 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonium : A Unified, Efficient Library of Orthogonal and 1-Lipschitz Building Blocks
Jan 20, 2026Orthogonal and 1-Lipschitz neural network layers are essential building blocks in robust deep learning architectures, crucial for certified adversarial robustness, stable generative models, and reliable recurrent networks. Despite significant advancements, existing implementations remain fragmented, limited, and computationally demanding. To address these issues, we introduce Orthogonium , a unified, efficient, and comprehensive PyTorch library providing orthogonal and 1-Lipschitz layers. Orthogonium provides access to standard convolution features-including support for strides, dilation, grouping, and transposed-while maintaining strict mathematical guarantees. Its optimized implementations reduce overhead on large scale benchmarks such as ImageNet. Moreover, rigorous testing within the library has uncovered critical errors in existing implementations, emphasizing the importance of standardized and reliable tools. Orthogonium thus significantly lowers adoption barriers, enabling scalable experimentation and integration across diverse applications requiring orthogonality and robust Lipschitz constraints. Orthogonium is available at https://github.com/deel-ai/orthogonium.
Efficient Robust Conformal Prediction via Lipschitz-Bounded Networks
Jun 05, 2025



Conformal Prediction (CP) has proven to be an effective post-hoc method for improving the trustworthiness of neural networks by providing prediction sets with finite-sample guarantees. However, under adversarial attacks, classical conformal guarantees do not hold anymore: this problem is addressed in the field of Robust Conformal Prediction. Several methods have been proposed to provide robust CP sets with guarantees under adversarial perturbations, but, for large scale problems, these sets are either too large or the methods are too computationally demanding to be deployed in real life scenarios. In this work, we propose a new method that leverages Lipschitz-bounded networks to precisely and efficiently estimate robust CP sets. When combined with a 1-Lipschitz robust network, we demonstrate that our lip-rcp method outperforms state-of-the-art results in both the size of the robust CP sets and computational efficiency in medium and large-scale scenarios such as ImageNet. Taking a different angle, we also study vanilla CP under attack, and derive new worst-case coverage bounds of vanilla CP sets, which are valid simultaneously for all adversarial attack levels. Our lip-rcp method makes this second approach as efficient as vanilla CP while also allowing robustness guarantees.
An Adaptive Orthogonal Convolution Scheme for Efficient and Flexible CNN Architectures
Jan 14, 2025



Orthogonal convolutional layers are the workhorse of multiple areas in machine learning, such as adversarial robustness, normalizing flows, GANs, and Lipschitzconstrained models. Their ability to preserve norms and ensure stable gradient propagation makes them valuable for a large range of problems. Despite their promise, the deployment of orthogonal convolution in large-scale applications is a significant challenge due to computational overhead and limited support for modern features like strides, dilations, group convolutions, and transposed convolutions.In this paper, we introduce AOC (Adaptative Orthogonal Convolution), a scalable method for constructing orthogonal convolutions, effectively overcoming these limitations. This advancement unlocks the construction of architectures that were previously considered impractical. We demonstrate through our experiments that our method produces expressive models that become increasingly efficient as they scale. To foster further advancement, we provide an open-source library implementing this method, available at https://github.com/thib-s/orthogonium.
How to design a dataset compliant with an ML-based system ODD?
Jun 20, 2024This paper focuses on a Vision-based Landing task and presents the design and the validation of a dataset that would comply with the Operational Design Domain (ODD) of a Machine-Learning (ML) system. Relying on emerging certification standards, we describe the process for establishing ODDs at both the system and image levels. In the process, we present the translation of high-level system constraints into actionable image-level properties, allowing for the definition of verifiable Data Quality Requirements (DQRs). To illustrate this approach, we use the Landing Approach Runway Detection (LARD) dataset which combines synthetic imagery and real footage, and we focus on the steps required to verify the DQRs. The replicable framework presented in this paper addresses the challenges of designing a dataset compliant with the stringent needs of ML-based systems certification in safety-critical applications.
Quantized Approximately Orthogonal Recurrent Neural Networks
Feb 05, 2024



Orthogonal recurrent neural networks (ORNNs) are an appealing option for learning tasks involving time series with long-term dependencies, thanks to their simplicity and computational stability. However, these networks often require a substantial number of parameters to perform well, which can be prohibitive in power-constrained environments, such as compact devices. One approach to address this issue is neural network quantization. The construction of such networks remains an open problem, acknowledged for its inherent instability.In this paper, we explore the quantization of the recurrent and input weight matrices in ORNNs, leading to Quantized approximately Orthogonal RNNs (QORNNs). We investigate one post-training quantization (PTQ) strategy and three quantization-aware training (QAT) algorithms that incorporate orthogonal constraints and quantized weights. Empirical results demonstrate the advantages of employing QAT over PTQ. The most efficient model achieves results similar to state-of-the-art full-precision ORNN and LSTM on a variety of standard benchmarks, even with 3-bits quantization.
DP-SGD Without Clipping: The Lipschitz Neural Network Way
May 25, 2023



