 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Many Faces of 1-Lipschitz Neural Networks
Paper and Code
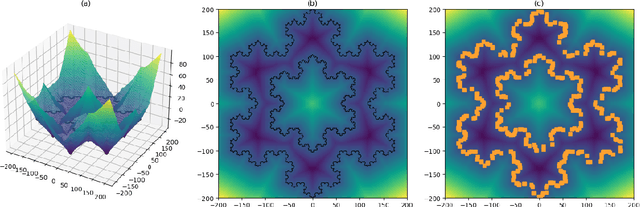
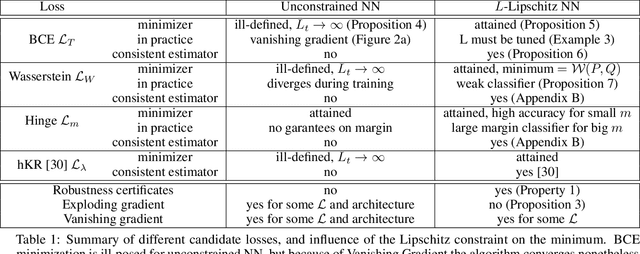
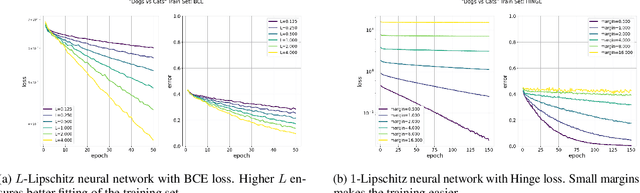
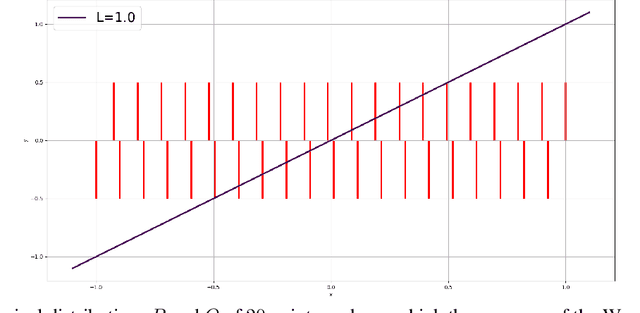
Lipschitz constrained models have been used to solve specifics deep learning problems such as the estimation of Wasserstein distance for GAN, or the training of neural networks robust to adversarial attacks. Regardless the novel and effective algorithms to build such 1-Lipschitz networks, their usage remains marginal, and they are commonly considered as less expressive and less able to fit properly the data than their unconstrained counterpart. The goal of the paper is to demonstrate that, despite being empirically harder to train, 1-Lipschitz neural networks are theoretically better grounded than unconstrained ones when it comes to classification. To achieve that we recall some results about 1-Lipschitz function in the scope of deep learning and we extend and illustrate them to derive general properties for classification. First, we show that 1-Lipschitz neural network can fit arbitrarily difficult frontier making them as expressive as classical ones. When minimizing the log loss, we prove that the optimization problem under Lipschitz constraint is well posed and have a minimum, whereas regular neural networks can diverge even on remarkably simple situations. Then, we study the link between classification with 1-Lipschitz network and optimal transport thanks to regularized versions of Kantorovich-Rubinstein duality theory. Last, we derive preliminary bounds on their VC dimension.