 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAME: Formal Abstract Minimal Explanation for Neural Networks
Mar 11, 2026We propose FAME (Formal Abstract Minimal Explanations), a new class of abductive explanations grounded in abstract interpretation. FAME is the first method to scale to large neural networks while reducing explanation size. Our main contribution is the design of dedicated perturbation domains that eliminate the need for traversal order. FAME progressively shrinks these domains and leverages LiRPA-based bounds to discard irrelevant features, ultimately converging to a formal abstract minimal explanation. To assess explanation quality, we introduce a procedure that measures the worst-case distance between an abstract minimal explanation and a true minimal explanation. This procedure combines adversarial attacks with an optional VERIX+ refinement step. We benchmark FAME against VERIX+ and demonstrate consistent gains in both explanation size and runtime on medium- to large-scale neural networks.
Don't Lie to Me! Robust and Efficient Explainability with Verified Perturbation Analysis
Feb 15, 2022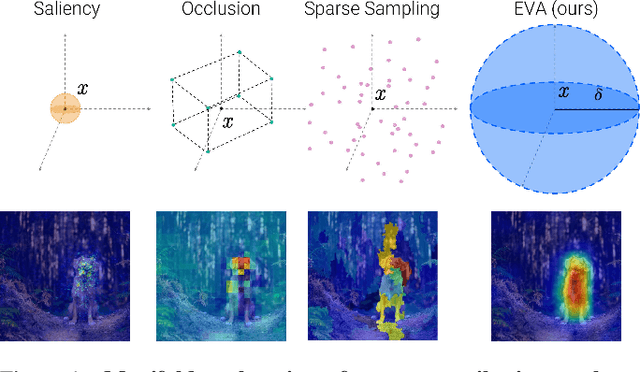
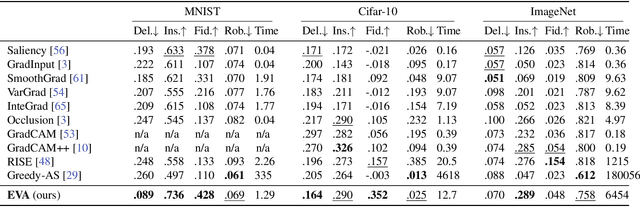
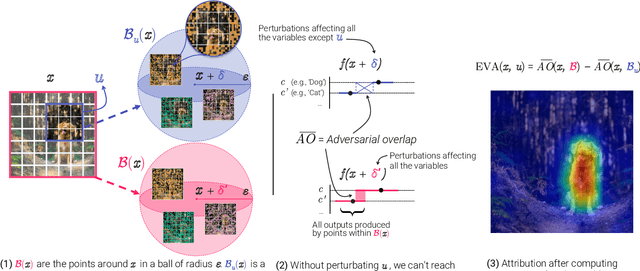
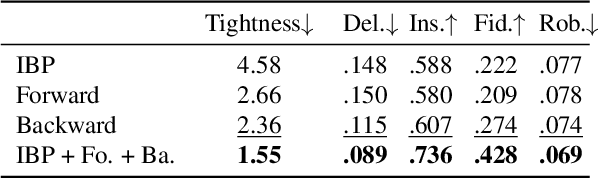
A variety of methods have been proposed to try to explain how deep neural networks make their decisions. Key to those approaches is the need to sample the pixel space efficiently in order to derive importance maps. However, it has been shown that the sampling methods used to date introduce biases and other artifacts, leading to inaccurate estimates of the importance of individual pixels and severely limit the reliability of current explainability methods. Unfortunately, the alternative -- to exhaustively sample the image space is computationally prohibitive. In this paper, we introduce EVA (Explaining using Verified perturbation Analysis) -- the first explainability method guarantee to have an exhaustive exploration of a perturbation space. Specifically, we leverage the beneficial properties of verified perturbation analysis -- time efficiency, tractability and guaranteed complete coverage of a manifold -- to efficiently characterize the input variables that are most likely to drive the model decision. We evaluate the approach systematically and demonstrate state-of-the-art results on multiple benchmarks.