State-of-the-art approaches for training Differentially Private (DP) Deep Neural Networks (DNN) faces difficulties to estimate tight bounds on the sensitivity of the network's layers, and instead rely on a process of per-sample gradient clipping. This clipping process not only biases the direction of gradients but also proves costly both in memory consumption and in computation. To provide sensitivity bounds and bypass the drawbacks of the clipping process, our theoretical analysis of Lipschitz constrained networks reveals an unexplored link between the Lipschitz constant with respect to their input and the one with respect to their parameters. By bounding the Lipschitz constant of each layer with respect to its parameters we guarantee DP training of these networks. This analysis not only allows the computation of the aforementioned sensitivities at scale but also provides leads on to how maximize the gradient-to-noise ratio for fixed privacy guarantees. To facilitate the application of Lipschitz networks and foster robust and certifiable learning under privacy guarantees, we provide a Python package that implements building blocks allowing the construction and private training of such networks.
When adversarial attacks become interpretable counterfactual explanations
Jun 14, 2022
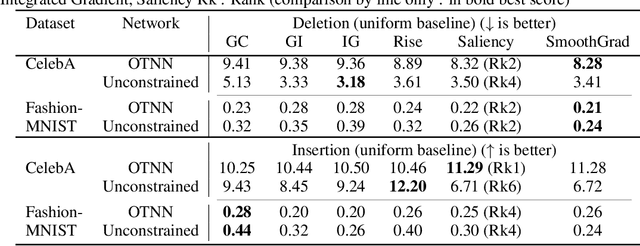
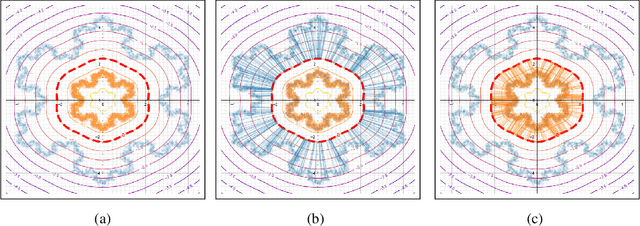
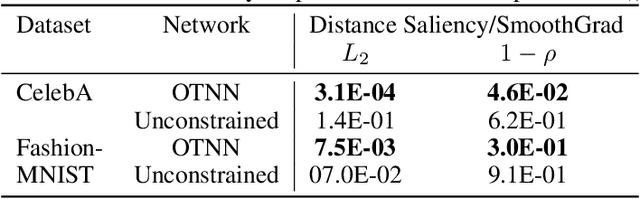
We argue that, when learning a 1-Lipschitz neural network with the dual loss of an optimal transportation problem, the gradient of the model is both the direction of the transportation plan and the direction to the closest adversarial attack. Traveling along the gradient to the decision boundary is no more an adversarial attack but becomes a counterfactual explanation, explicitly transporting from one class to the other. Through extensive experiments on XAI metrics, we find that the simple saliency map method, applied on such networks, becomes a reliable explanation, and outperforms the state-of-the-art explanation approaches on unconstrained models. The proposed networks were already known to be certifiably robust, and we prove that they are also explainable with a fast and simple method.
The Many Faces of 1-Lipschitz Neural Networks
Apr 13, 2021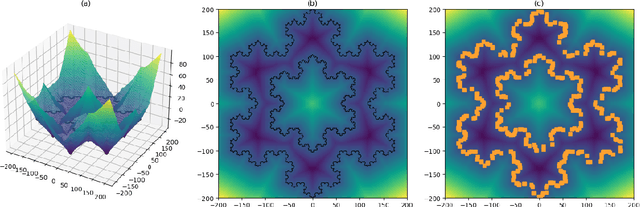
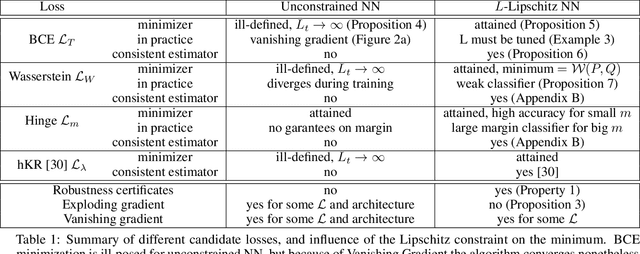
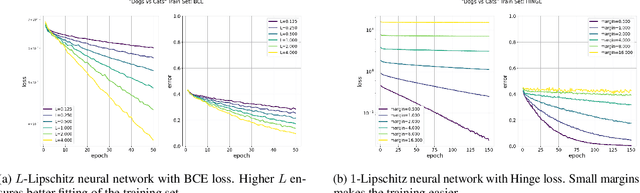
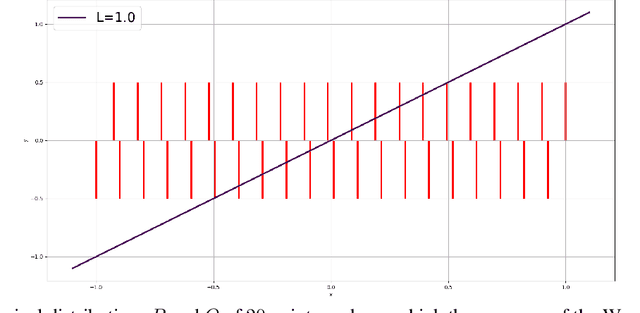
Lipschitz constrained models have been used to solve specifics deep learning problems such as the estimation of Wasserstein distance for GAN, or the training of neural networks robust to adversarial attacks. Regardless the novel and effective algorithms to build such 1-Lipschitz networks, their usage remains marginal, and they are commonly considered as less expressive and less able to fit properly the data than their unconstrained counterpart. The goal of the paper is to demonstrate that, despite being empirically harder to train, 1-Lipschitz neural networks are theoretically better grounded than unconstrained ones when it comes to classification. To achieve that we recall some results about 1-Lipschitz function in the scope of deep learning and we extend and illustrate them to derive general properties for classification. First, we show that 1-Lipschitz neural network can fit arbitrarily difficult frontier making them as expressive as classical ones. When minimizing the log loss, we prove that the optimization problem under Lipschitz constraint is well posed and have a minimum, whereas regular neural networks can diverge even on remarkably simple situations. Then, we study the link between classification with 1-Lipschitz network and optimal transport thanks to regularized versions of Kantorovich-Rubinstein duality theory. Last, we derive preliminary bounds on their VC dimension.
White Paper Machine Learning in Certified Systems
Mar 18, 2021

