 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Data Manifold Geometry via Non-Contracting Flows
Feb 02, 2026We introduce an unsupervised approach for constructing a global reference system by learning, in the ambient space, vector fields that span the tangent spaces of an unknown data manifold. In contrast to isometric objectives, which implicitly assume manifold flatness, our method learns tangent vector fields whose flows transport all samples to a common, learnable reference point. The resulting arc-lengths along these flows define interpretable intrinsic coordinates tied to a shared global frame. To prevent degenerate collapse, we enforce a non-shrinking constraint and derive a scalable, integration-free objective inspired by flow matching. Within our theoretical framework, we prove that minimizing the proposed objective recovers a global coordinate chart when one exists. Empirically, we obtain correct tangent alignment and coherent global coordinate structure on synthetic manifolds. We also demonstrate the scalability of our method on CIFAR-10, where the learned coordinates achieve competitive downstream classification performance.
Follow the Energy, Find the Path: Riemannian Metrics from Energy-Based Models
May 23, 2025What is the shortest path between two data points lying in a high-dimensional space? While the answer is trivial in Euclidean geometry, it becomes significantly more complex when the data lies on a curved manifold -- requiring a Riemannian metric to describe the space's local curvature. Estimating such a metric, however, remains a major challenge in high dimensions. In this work, we propose a method for deriving Riemannian metrics directly from pretrained Energy-Based Models (EBMs) -- a class of generative models that assign low energy to high-density regions. These metrics define spatially varying distances, enabling the computation of geodesics -- shortest paths that follow the data manifold's intrinsic geometry. We introduce two novel metrics derived from EBMs and show that they produce geodesics that remain closer to the data manifold and exhibit lower curvature distortion, as measured by alignment with ground-truth trajectories. We evaluate our approach on increasingly complex datasets: synthetic datasets with known data density, rotated character images with interpretable geometry, and high-resolution natural images embedded in a pretrained VAE latent space. Our results show that EBM-derived metrics consistently outperform established baselines, especially in high-dimensional settings. Our work is the first to derive Riemannian metrics from EBMs, enabling data-aware geodesics and unlocking scalable, geometry-driven learning for generative modeling and simulation.
Deep Sturm--Liouville: From Sample-Based to 1D Regularization with Learnable Orthogonal Basis Functions
Apr 09, 2025Although Artificial Neural Networks (ANNs) have achieved remarkable success across various tasks, they still suffer from limited generalization. We hypothesize that this limitation arises from the traditional sample-based (0--dimensionnal) regularization used in ANNs. To overcome this, we introduce \textit{Deep Sturm--Liouville} (DSL), a novel function approximator that enables continuous 1D regularization along field lines in the input space by integrating the Sturm--Liouville Theorem (SLT) into the deep learning framework. DSL defines field lines traversing the input space, along which a Sturm--Liouville problem is solved to generate orthogonal basis functions, enforcing implicit regularization thanks to the desirable properties of SLT. These basis functions are linearly combined to construct the DSL approximator. Both the vector field and basis functions are parameterized by neural networks and learned jointly. We demonstrate that the DSL formulation naturally arises when solving a Rank-1 Parabolic Eigenvalue Problem. DSL is trained efficiently using stochastic gradient descent via implicit differentiation. DSL achieves competitive performance and demonstrate improved sample efficiency on diverse multivariate datasets including high-dimensional image datasets such as MNIST and CIFAR-10.
How to design a dataset compliant with an ML-based system ODD?
Jun 20, 2024This paper focuses on a Vision-based Landing task and presents the design and the validation of a dataset that would comply with the Operational Design Domain (ODD) of a Machine-Learning (ML) system. Relying on emerging certification standards, we describe the process for establishing ODDs at both the system and image levels. In the process, we present the translation of high-level system constraints into actionable image-level properties, allowing for the definition of verifiable Data Quality Requirements (DQRs). To illustrate this approach, we use the Landing Approach Runway Detection (LARD) dataset which combines synthetic imagery and real footage, and we focus on the steps required to verify the DQRs. The replicable framework presented in this paper addresses the challenges of designing a dataset compliant with the stringent needs of ML-based systems certification in safety-critical applications.