Adversarial Active Learning for Deep Networks: a Margin Based Approach
Feb 27, 2018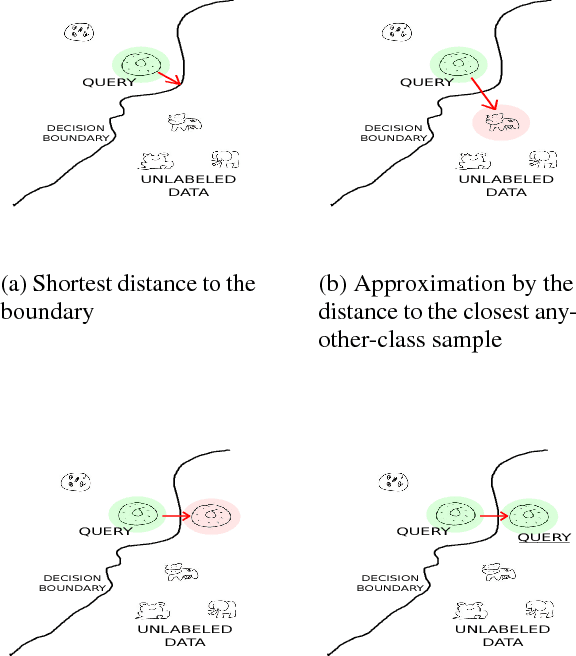
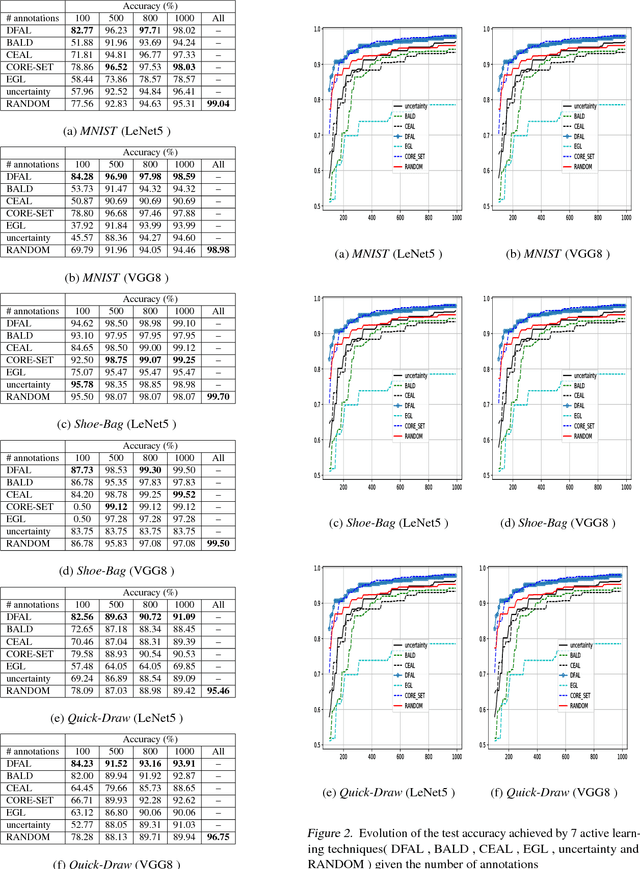
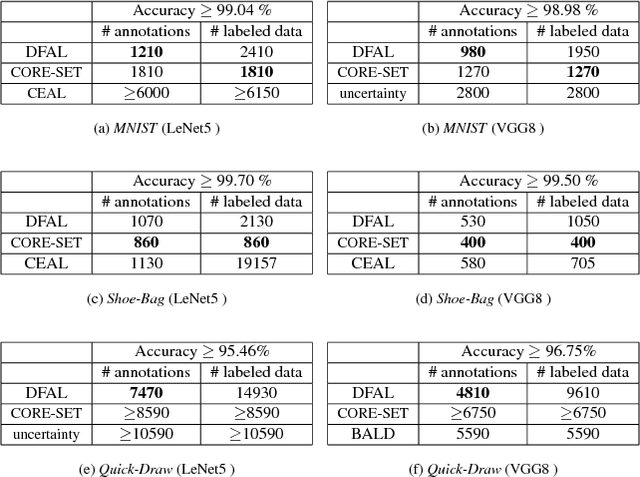

We propose a new active learning strategy designed for deep neural networks. The goal is to minimize the number of data annotation queried from an oracle during training. Previous active learning strategies scalable for deep networks were mostly based on uncertain sample selection. In this work, we focus on examples lying close to the decision boundary. Based on theoretical works on margin theory for active learning, we know that such examples may help to considerably decrease the number of annotations. While measuring the exact distance to the decision boundaries is intractable, we propose to rely on adversarial examples. We do not consider anymore them as a threat instead we exploit the information they provide on the distribution of the input space in order to approximate the distance to decision boundaries. We demonstrate empirically that adversarial active queries yield faster convergence of CNNs trained on MNIST, the Shoe-Bag and the Quick-Draw datasets.
