 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAttANet: Global attention agreement for convolutional neural networks
Paper and Code
Apr 12, 2021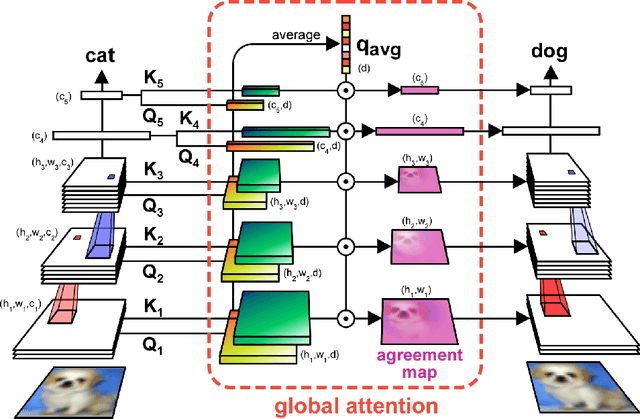

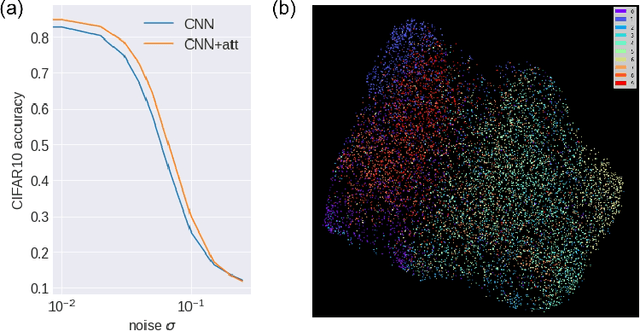
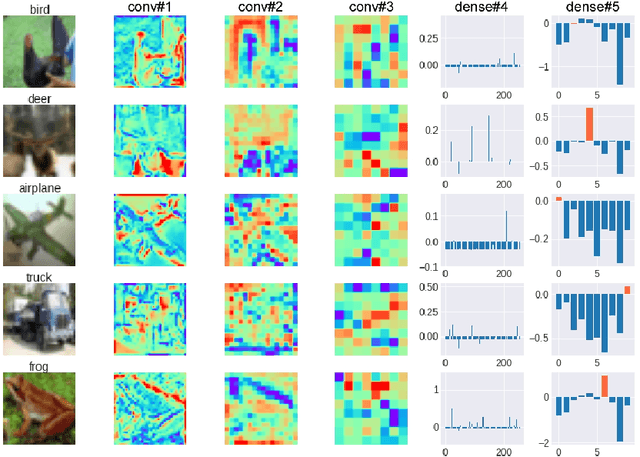
Transformer attention architectures, similar to those developed for natural language processing, have recently proved efficient also in vision, either in conjunction with or as a replacement for convolutional layers. Typically, visual attention is inserted in the network architecture as a (series of) feedforward self-attention module(s), with mutual key-query agreement as the main selection and routing operation. However efficient, this strategy is only vaguely compatible with the way that attention is implemented in biological brains: as a separate and unified network of attentional selection regions, receiving inputs from and exerting modulatory influence on the entire hierarchy of visual regions. Here, we report experiments with a simple such attention system that can improve the performance of standard convolutional networks, with relatively few additional parameters. Each spatial position in each layer of the network produces a key-query vector pair; all queries are then pooled into a global attention query. On the next iteration, the match between each key and the global attention query modulates the network's activations -- emphasizing or silencing the locations that agree or disagree (respectively) with the global attention system. We demonstrate the usefulness of this brain-inspired Global Attention Agreement network (GAttANet) for various convolutional backbones (from a simple 5-layer toy model to a standard ResNet50 architecture) and datasets (CIFAR10, CIFAR100, Imagenet-1k). Each time, our global attention system improves accuracy over the corresponding baseline.