DP-SGD Without Clipping: The Lipschitz Neural Network Way
May 25, 2023



State-of-the-art approaches for training Differentially Private (DP) Deep Neural Networks (DNN) faces difficulties to estimate tight bounds on the sensitivity of the network's layers, and instead rely on a process of per-sample gradient clipping. This clipping process not only biases the direction of gradients but also proves costly both in memory consumption and in computation. To provide sensitivity bounds and bypass the drawbacks of the clipping process, our theoretical analysis of Lipschitz constrained networks reveals an unexplored link between the Lipschitz constant with respect to their input and the one with respect to their parameters. By bounding the Lipschitz constant of each layer with respect to its parameters we guarantee DP training of these networks. This analysis not only allows the computation of the aforementioned sensitivities at scale but also provides leads on to how maximize the gradient-to-noise ratio for fixed privacy guarantees. To facilitate the application of Lipschitz networks and foster robust and certifiable learning under privacy guarantees, we provide a Python package that implements building blocks allowing the construction and private training of such networks.
CRAFT: Concept Recursive Activation FacTorization for Explainability
Nov 17, 2022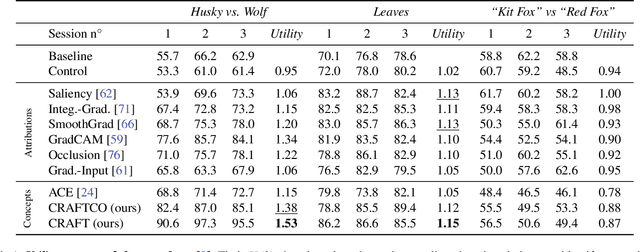

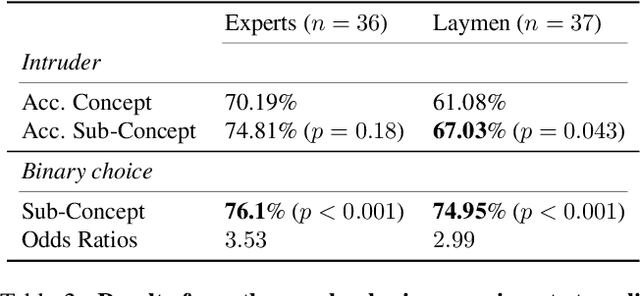
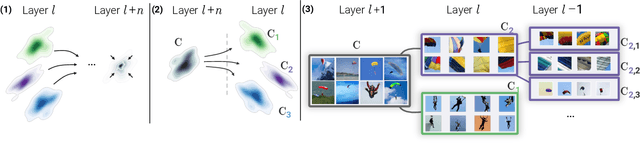
Attribution methods are a popular class of explainability methods that use heatmaps to depict the most important areas of an image that drive a model decision. Nevertheless, recent work has shown that these methods have limited utility in practice, presumably because they only highlight the most salient parts of an image (i.e., 'where' the model looked) and do not communicate any information about 'what' the model saw at those locations. In this work, we try to fill in this gap with CRAFT -- a novel approach to identify both 'what' and 'where' by generating concept-based explanations. We introduce 3 new ingredients to the automatic concept extraction literature: (i) a recursive strategy to detect and decompose concepts across layers, (ii) a novel method for a more faithful estimation of concept importance using Sobol indices, and (iii) the use of implicit differentiation to unlock Concept Attribution Maps. We conduct both human and computer vision experiments to demonstrate the benefits of the proposed approach. We show that our recursive decomposition generates meaningful and accurate concepts and that the proposed concept importance estimation technique is more faithful to the model than previous methods. When evaluating the usefulness of the method for human experimenters on a human-defined utility benchmark, we find that our approach significantly improves on two of the three test scenarios (while none of the current methods including ours help on the third). Overall, our study suggests that, while much work remains toward the development of general explainability methods that are useful in practical scenarios, the identification of meaningful concepts at the proper level of granularity yields useful and complementary information beyond that afforded by attribution methods.
