by both the type of relations (same-different vs. spatial-relation judgments) and the number of relations used to compose the underlying rules. Prior cognitive neuroscience work suggests that attention plays a key role in human's visual reasoning ability. To test this, we extended the CNNs with spatial and feature-based attention mechanisms. In a second series of experiments, we evaluated the ability of these attention networks to learn to solve the SVRT challenge and found the resulting architectures to be much more efficient at solving the hardest of these visual reasoning tasks. Most importantly, the corresponding improvements on individual tasks partially explained the taxonomy. Overall, this work advances our understanding of visual reasoning and yields testable Neuroscience predictions regarding the need for feature-based vs. spatial attention in visual reasoning.
On the role of feedback in visual processing: a predictive coding perspective
Jun 08, 2021
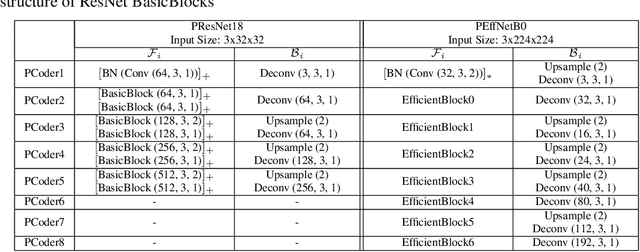


Brain-inspired machine learning is gaining increasing consideration, particularly in computer vision. Several studies investigated the inclusion of top-down feedback connections in convolutional networks; however, it remains unclear how and when these connections are functionally helpful. Here we address this question in the context of object recognition under noisy conditions. We consider deep convolutional networks (CNNs) as models of feed-forward visual processing and implement Predictive Coding (PC) dynamics through feedback connections (predictive feedback) trained for reconstruction or classification of clean images. To directly assess the computational role of predictive feedback in various experimental situations, we optimize and interpret the hyper-parameters controlling the network's recurrent dynamics. That is, we let the optimization process determine whether top-down connections and predictive coding dynamics are functionally beneficial. Across different model depths and architectures (3-layer CNN, ResNet18, and EfficientNetB0) and against various types of noise (CIFAR100-C), we find that the network increasingly relies on top-down predictions as the noise level increases; in deeper networks, this effect is most prominent at lower layers. In addition, the accuracy of the network implementing PC dynamics significantly increases over time-steps, compared to its equivalent forward network. All in all, our results provide novel insights relevant to Neuroscience by confirming the computational role of feedback connections in sensory systems, and to Machine Learning by revealing how these can improve the robustness of current vision models.
Predify: Augmenting deep neural networks with brain-inspired predictive coding dynamics
Jun 04, 2021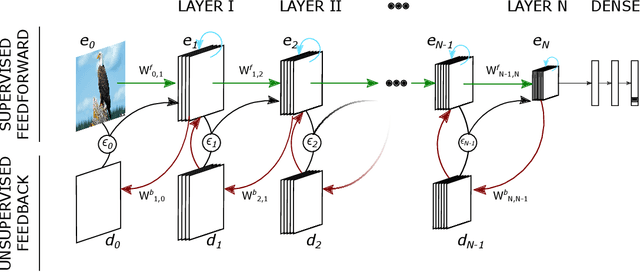

