 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXplique: A Deep Learning Explainability Toolbox
Jun 09, 2022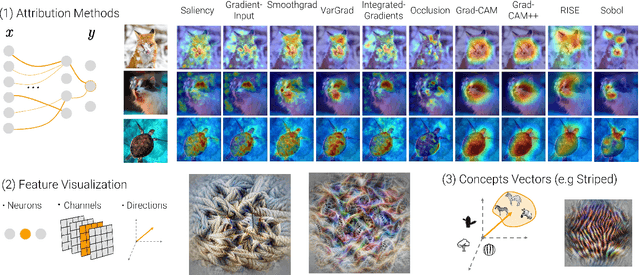
Today's most advanced machine-learning models are hardly scrutable. The key challenge for explainability methods is to help assisting researchers in opening up these black boxes, by revealing the strategy that led to a given decision, by characterizing their internal states or by studying the underlying data representation. To address this challenge, we have developed Xplique: a software library for explainability which includes representative explainability methods as well as associated evaluation metrics. It interfaces with one of the most popular learning libraries: Tensorflow as well as other libraries including PyTorch, scikit-learn and Theano. The code is licensed under the MIT license and is freely available at github.com/deel-ai/xplique.
Don't Lie to Me! Robust and Efficient Explainability with Verified Perturbation Analysis
Feb 15, 2022A variety of methods have been proposed to try to explain how deep neural networks make their decisions. Key to those approaches is the need to sample the pixel space efficiently in order to derive importance maps. However, it has been shown that the sampling methods used to date introduce biases and other artifacts, leading to inaccurate estimates of the importance of individual pixels and severely limit the reliability of current explainability methods. Unfortunately, the alternative -- to exhaustively sample the image space is computationally prohibitive. In this paper, we introduce EVA (Explaining using Verified perturbation Analysis) -- the first explainability method guarantee to have an exhaustive exploration of a perturbation space. Specifically, we leverage the beneficial properties of verified perturbation analysis -- time efficiency, tractability and guaranteed complete coverage of a manifold -- to efficiently characterize the input variables that are most likely to drive the model decision. We evaluate the approach systematically and demonstrate state-of-the-art results on multiple benchmarks.
What I Cannot Predict, I Do Not Understand: A Human-Centered Evaluation Framework for Explainability Methods
Dec 06, 2021
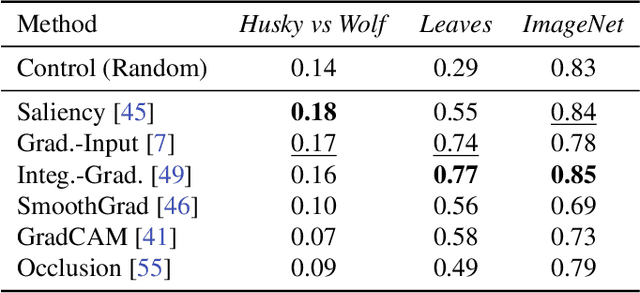
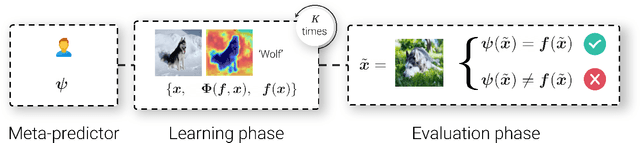
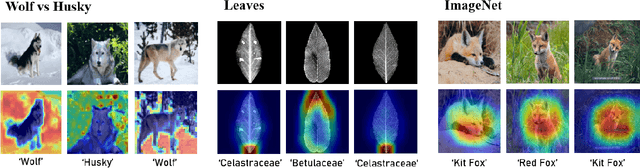
A multitude of explainability methods and theoretical evaluation scores have been proposed. However, it is not yet known: (1) how useful these methods are in real-world scenarios and (2) how well theoretical measures predict the usefulness of these methods for practical use by a human. To fill this gap, we conducted human psychophysics experiments at scale to evaluate the ability of human participants (n=1,150) to leverage representative attribution methods to learn to predict the decision of different image classifiers. Our results demonstrate that theoretical measures used to score explainability methods poorly reflect the practical usefulness of individual attribution methods in real-world scenarios. Furthermore, the degree to which individual attribution methods helped human participants predict classifiers' decisions varied widely across categorization tasks and datasets. Overall, our results highlight fundamental challenges for the field -- suggesting a critical need to develop better explainability methods and to deploy human-centered evaluation approaches. We will make the code of our framework available to ease the systematic evaluation of novel explainability methods.