Efficient circuit implementation for coined quantum walks on binary trees and application to reinforcement learning
Oct 14, 2022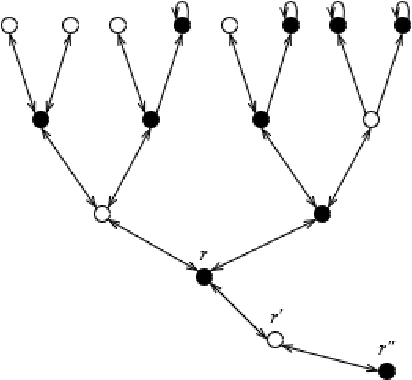
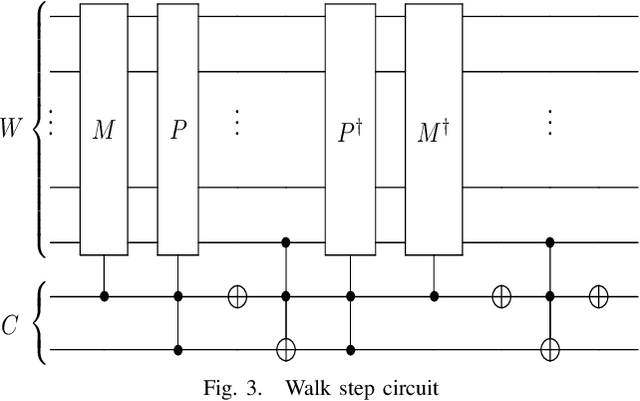
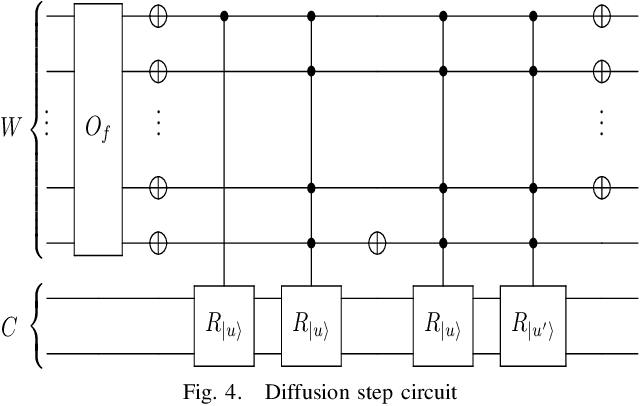
Quantum walks on binary trees are used in many quantum algorithms to achieve important speedup over classical algorithms. The formulation of this kind of algorithms as quantum circuit presents the advantage of being easily readable, executable on circuit based quantum computers and simulators and optimal on the usage of resources. We propose a strategy to compose quantum circuit that performs quantum walk on binary trees following universal gate model quantum computation principles. We give a particular attention to NAND formula evaluation algorithm as it could have many applications in game theory and reinforcement learning. We therefore propose an application of this algorithm and show how it can be used to train a quantum reinforcement learning agent in a two player game environment.