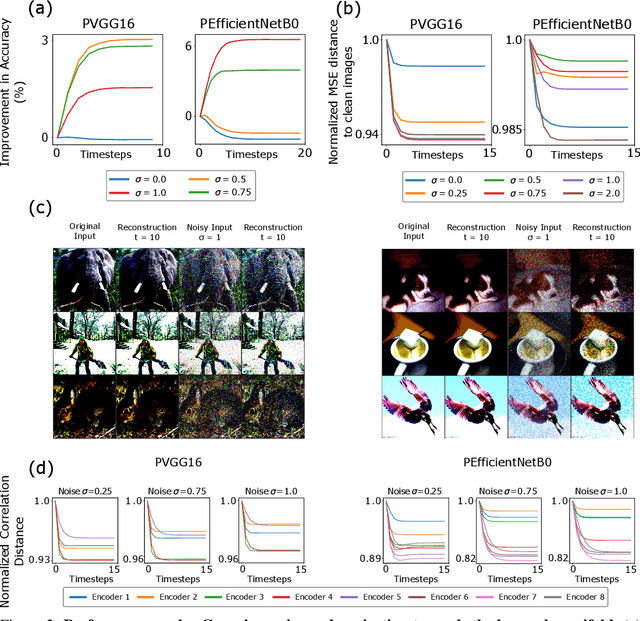
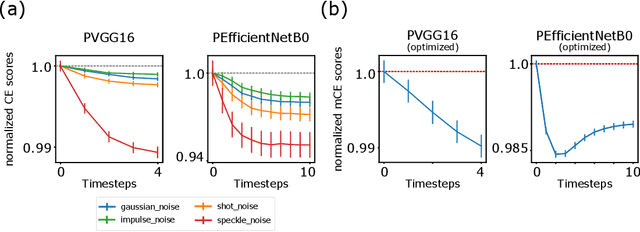
Deep neural networks excel at image classification, but their performance is far less robust to input perturbations than human perception. In this work we explore whether this shortcoming may be partly addressed by incorporating brain-inspired recurrent dynamics in deep convolutional networks. We take inspiration from a popular framework in neuroscience: 'predictive coding'. At each layer of the hierarchical model, generative feedback 'predicts' (i.e., reconstructs) the pattern of activity in the previous layer. The reconstruction errors are used to iteratively update the network's representations across timesteps, and to optimize the network's feedback weights over the natural image dataset-a form of unsupervised training. We show that implementing this strategy into two popular networks, VGG16 and EfficientNetB0, improves their robustness against various corruptions. We hypothesize that other feedforward networks could similarly benefit from the proposed framework. To promote research in this direction, we provide an open-sourced PyTorch-based package called Predify, which can be used to implement and investigate the impacts of the predictive coding dynamics in any convolutional neural network.
GAttANet: Global attention agreement for convolutional neural networks
Apr 12, 2021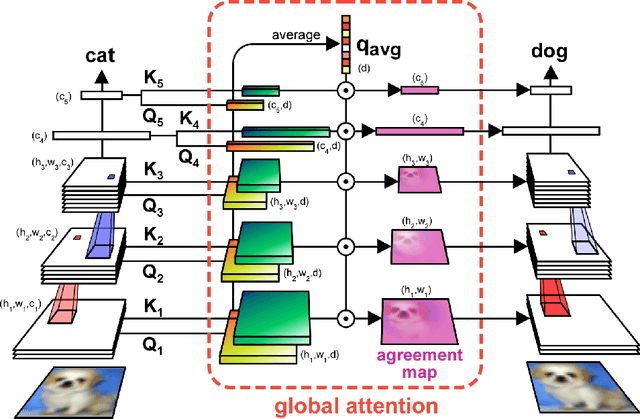

Transformer attention architectures, similar to those developed for natural language processing, have recently proved efficient also in vision, either in conjunction with or as a replacement for convolutional layers. Typically, visual attention is inserted in the network architecture as a (series of) feedforward self-attention module(s), with mutual key-query agreement as the main selection and routing operation. However efficient, this strategy is only vaguely compatible with the way that attention is implemented in biological brains: as a separate and unified network of attentional selection regions, receiving inputs from and exerting modulatory influence on the entire hierarchy of visual regions. Here, we report experiments with a simple such attention system that can improve the performance of standard convolutional networks, with relatively few additional parameters. Each spatial position in each layer of the network produces a key-query vector pair; all queries are then pooled into a global attention query. On the next iteration, the match between each key and the global attention query modulates the network's activations -- emphasizing or silencing the locations that agree or disagree (respectively) with the global attention system. We demonstrate the usefulness of this brain-inspired Global Attention Agreement network (GAttANet) for various convolutional backbones (from a simple 5-layer toy model to a standard ResNet50 architecture) and datasets (CIFAR10, CIFAR100, Imagenet-1k). Each time, our global attention system improves accuracy over the corresponding baseline.