Look at the Variance! Efficient Black-box Explanations with Sobol-based Sensitivity Analysis
Nov 07, 2021
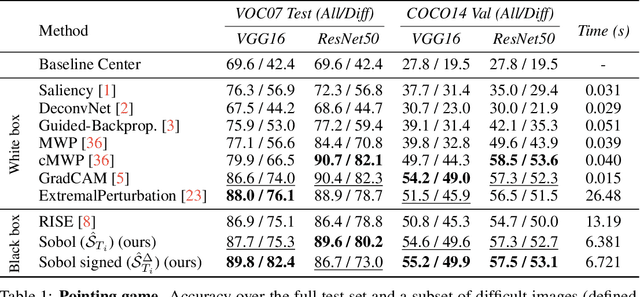
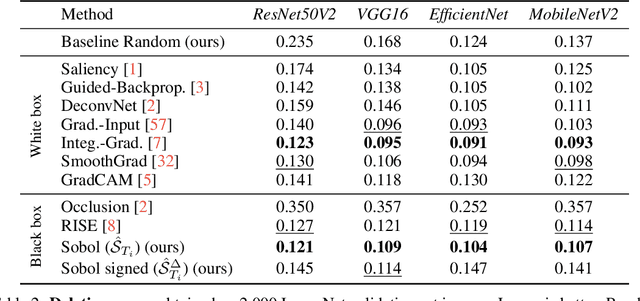
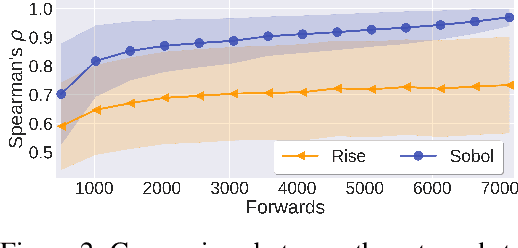
We describe a novel attribution method which is grounded in Sensitivity Analysis and uses Sobol indices. Beyond modeling the individual contributions of image regions, Sobol indices provide an efficient way to capture higher-order interactions between image regions and their contributions to a neural network's prediction through the lens of variance. We describe an approach that makes the computation of these indices efficient for high-dimensional problems by using perturbation masks coupled with efficient estimators to handle the high dimensionality of images. Importantly, we show that the proposed method leads to favorable scores on standard benchmarks for vision (and language models) while drastically reducing the computing time compared to other black-box methods -- even surpassing the accuracy of state-of-the-art white-box methods which require access to internal representations. Our code is freely available: https://github.com/fel-thomas/Sobol-Attribution-Method
Understanding the computational demands underlying visual reasoning
Aug 08, 2021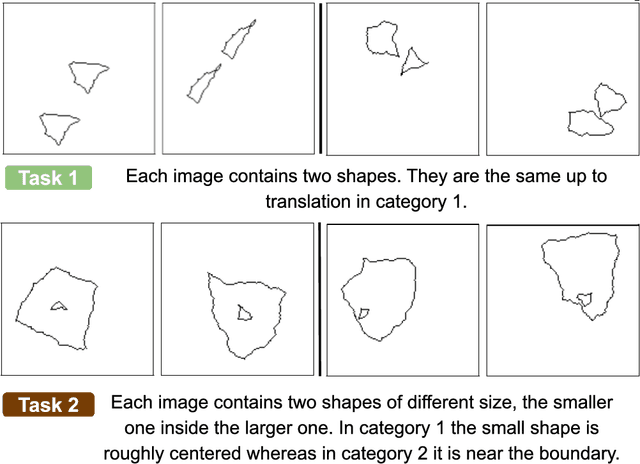
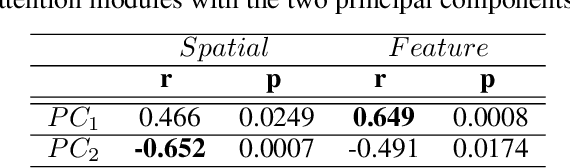
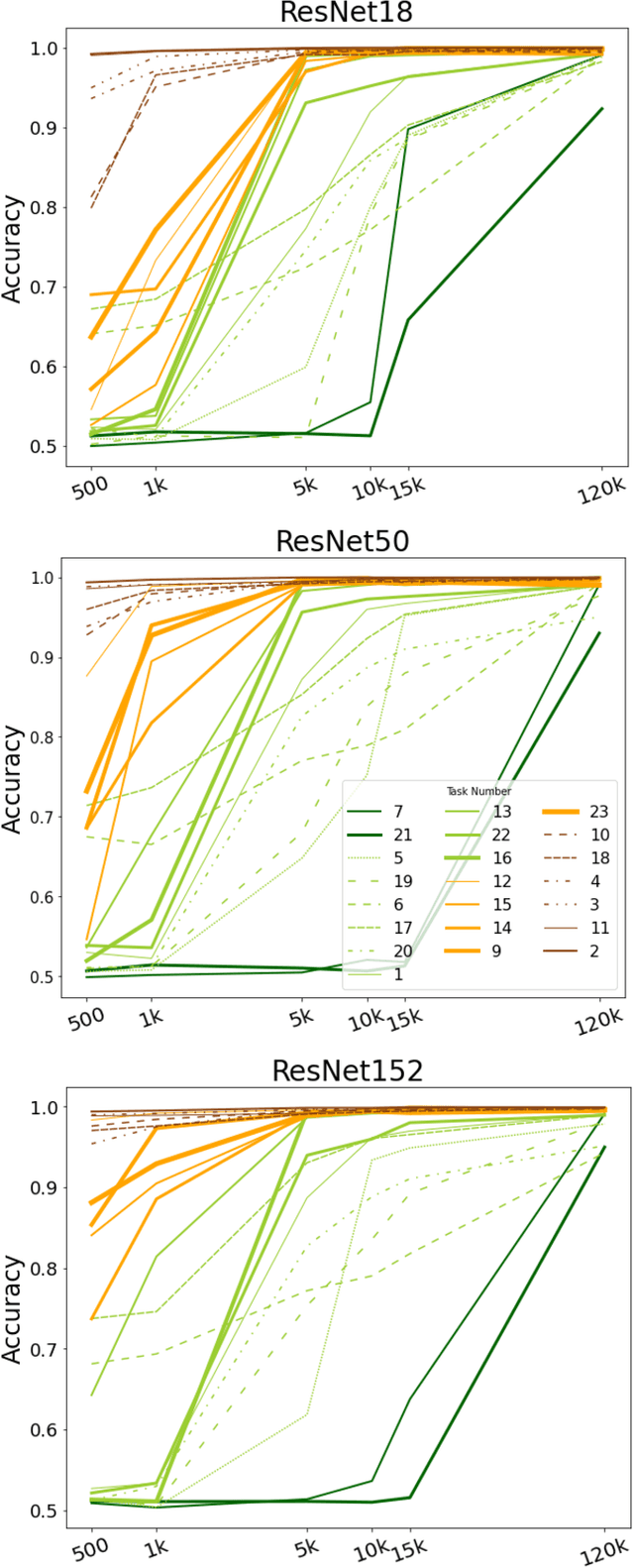
Visual understanding requires comprehending complex visual relations between objects within a scene. Here, we seek to characterize the computational demands for abstract visual reasoning. We do this by systematically assessing the ability of modern deep convolutional neural networks (CNNs) to learn to solve the Synthetic Visual Reasoning Test (SVRT) challenge, a collection of twenty-three visual reasoning problems. Our analysis leads to a novel taxonomy of visual reasoning tasks, which can be primarily explained by both the type of relations (same-different vs. spatial-relation judgments) and the number of relations used to compose the underlying rules. Prior cognitive neuroscience work suggests that attention plays a key role in human's visual reasoning ability. To test this, we extended the CNNs with spatial and feature-based attention mechanisms. In a second series of experiments, we evaluated the ability of these attention networks to learn to solve the SVRT challenge and found the resulting architectures to be much more efficient at solving the hardest of these visual reasoning tasks. Most importantly, the corresponding improvements on individual tasks partially explained the taxonomy. Overall, this work advances our understanding of visual reasoning and yields testable Neuroscience predictions regarding the need for feature-based vs. spatial attention in visual reasoning.
