 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Example-Based Explainability: a Survey
Sep 05, 2023Explainable Artificial Intelligence (XAI) has become increasingly significant for improving the interpretability and trustworthiness of machine learning models. While saliency maps have stolen the show for the last few years in the XAI field, their ability to reflect models' internal processes has been questioned. Although less in the spotlight, example-based XAI methods have continued to improve. It encompasses methods that use examples as explanations for a machine learning model's predictions. This aligns with the psychological mechanisms of human reasoning and makes example-based explanations natural and intuitive for users to understand. Indeed, humans learn and reason by forming mental representations of concepts based on examples. This paper provides an overview of the state-of-the-art in natural example-based XAI, describing the pros and cons of each approach. A "natural" example simply means that it is directly drawn from the training data without involving any generative process. The exclusion of methods that require generating examples is justified by the need for plausibility which is in some regards required to gain a user's trust. Consequently, this paper will explore the following family of methods: similar examples, counterfactual and semi-factual, influential instances, prototypes, and concepts. In particular, it will compare their semantic definition, their cognitive impact, and added values. We hope it will encourage and facilitate future work on natural example-based XAI.
A survey of Identification and mitigation of Machine Learning algorithmic biases in Image Analysis
Oct 10, 2022


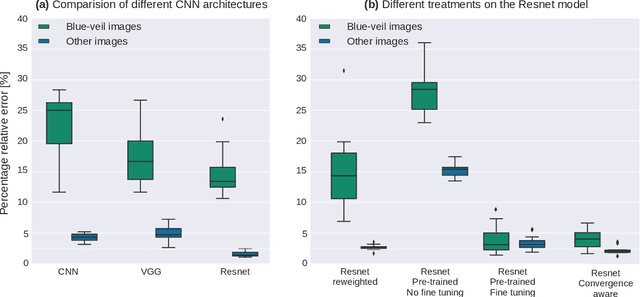
The problem of algorithmic bias in machine learning has gained a lot of attention in recent years due to its concrete and potentially hazardous implications in society. In much the same manner, biases can also alter modern industrial and safety-critical applications where machine learning are based on high dimensional inputs such as images. This issue has however been mostly left out of the spotlight in the machine learning literature. Contrarily to societal applications where a set of proxy variables can be provided by the common sense or by regulations to draw the attention on potential risks, industrial and safety-critical applications are most of the times sailing blind. The variables related to undesired biases can indeed be indirectly represented in the input data, or can be unknown, thus making them harder to tackle. This raises serious and well-founded concerns towards the commercial deployment of AI-based solutions, especially in a context where new regulations clearly address the issues opened by undesired biases in AI. Consequently, we propose here to make an overview of recent advances in this area, firstly by presenting how such biases can demonstrate themselves, then by exploring different ways to bring them to light, and by probing different possibilities to mitigate them. We finally present a practical remote sensing use-case of industrial Fairness.
Xplique: A Deep Learning Explainability Toolbox
Jun 09, 2022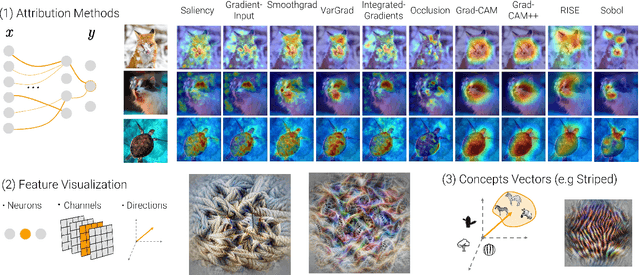
Today's most advanced machine-learning models are hardly scrutable. The key challenge for explainability methods is to help assisting researchers in opening up these black boxes, by revealing the strategy that led to a given decision, by characterizing their internal states or by studying the underlying data representation. To address this challenge, we have developed Xplique: a software library for explainability which includes representative explainability methods as well as associated evaluation metrics. It interfaces with one of the most popular learning libraries: Tensorflow as well as other libraries including PyTorch, scikit-learn and Theano. The code is licensed under the MIT license and is freely available at github.com/deel-ai/xplique.