QBDC: Query by dropout committee for training deep supervised architecture
Nov 26, 2015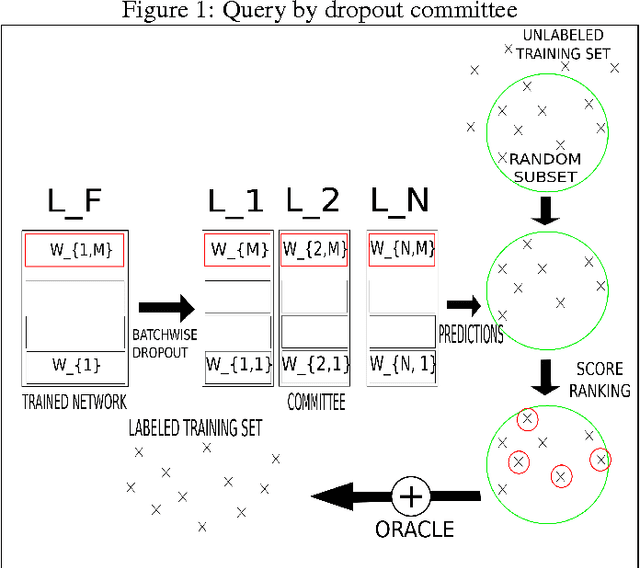

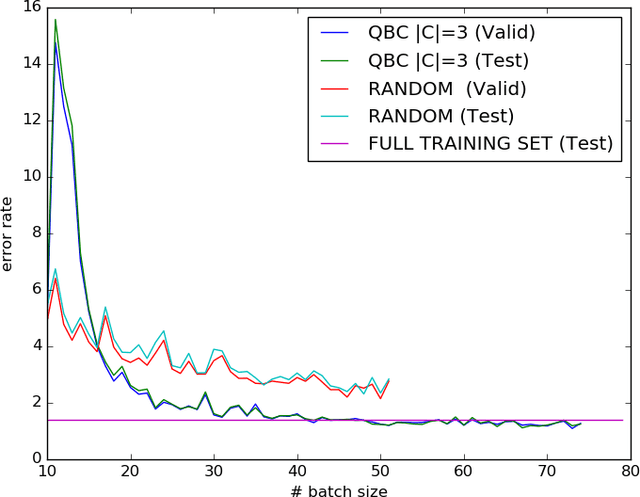

While the current trend is to increase the depth of neural networks to increase their performance, the size of their training database has to grow accordingly. We notice an emergence of tremendous databases, although providing labels to build a training set still remains a very expensive task. We tackle the problem of selecting the samples to be labelled in an online fashion. In this paper, we present an active learning strategy based on query by committee and dropout technique to train a Convolutional Neural Network (CNN). We derive a commmittee of partial CNNs resulting from batchwise dropout runs on the initial CNN. We evaluate our active learning strategy for CNN on MNIST benchmark, showing in particular that selecting less than 30 % from the annotated database is enough to get similar error rate as using the full training set on MNIST. We also studied the robustness of our method against adversarial examples.