 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to the Baseline: Examining Baseline Effects on Explainability Metrics
Dec 12, 2025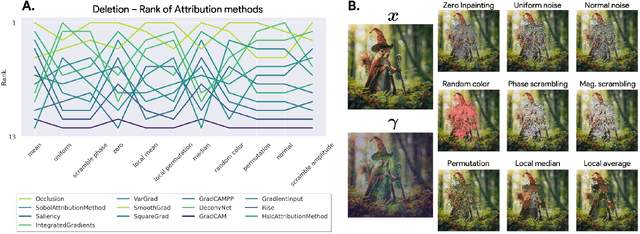
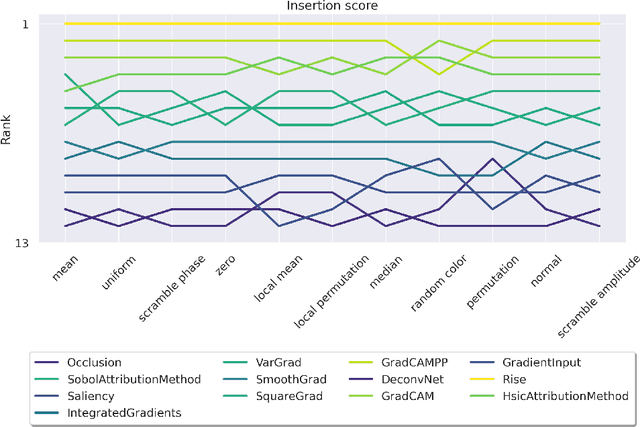
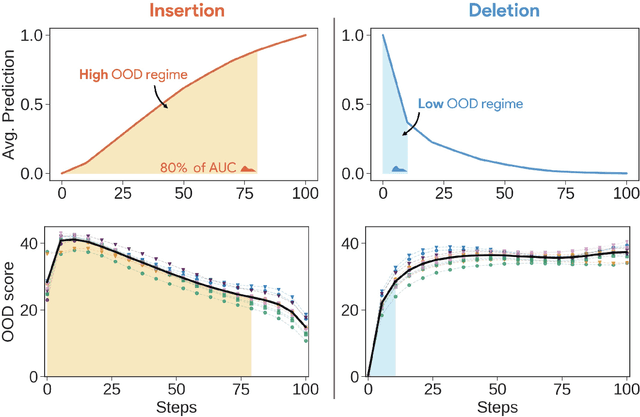
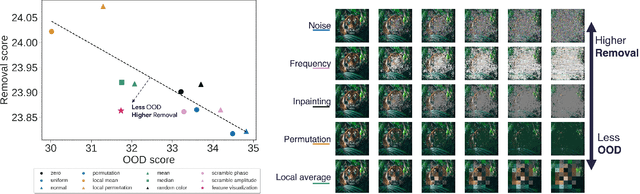
Attribution methods are among the most prevalent techniques in Explainable Artificial Intelligence (XAI) and are usually evaluated and compared using Fidelity metrics, with Insertion and Deletion being the most popular. These metrics rely on a baseline function to alter the pixels of the input image that the attribution map deems most important. In this work, we highlight a critical problem with these metrics: the choice of a given baseline will inevitably favour certain attribution methods over others. More concerningly, even a simple linear model with commonly used baselines contradicts itself by designating different optimal methods. A question then arises: which baseline should we use? We propose to study this problem through two desirable properties of a baseline: (i) that it removes information and (ii) that it does not produce overly out-of-distribution (OOD) images. We first show that none of the tested baselines satisfy both criteria, and there appears to be a trade-off among current baselines: either they remove information or they produce a sequence of OOD images. Finally, we introduce a novel baseline by leveraging recent work in feature visualisation to artificially produce a model-dependent baseline that removes information without being overly OOD, thus improving on the trade-off when compared to other existing baselines. Our code is available at https://github.com/deel-ai-papers/Back-to-the-Baseline
An Adaptive Orthogonal Convolution Scheme for Efficient and Flexible CNN Architectures
Jan 14, 2025



Orthogonal convolutional layers are the workhorse of multiple areas in machine learning, such as adversarial robustness, normalizing flows, GANs, and Lipschitzconstrained models. Their ability to preserve norms and ensure stable gradient propagation makes them valuable for a large range of problems. Despite their promise, the deployment of orthogonal convolution in large-scale applications is a significant challenge due to computational overhead and limited support for modern features like strides, dilations, group convolutions, and transposed convolutions.In this paper, we introduce AOC (Adaptative Orthogonal Convolution), a scalable method for constructing orthogonal convolutions, effectively overcoming these limitations. This advancement unlocks the construction of architectures that were previously considered impractical. We demonstrate through our experiments that our method produces expressive models that become increasingly efficient as they scale. To foster further advancement, we provide an open-source library implementing this method, available at https://github.com/thib-s/orthogonium.
ConSim: Measuring Concept-Based Explanations' Effectiveness with Automated Simulatability
Jan 13, 2025



Concept-based explanations work by mapping complex model computations to human-understandable concepts. Evaluating such explanations is very difficult, as it includes not only the quality of the induced space of possible concepts but also how effectively the chosen concepts are communicated to users. Existing evaluation metrics often focus solely on the former, neglecting the latter. We introduce an evaluation framework for measuring concept explanations via automated simulatability: a simulator's ability to predict the explained model's outputs based on the provided explanations. This approach accounts for both the concept space and its interpretation in an end-to-end evaluation. Human studies for simulatability are notoriously difficult to enact, particularly at the scale of a wide, comprehensive empirical evaluation (which is the subject of this work). We propose using large language models (LLMs) as simulators to approximate the evaluation and report various analyses to make such approximations reliable. Our method allows for scalable and consistent evaluation across various models and datasets. We report a comprehensive empirical evaluation using this framework and show that LLMs provide consistent rankings of explanation methods. Code available at https://github.com/AnonymousConSim/ConSim.