Beyond Question-Based Biases: Assessing Multimodal Shortcut Learning in Visual Question Answering
Apr 14, 2021
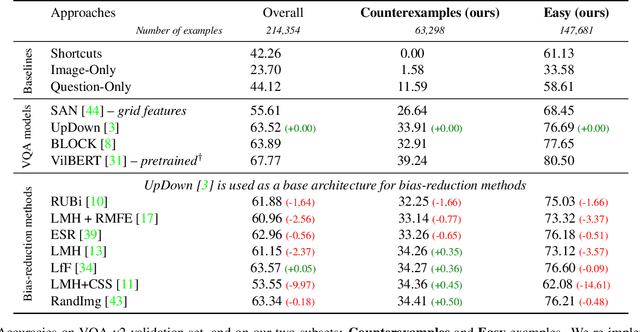


We introduce an evaluation methodology for visual question answering (VQA) to better diagnose cases of shortcut learning. These cases happen when a model exploits spurious statistical regularities to produce correct answers but does not actually deploy the desired behavior. There is a need to identify possible shortcuts in a dataset and assess their use before deploying a model in the real world. The research community in VQA has focused exclusively on question-based shortcuts, where a model might, for example, answer "What is the color of the sky" with "blue" by relying mostly on the question-conditional training prior and give little weight to visual evidence. We go a step further and consider multimodal shortcuts that involve both questions and images. We first identify potential shortcuts in the popular VQA v2 training set by mining trivial predictive rules such as co-occurrences of words and visual elements. We then create VQA-CE, a new evaluation set made of CounterExamples i.e. questions where the mined rules lead to incorrect answers. We use this new evaluation in a large-scale study of existing models. We demonstrate that even state-of-the-art models perform poorly and that existing techniques to reduce biases are largely ineffective in this context. Our findings suggest that past work on question-based biases in VQA has only addressed one facet of a complex issue. The code for our method is available at https://github.com/cdancette/detect-shortcuts
Overcoming Statistical Shortcuts for Open-ended Visual Counting
Jul 01, 2020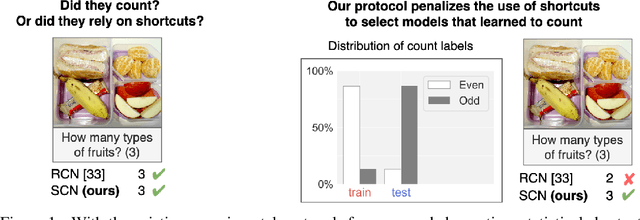



Machine learning models tend to over-rely on statistical shortcuts. These spurious correlations between parts of the input and the output labels does not hold in real-world settings. We target this issue on the recent open-ended visual counting task which is well suited to study statistical shortcuts. We aim to develop models that learn a proper mechanism of counting regardless of the output label. First, we propose the Modifying Count Distribution (MCD) protocol, which penalizes models that over-rely on statistical shortcuts. It is based on pairs of training and testing sets that do not follow the same count label distribution such as the odd-even sets. Intuitively, models that have learned a proper mechanism of counting on odd