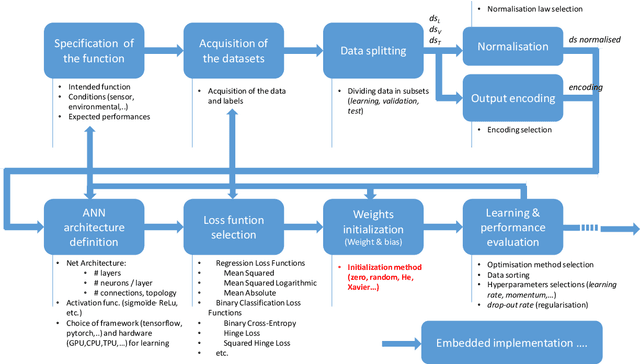
Machine Learning (ML) seems to be one of the most promising solution to automate partially or completely some of the complex tasks currently realized by humans, such as driving vehicles, recognizing voice, etc. It is also an opportunity to implement and embed new capabilities out of the reach of classical implementation techniques. However, ML techniques introduce new potential risks. Therefore, they have only been applied in systems where their benefits are considered worth the increase of risk. In practice, ML techniques raise multiple challenges that could prevent their use in systems submitted to certification constraints. But what are the actual challenges? Can they be overcome by selecting appropriate ML techniques, or by adopting new engineering or certification practices? These are some of the questions addressed by the ML Certification 3 Workgroup (WG) set-up by the Institut de Recherche Technologique Saint Exup\'ery de Toulouse (IRT), as part of the DEEL Project.
Achieving robustness in classification using optimal transport with hinge regularization
Jun 11, 2020
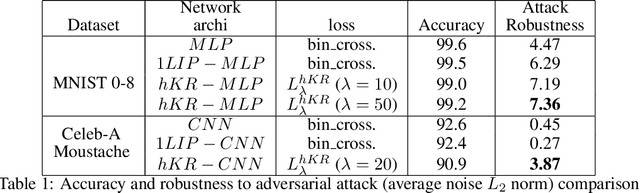
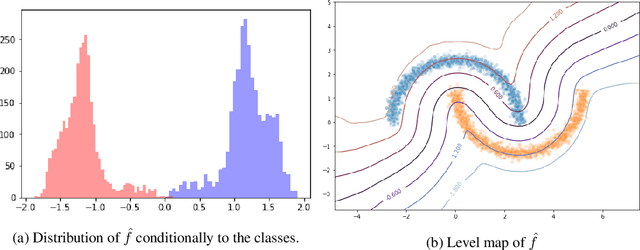
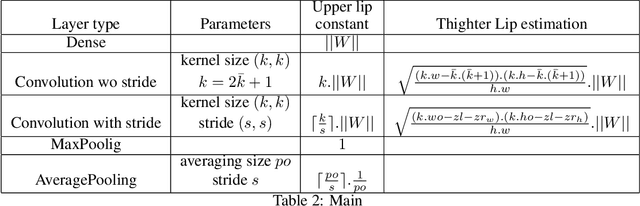
We propose a new framework for robust binary classification, with Deep Neural Networks, based on a hinge regularization of the Kantorovich-Rubinstein dual formulation for the estimation of the Wasserstein distance. The robustness of the approach is guaranteed by the strict Lipschitz constraint on functions required by the optimization problem and direct interpretation of the loss in terms of adversarial robustness. We prove that this classification formulation has a solution, and is still the dual formulation of an optimal transportation problem. We also establish the geometrical properties of this optimal solution. We summarize state-of-the-art methods to enforce Lipschitz constraints on neural networks and we propose new ones for convolutional networks (associated with an open source library for this purpose). The experiments show that the approach provides the expected guarantees in terms of robustness without any significant accuracy drop. The results also suggest that adversarial attacks on the proposed models visibly and meaningfully change the input, and can thus serve as an explanation for the classification.