Making Sense of Dependence: Efficient Black-box Explanations Using Dependence Measure
Jun 13, 2022
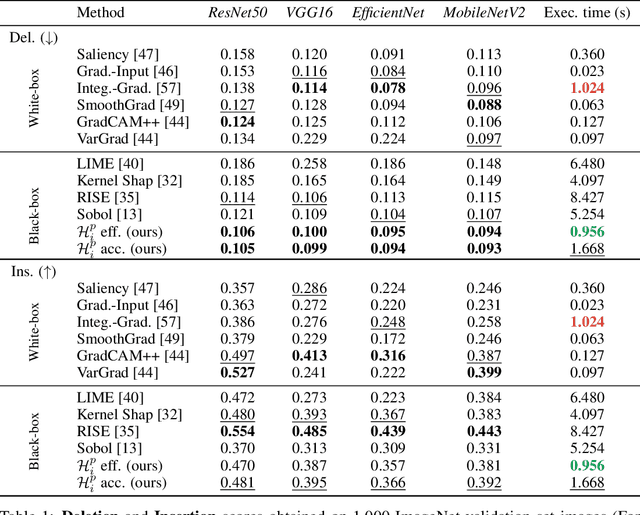


This paper presents a new efficient black-box attribution method based on Hilbert-Schmidt Independence Criterion (HSIC), a dependence measure based on Reproducing Kernel Hilbert Spaces (RKHS). HSIC measures the dependence between regions of an input image and the output of a model based on kernel embeddings of distributions. It thus provides explanations enriched by RKHS representation capabilities. HSIC can be estimated very efficiently, significantly reducing the computational cost compared to other black-box attribution methods. Our experiments show that HSIC is up to 8 times faster than the previous best black-box attribution methods while being as faithful. Indeed, we improve or match the state-of-the-art of both black-box and white-box attribution methods for several fidelity metrics on Imagenet with various recent model architectures. Importantly, we show that these advances can be transposed to efficiently and faithfully explain object detection models such as YOLOv4. Finally, we extend the traditional attribution methods by proposing a new kernel enabling an orthogonal decomposition of importance scores based on HSIC, allowing us to evaluate not only the importance of each image patch but also the importance of their pairwise interactions.
Xplique: A Deep Learning Explainability Toolbox
Jun 09, 2022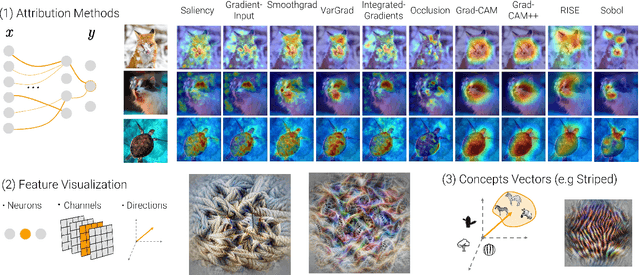
Today's most advanced machine-learning models are hardly scrutable. The key challenge for explainability methods is to help assisting researchers in opening up these black boxes, by revealing the strategy that led to a given decision, by characterizing their internal states or by studying the underlying data representation. To address this challenge, we have developed Xplique: a software library for explainability which includes representative explainability methods as well as associated evaluation metrics. It interfaces with one of the most popular learning libraries: Tensorflow as well as other libraries including PyTorch, scikit-learn and Theano. The code is licensed under the MIT license and is freely available at github.com/deel-ai/xplique.
Don't Lie to Me! Robust and Efficient Explainability with Verified Perturbation Analysis
Feb 15, 2022A variety of methods have been proposed to try to explain how deep neural networks make their decisions. Key to those approaches is the need to sample the pixel space efficiently in order to derive importance maps. However, it has been shown that the sampling methods used to date introduce biases and other artifacts, leading to inaccurate estimates of the importance of individual pixels and severely limit the reliability of current explainability methods. Unfortunately, the alternative -- to exhaustively sample the image space is computationally prohibitive. In this paper, we introduce EVA (Explaining using Verified perturbation Analysis) -- the first explainability method guarantee to have an exhaustive exploration of a perturbation space. Specifically, we leverage the beneficial properties of verified perturbation analysis -- time efficiency, tractability and guaranteed complete coverage of a manifold -- to efficiently characterize the input variables that are most likely to drive the model decision. We evaluate the approach systematically and demonstrate state-of-the-art results on multiple benchmarks.