numbers should perform well on even numbers. Secondly, we introduce the Spatial Counting Network (SCN), which is dedicated to visual analysis and counting based on natural language questions. Our model selects relevant image regions, scores them with fusion and self-attention mechanisms, and provides a final counting score. We apply our protocol on the recent dataset, TallyQA, and show superior performances compared to state-of-the-art models. We also demonstrate the ability of our model to select the correct instances to count in the image. Code and datasets are available: https://github.com/cdancette/spatial-counting-network
RUBi: Reducing Unimodal Biases in Visual Question Answering
Jun 24, 2019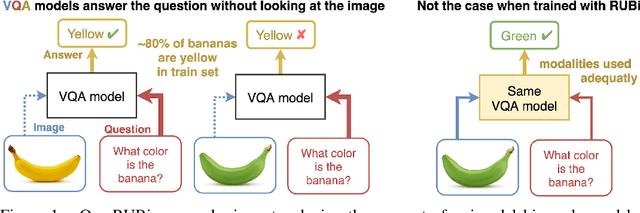
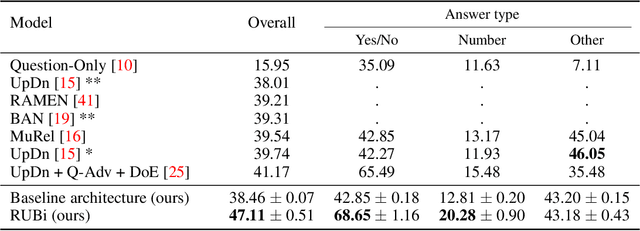
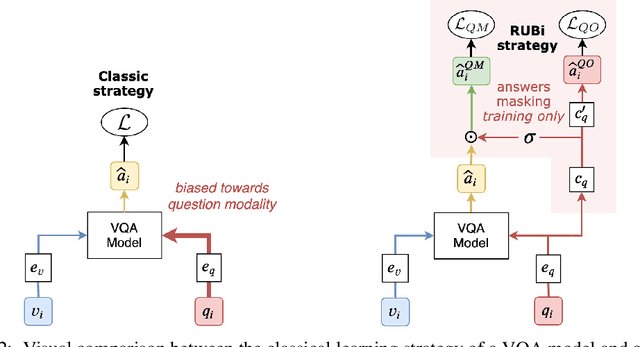
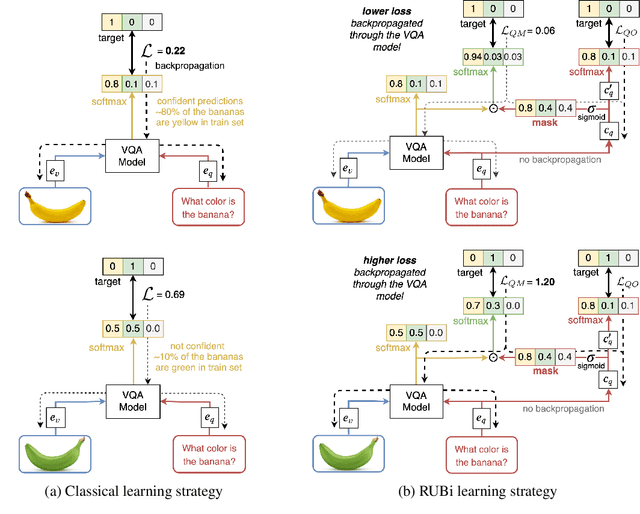
Visual Question Answering (VQA) is the task of answering questions about an image. Some VQA models often exploit unimodal biases to provide the correct answer without using the image information. As a result, they suffer from a huge drop in performance when evaluated on data outside their training set distribution. This critical issue makes them unsuitable for real-world settings. We propose RUBi, a new learning strategy to reduce biases in any VQA model. It reduces the importance of the most biased examples, i.e. examples that can be correctly classified without looking at the image. It implicitly forces the VQA model to use the two input modalities instead of relying on statistical regularities between the question and the answer. We leverage a question-only model that captures the language biases by identifying when these unwanted regularities are used. It prevents the base VQA model from learning them by influencing its predictions. This leads to dynamically adjusting the loss in order to compensate for biases. We validate our contributions by surpassing the current state-of-the-art results on VQA-CP v2. This dataset is specifically designed to assess the robustness of VQA models when exposed to different question biases at test time than what was seen during training. Our code is available: github.com/cdancette/rubi.bootstrap.pytorch
MUREL: Multimodal Relational Reasoning for Visual Question Answering
Feb 25, 2019
Multimodal attentional networks are currently state-of-the-art models for Visual Question Answering (VQA) tasks involving real images. Although attention allows to focus on the visual content relevant to the question, this simple mechanism is arguably insufficient to model complex reasoning features required for VQA or other high-level tasks. In this paper, we propose MuRel, a multimodal relational network which is learned end-to-end to reason over real images. Our first contribution is the introduction of the MuRel cell, an atomic reasoning primitive representing interactions between question and image regions by a rich vectorial representation, and modeling region relations with pairwise combinations. Secondly, we incorporate the cell into a full MuRel network, which progressively refines visual and question interactions, and can be leveraged to define visualization schemes finer than mere attention maps. We validate the relevance of our approach with various ablation studies, and show its superiority to attention-based methods on three datasets: VQA 2.0, VQA-CP v2 and TDIUC. Our final MuRel network is competitive to or outperforms state-of-the-art results in this challenging context. Our code is available: https://github.com/Cadene/murel.bootstrap.pytorch
Benchmark Analysis of Representative Deep Neural Network Architectures
Oct 19, 2018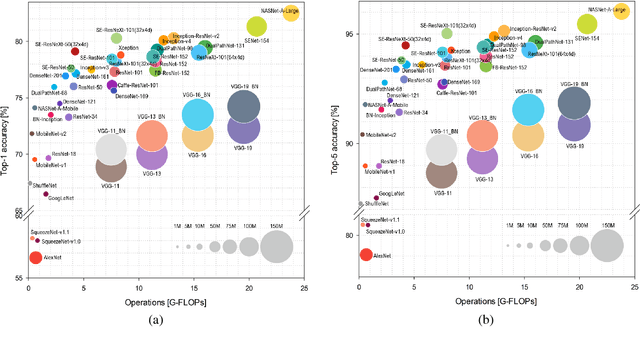
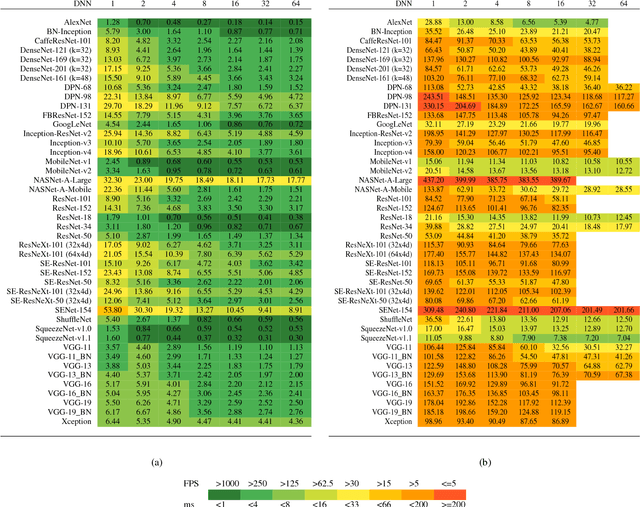
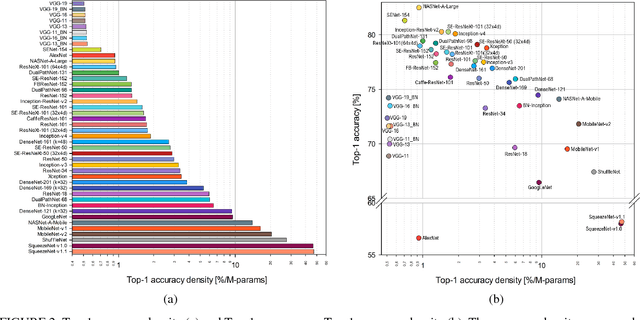
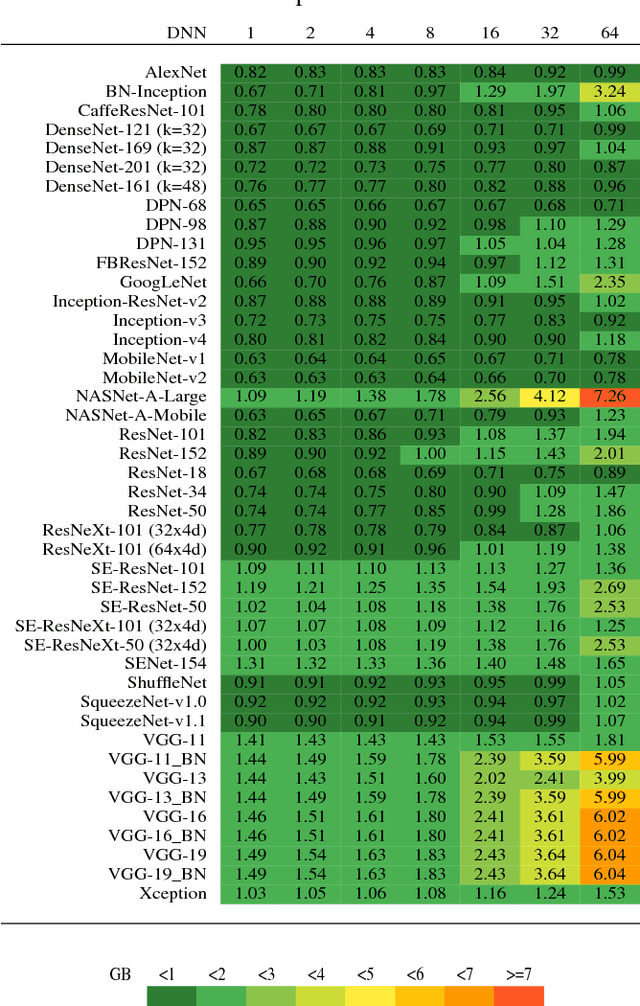
This work presents an in-depth analysis of the majority of the deep neural networks (DNNs) proposed in the state of the art for image recognition. For each DNN multiple performance indices are observed, such as recognition accuracy, model complexity, computational complexity, memory usage, and inference time. The behavior of such performance indices and some combinations of them are analyzed and discussed. To measure the indices we experiment the use of DNNs on two different computer architectures, a workstation equipped with a NVIDIA Titan X Pascal and an embedded system based on a NVIDIA Jetson TX1 board. This experimentation allows a direct comparison between DNNs running on machines with very different computational capacity. This study is useful for researchers to have a complete view of what solutions have been explored so far and in which research directions are worth exploring in the future; and for practitioners to select the DNN architecture(s) that better fit the resource constraints of practical deployments and applications. To complete this work, all the DNNs, as well as the software used for the analysis, are available online.